
Create Amazon EMR Cluster


With Amazon EMR we can set up & launch a cluster to process and analyze data with various big data frameworks very easily.
Navigate to Amazon EMR homepage. Next click on the Clusters link under the EMR on EC2 section. Click on the Create cluster button.
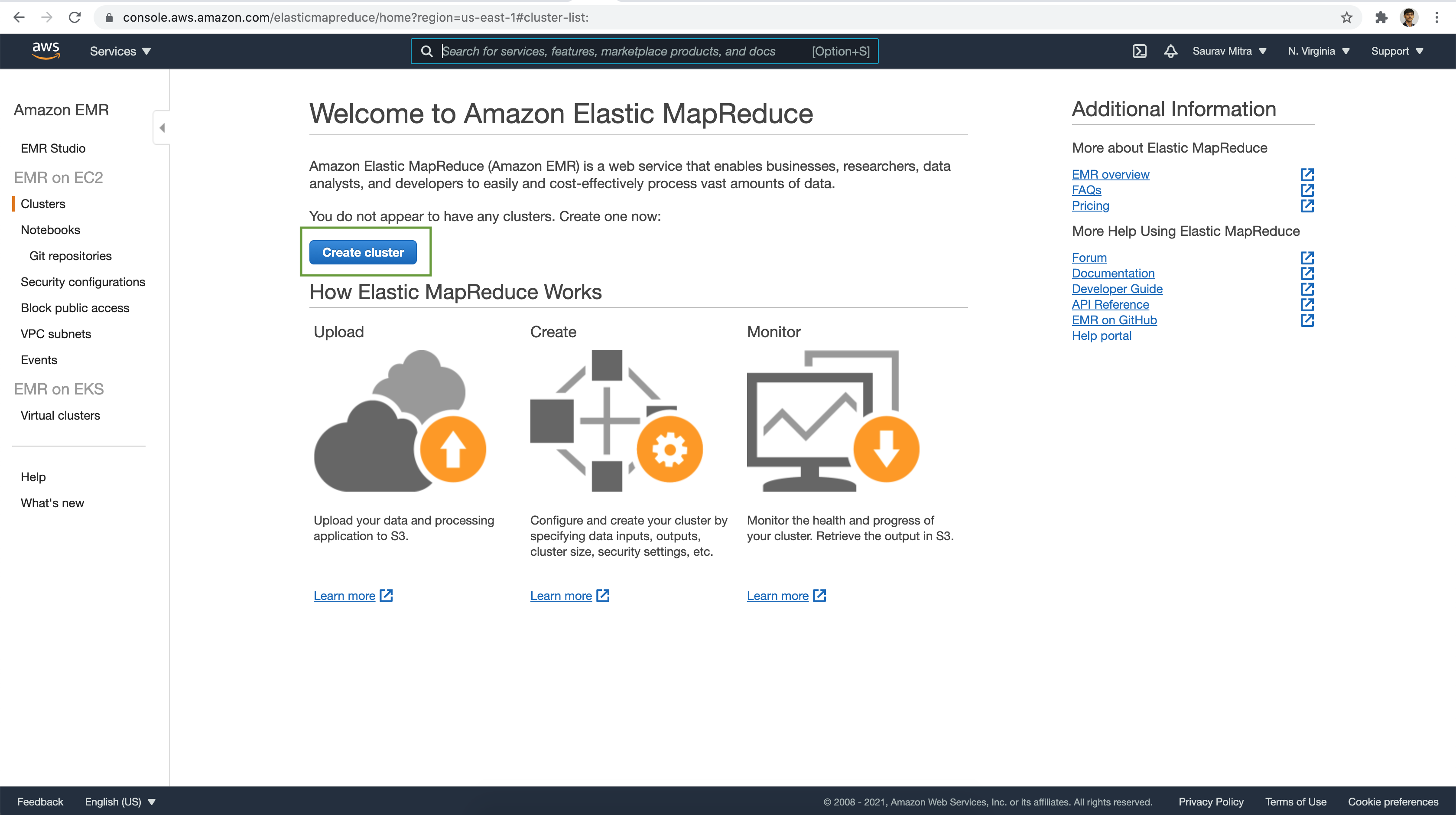
It brings us to the EMR quick create page. Next, click on the Go to advanced options link.
