DENSE RANK in Data Services

In this article, we will learn how to implement DENSE RANK operation in SAP Data Services.
Implementation
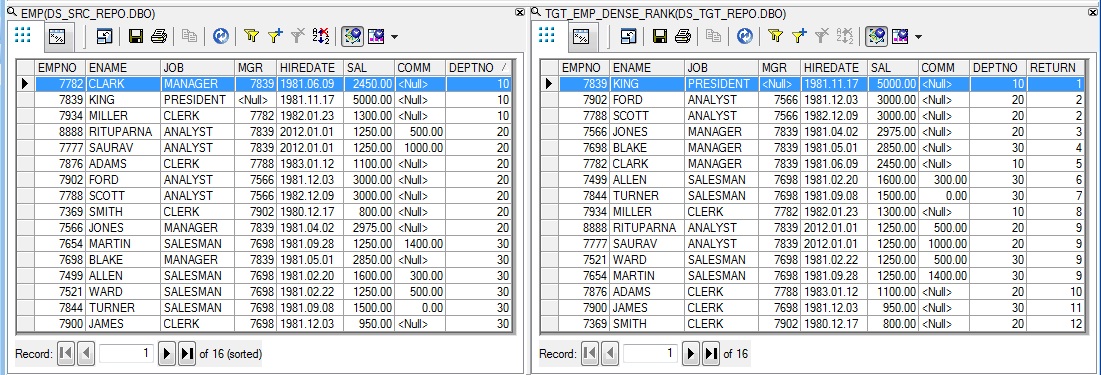
Let us take the Employee table as Source. We want to RANK all the employees based on their salary. So the Employee with the highest salary will get first rank and the employee with lowest salary will get the last rank. Now in the event when many employees have the same salary then they basically share the same rank. But in case of dense ranking the immediate next record will get the next consecutive rank. There will be no gap in RANKS generated.
1. First we create a Batch Job, say Job_Dense_Rank_Generation. Within the Job we create a Data Flow, say Df_Dense_Rank_Generation.
2. Next we create a New Custom Function from the Local Object Library. Let's name it CF_DENSE_RANK_GENERATION.
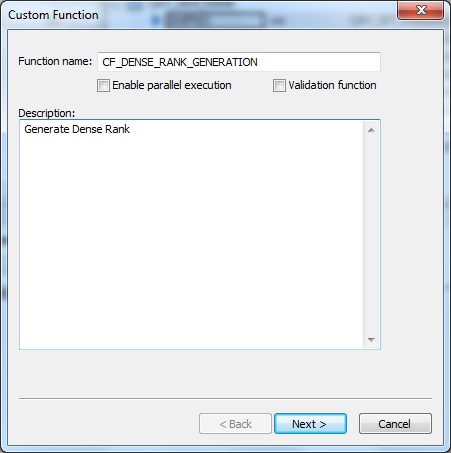
Within the Custom Function Smart Editor, we define the Parameters and Variables as below:
| Param/Variable | Name | Datatype | Type |
| Parameter | Return | int | Output |
| Parameter | $PREV_SAL | decimal(7,2) | Input |
| Parameter | $CURR_SAL | decimal(7,2) | Input |
| Variable | $HOLD_RANK | int |
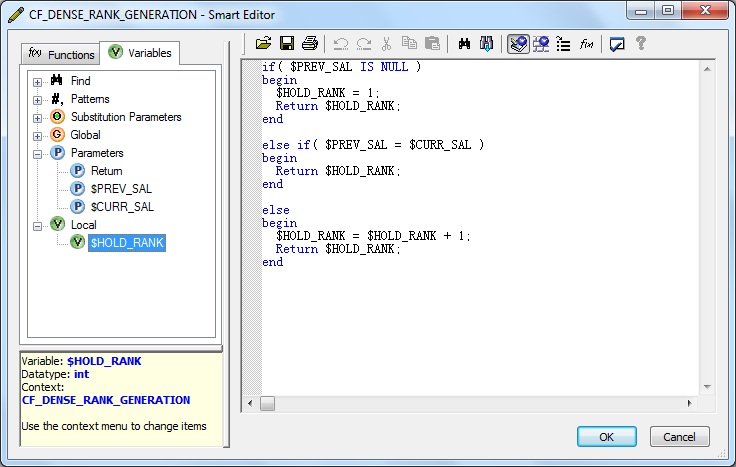
3. Next we define the Custom Function CF_DENSE_RANK_GENERATION as below and Validate the same.
if( $PREV_SAL IS NULL )
begin
$HOLD_RANK = 1;
Return $HOLD_RANK;
end
else if( $PREV_SAL = $CURR_SAL )
begin
Return $HOLD_RANK;
end
else
begin
$HOLD_RANK = $HOLD_RANK + 1;
Return $HOLD_RANK;
end4. Let's go back and design the Dataflow. First of all we take the EMP table, from the Local Object Library as Source.