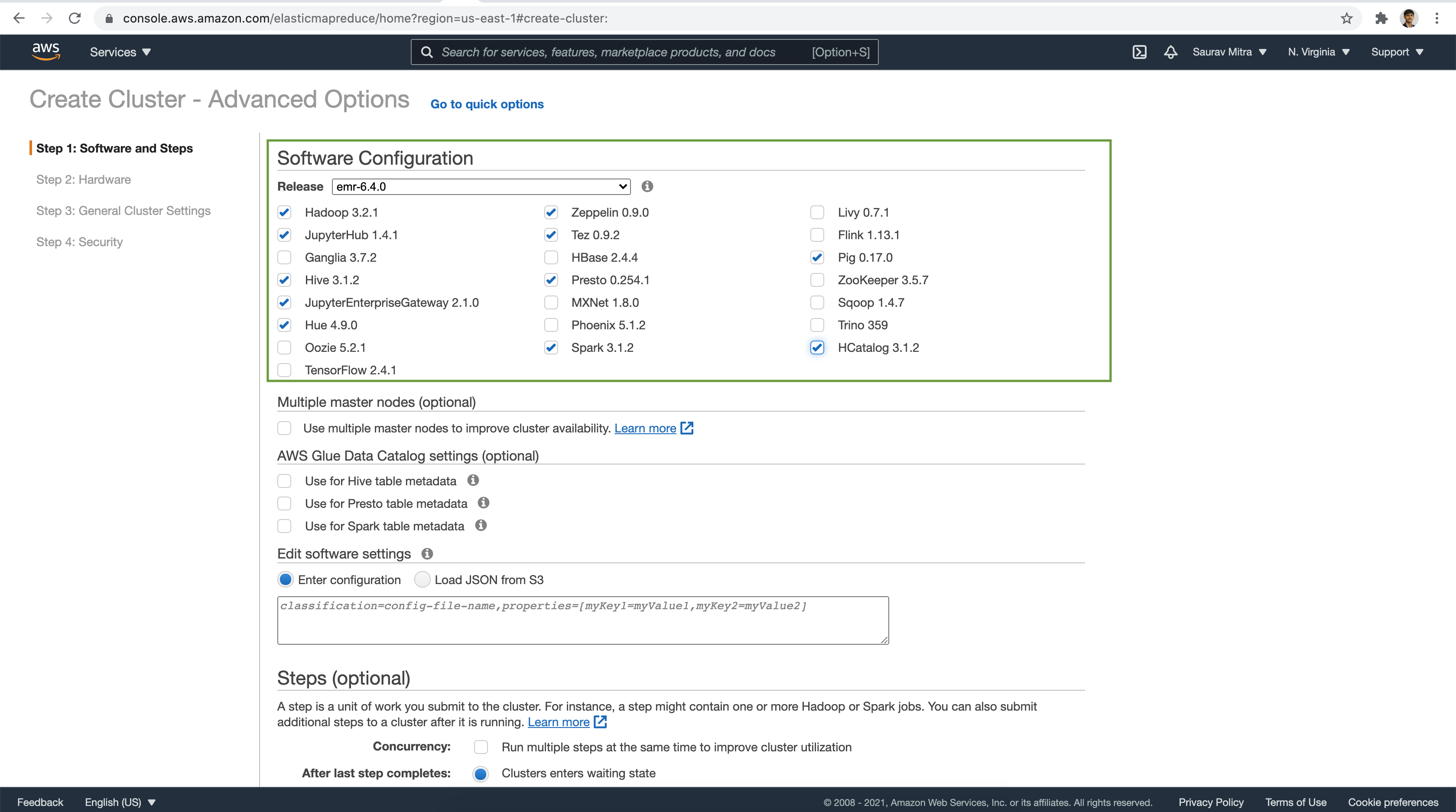
Under the Software Configuration, let us choose from many of the available big data frameworks.
For the purpose of demo in our next articles, let choose the below frameworks:
- Hadoop: Cluster for distributed processing of big data
- Hive: Distributed data warehouse system on top of Hadoop
- HCatalog: Allows to access Hive Metastore tables and storage management layer from various data processing frameworks
- Pig: Scripting language to transform large data sets
- Tez: Data processing framework for creating a complex directed acyclic graph (DAG) of tasks. Pig and Hive workflows can run using Hadoop MapReduce or they can use Tez as an execution engine
- Spark: Distributed processing framework and programming model for machine learning, stream processing, or graph analytics
- Presto: In-Memory Distributed SQL Query Engine for interactive analytic queries over large datasets from multiple sources
- Jupyter: Provides a development and collaboration environment for ad hoc querying and exploratory analysis
- Zeppelin: Notebook for interactive data exploration
- Hue: Web-based, graphical user interface for use with Hadoop & Amazon EMR
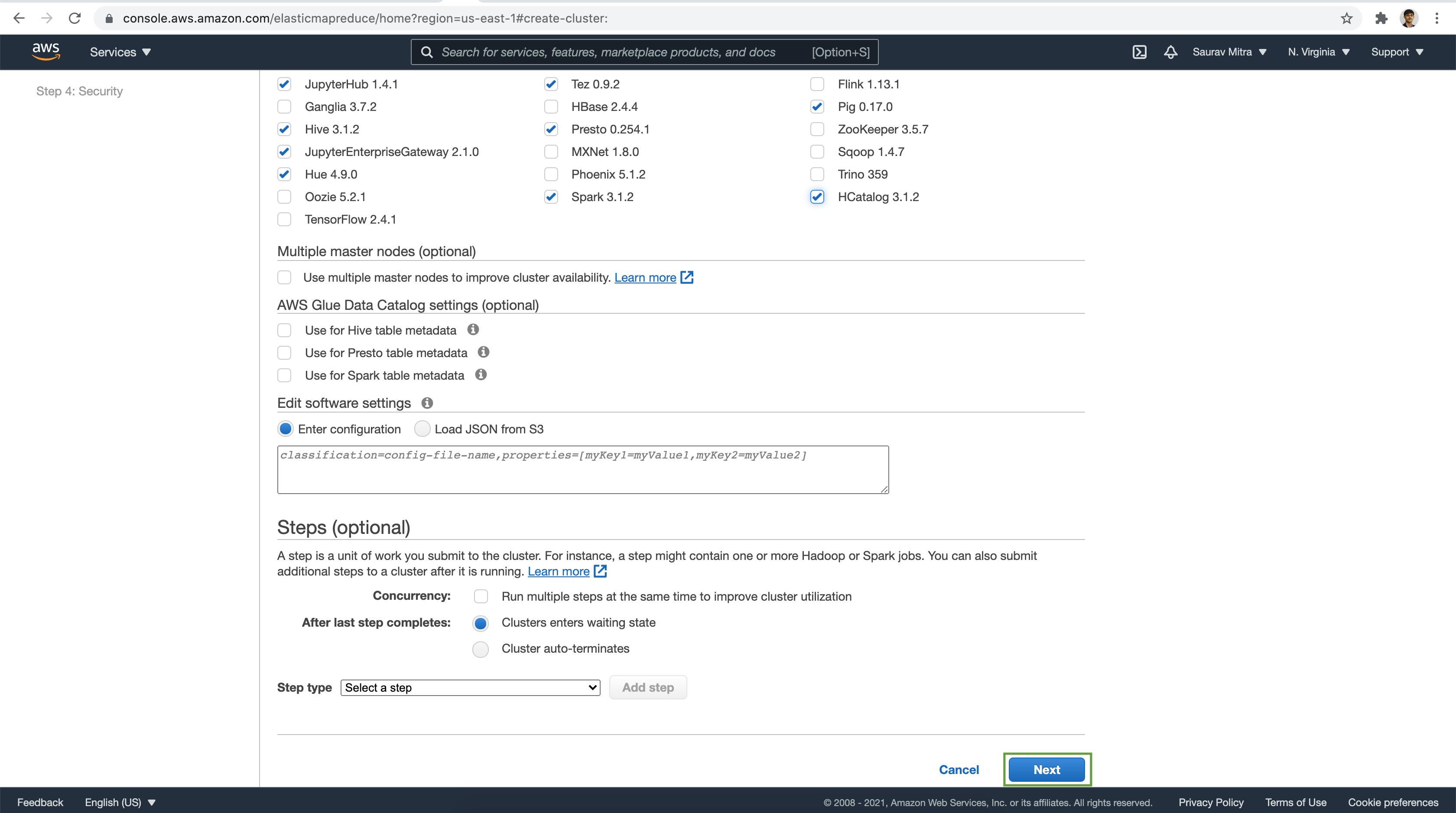
For the demo we are not going to add any Step Job during EMR launch. Once the EMR cluster launch is successful. It will be available in Waiting state.
Select the VPC & a Subnet to launch the EMR Cluster.
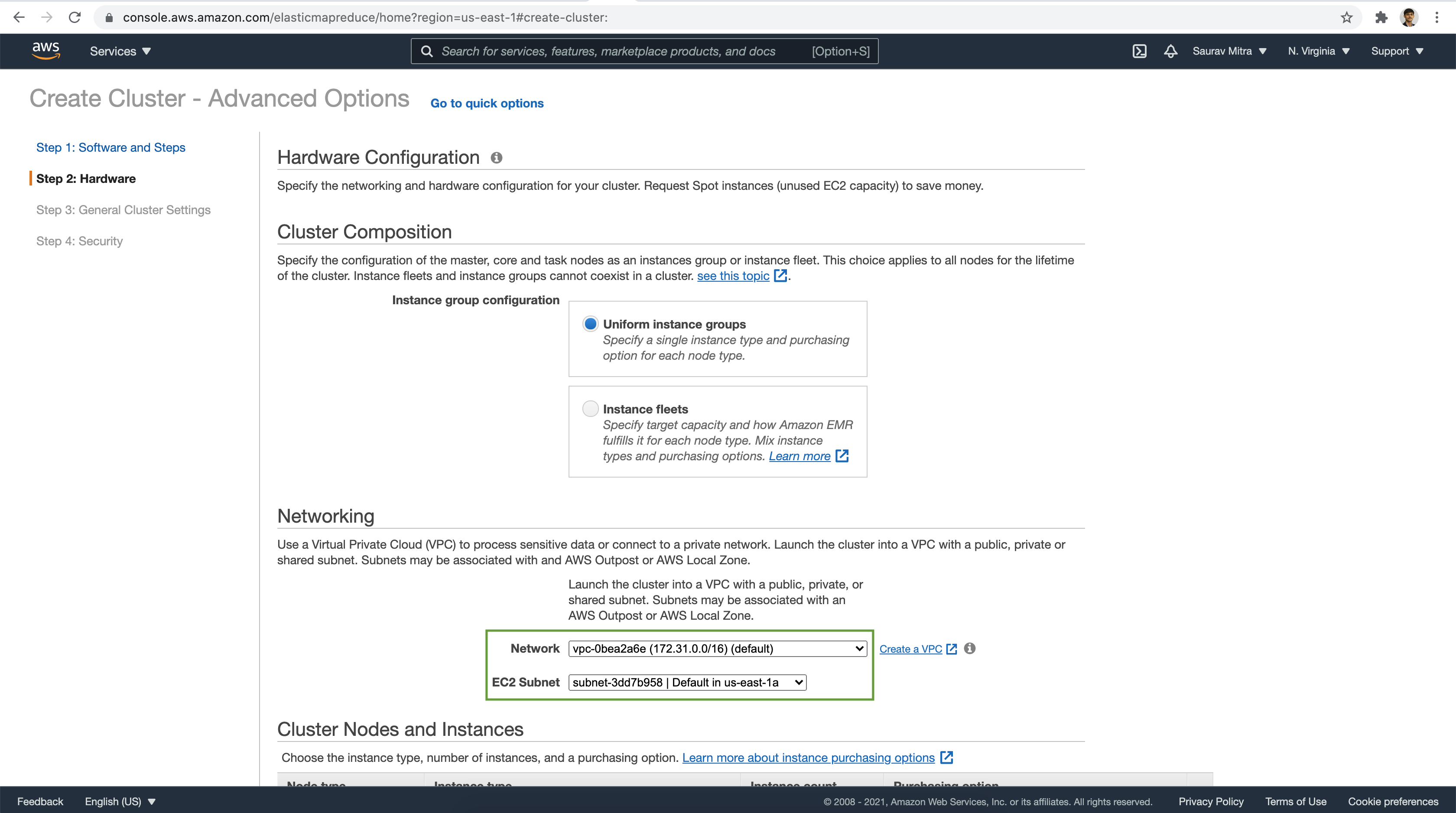
Choose the number of Nodes & Instance Types.