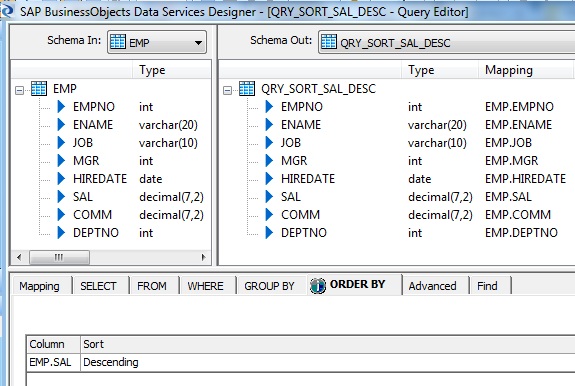
5. Next we place a Query transform, say QRY_SORT_SAL_DESC to sort the employee data based salary in descending order. First we select all the columns from the Schema In of the Query transform and Map to Output. Next on the ORDER BY tab, select the EMP.SAL column of the Schema In and Sort Type as Descending
6. Next we place another Query transform, say QRY_SET_PARAM to set the Parameter values that will passed as arguments to the Custom Function to get the Ranking. First we select all the columns from the Schema In of the Query transform and Map to Output. Next we create a New Output Column, say PREV_SAL with Data type as decimal(7,2) to capture the previous row value of salary and define the Mapping as below:
previous_row_value( QRY_SORT_SAL_DESC.SAL )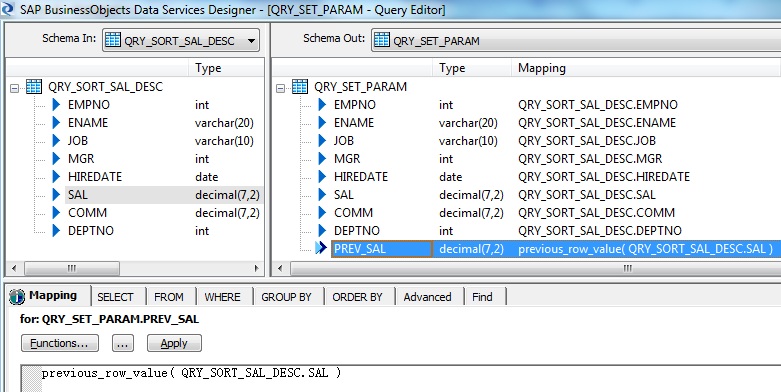
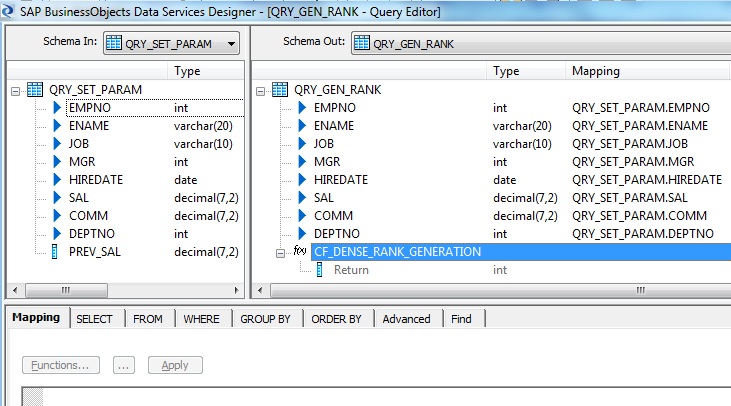
7. Next we place another Query transform, say QRY_GEN_RANK to call the Custom Function with the input parameters that we have already designed in the previous transform. First we select all the columns except PREV_SAL from the Schema In of the Query transform and Map to Output. Call the Function with the Input Parameters as below. This function will eventually return the Rank for each record based on the salary.
Create a New Function Call in Schema Out of the Query transform. Choose the Custom Functions from the Function categories and select the Function name CF_DENSE_RANK_GENERATION.
Next we Define Input Parameters. We specify the inputs as below:
$PREV_SAL = QRY_SET_PARAM.PREV_SAL
$CURR_SAL = QRY_SET_PARAM.SAL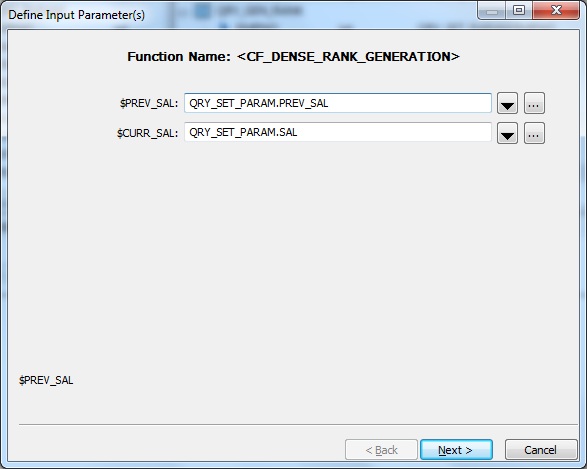
Select the Return column as the Output Parameter.
8. Finally we place a Template Table as Target in the Target Datastore.