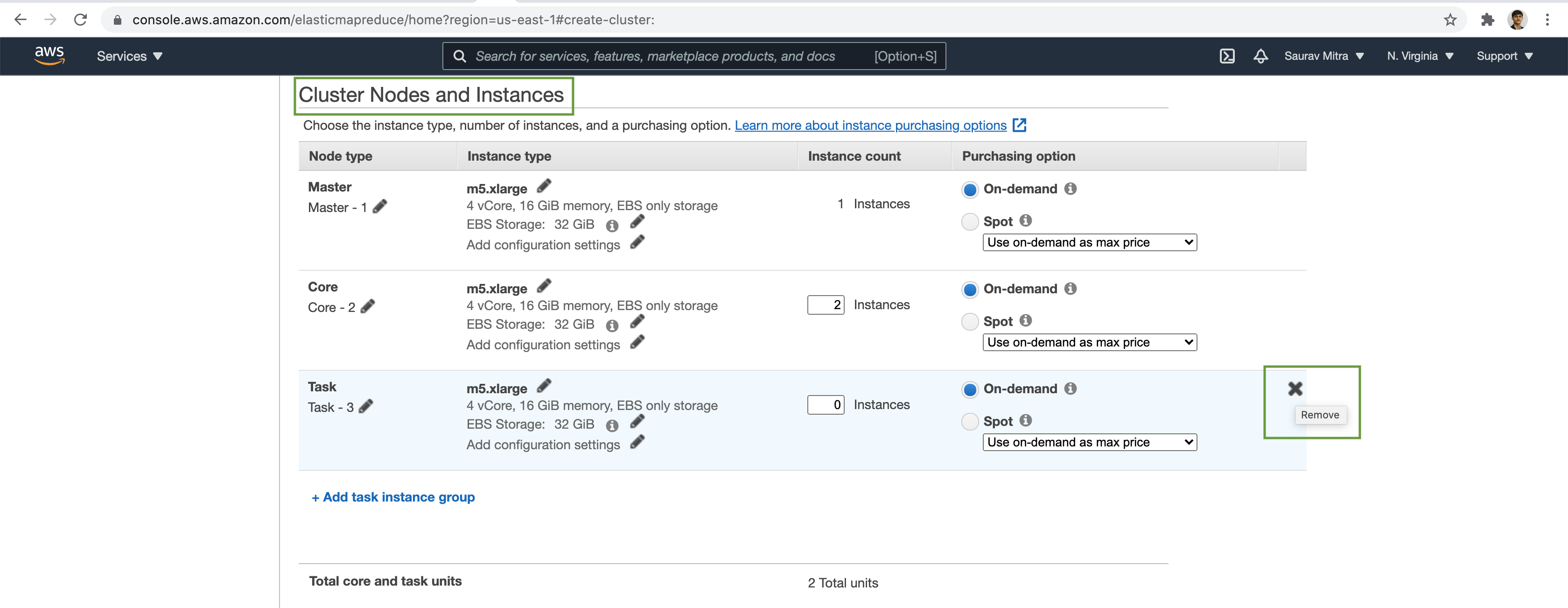
Lets disable Cluster auto scaling for this demo. Also we will disable the EMR cluster Auto-termination feature.
Next choose the EBS Root Volume size for all the Nodes.
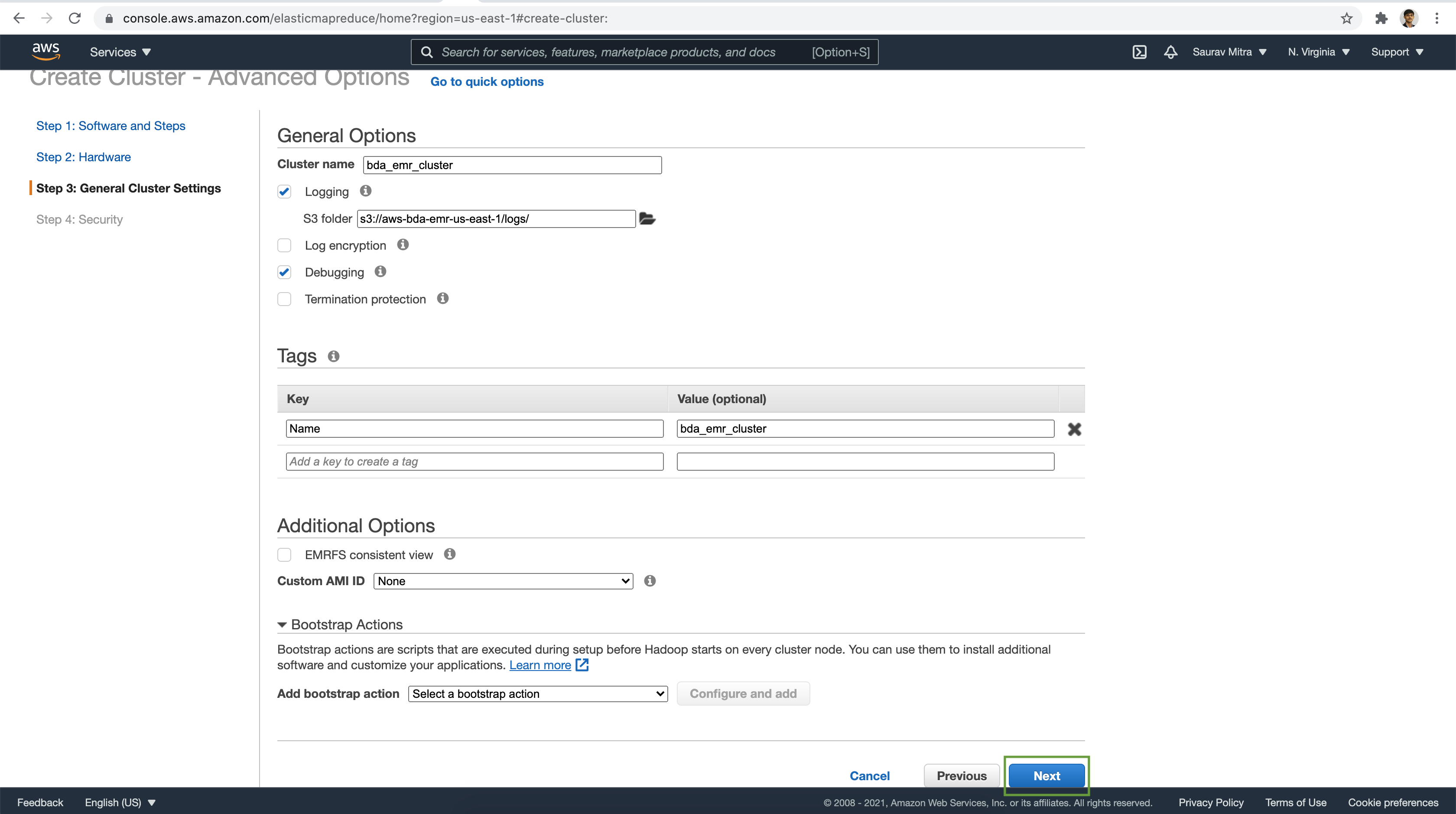
Enter the EMR Cluster Name. Choose existing S3 bucket for EMR Cluster logging. Also let's enable Debugging. Enable Debugging will add a EMR Step job.
Let's select the EC2 key-pair for all the EC2 instances provisioned as part of EMR cluster.
Select the IAM Roles for the EMR Cluster.
Select the EC2 security groups for the Master & Core Nodes.
Finally click on the Create cluster button. It will take few minutes to launch the EMR cluster.
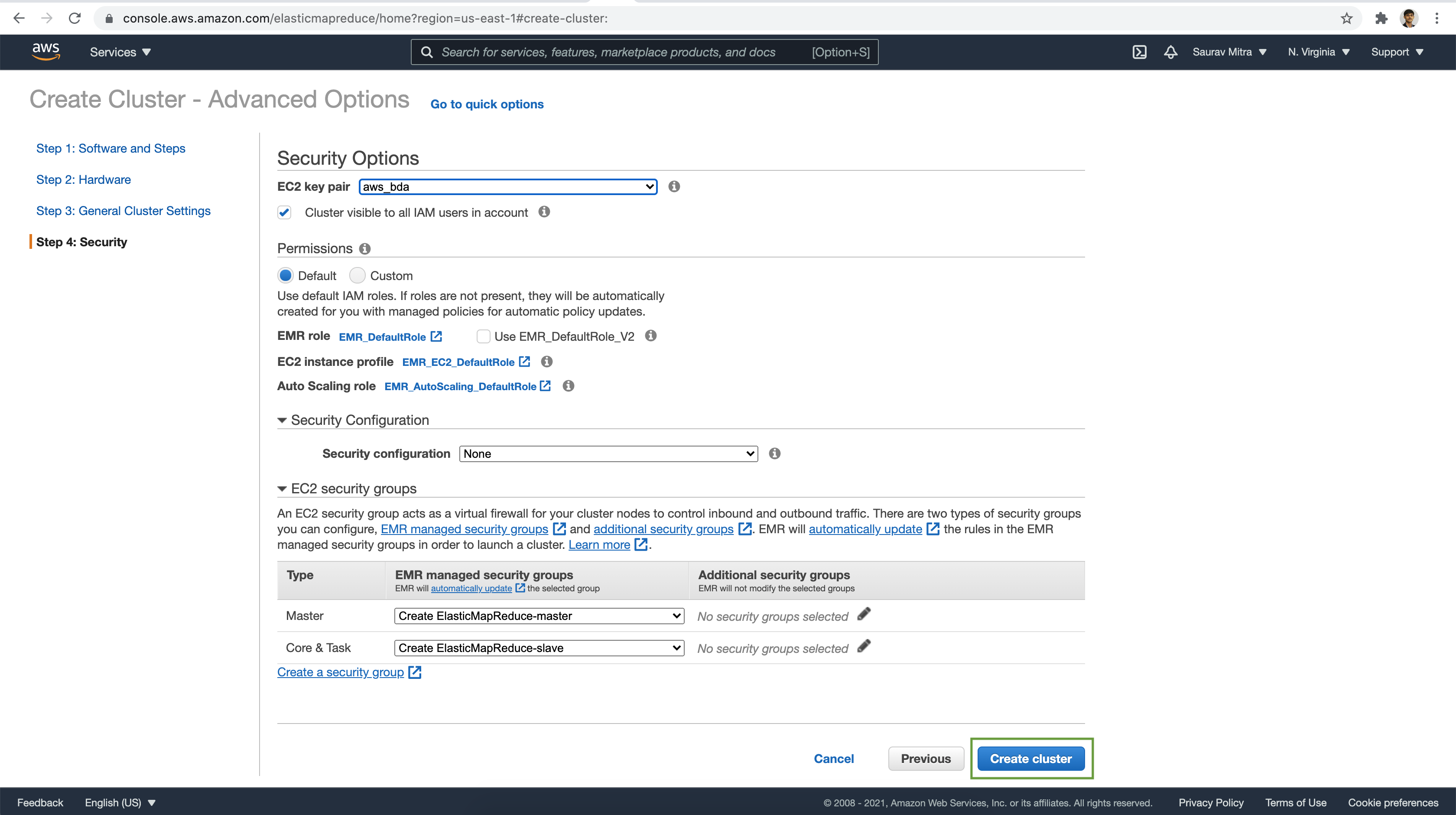
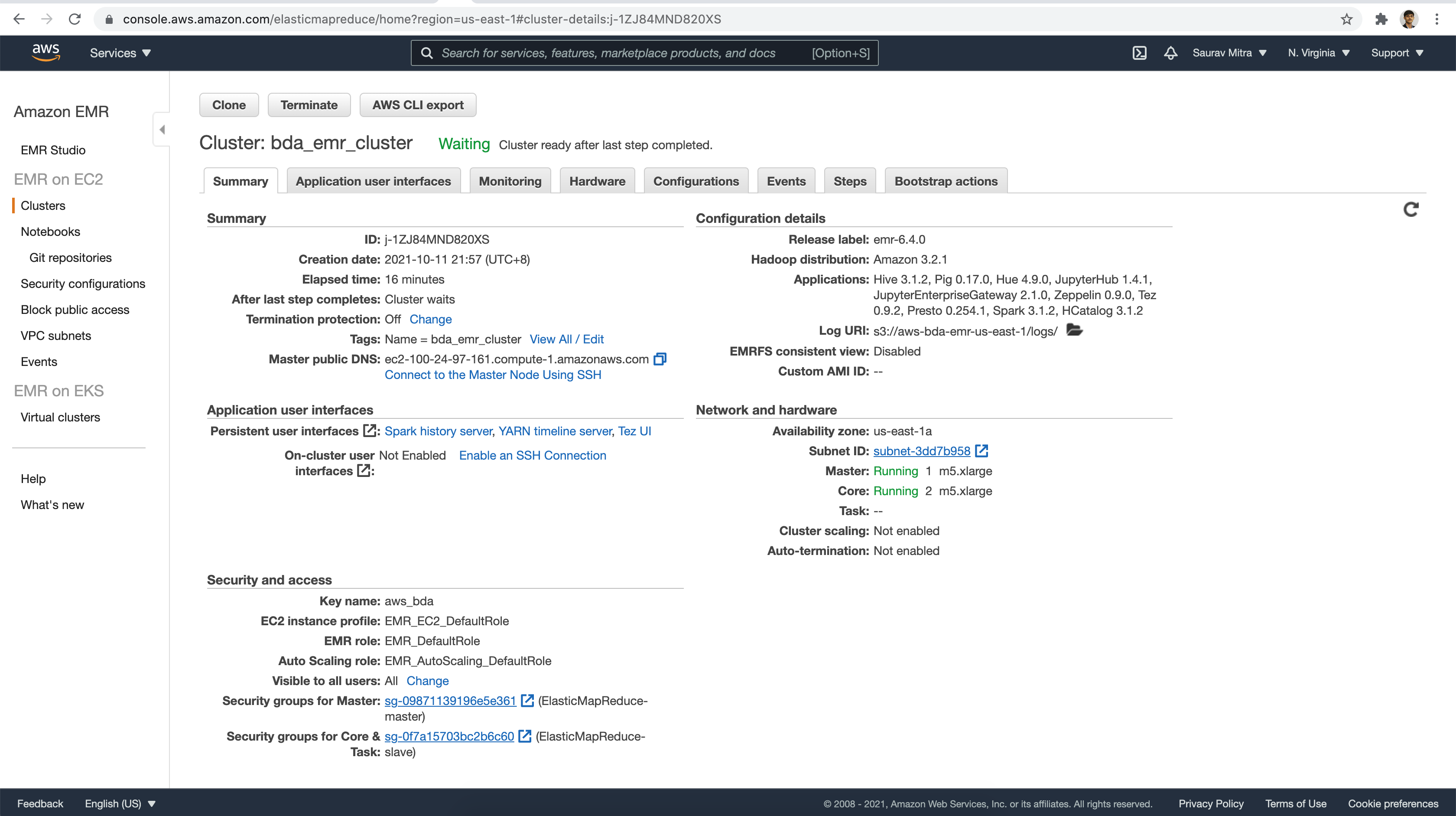
Finally the EMR Cluster launch is successful and the clusters enters into Waiting ready state.
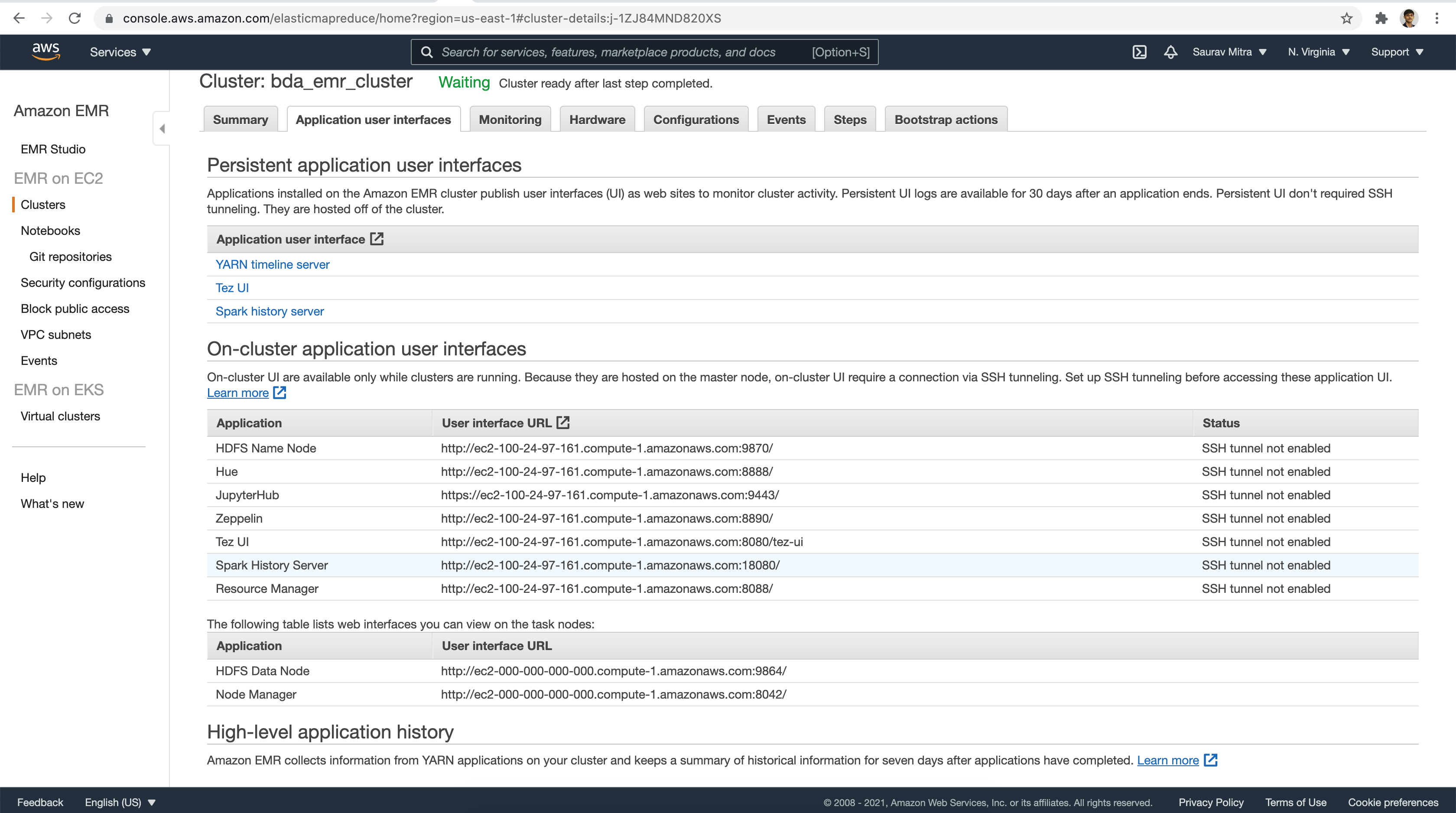
Let's take a look under the Application user interfaces tab. As part of the various big-data frameworks we selected earlier, the corresponding UI links are available.
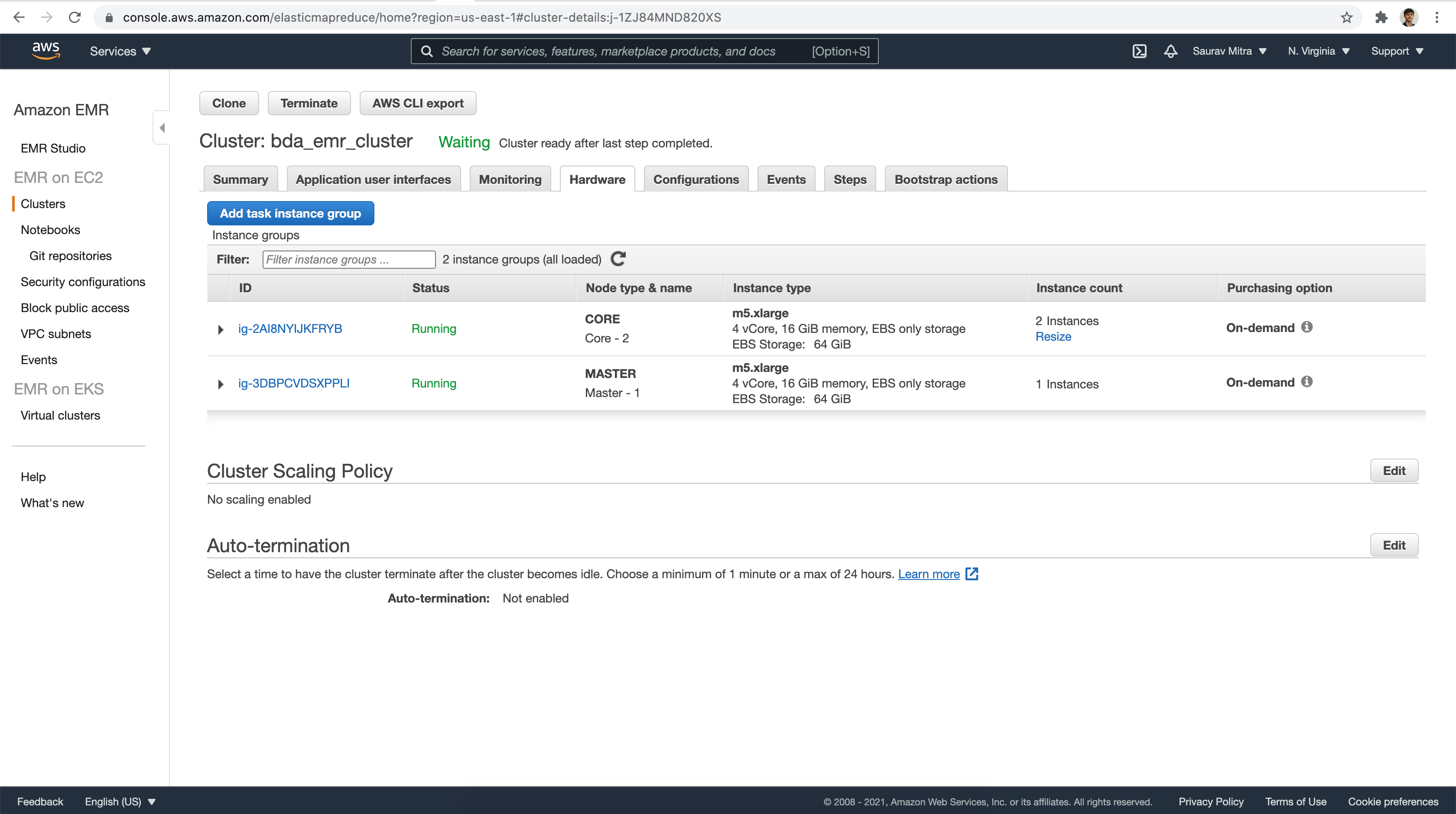
Let's take a look under the Hardware tab. Here we will see the Node groups & the instances.
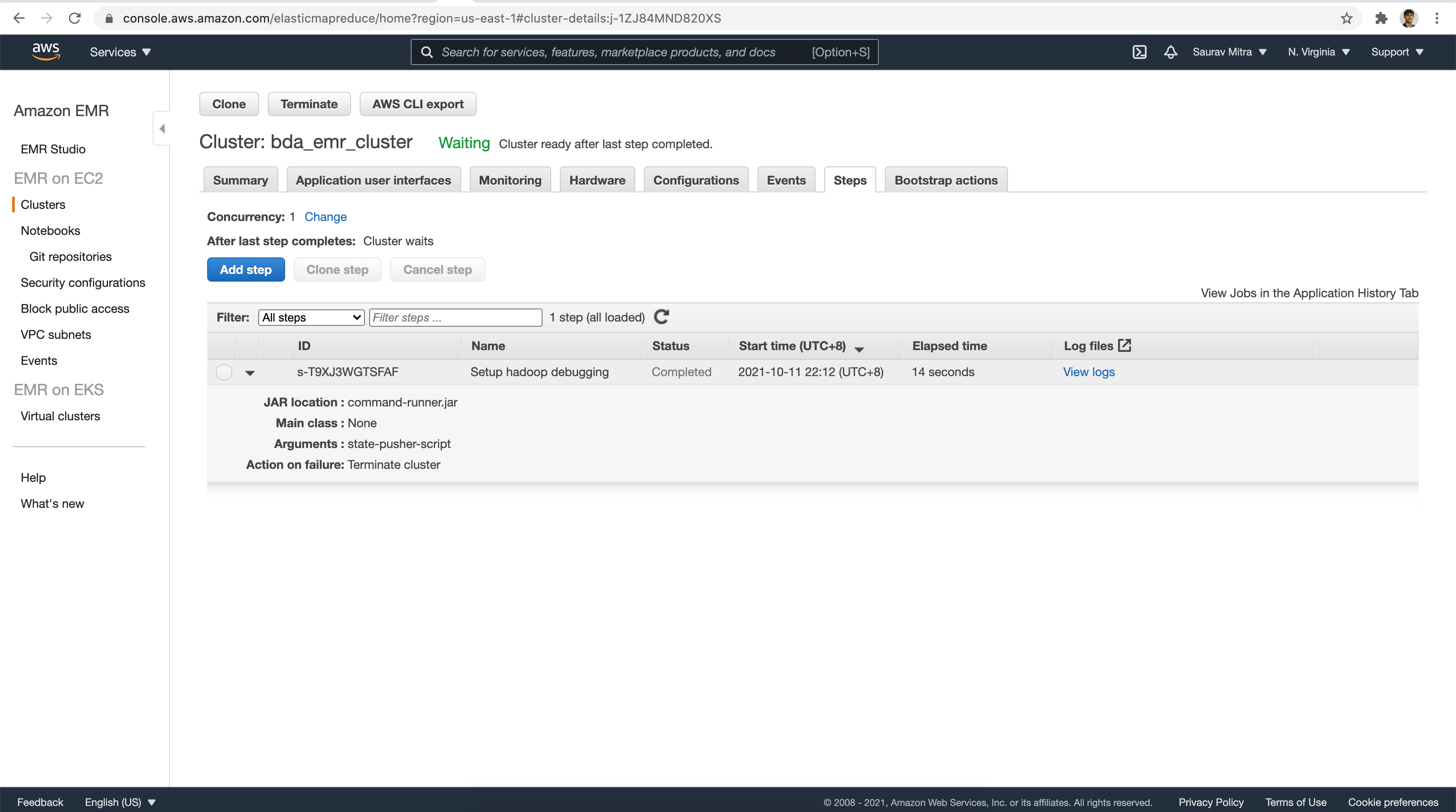
Finally take a look under the Steps tab. As we enabled debugging we see a very first Step Job that was executed as part of EMR Cluster launch.
In our next article we will check how to submit data processing jobs to an EMR cluster. Also we will check on few of the big-data frameworks like Presto, Jupyter, Zeppelin etc.
