
Streaming Data Analytics with Amazon Kinesis


In today's fast-paced digital landscape, processing and analyzing real-time data streams is crucial for timely decision-making. Amazon Kinesis, a robust data streaming service, facilitates this by collecting, processing, and analyzing streaming data. This article demonstrates how to set up and utilize Amazon Kinesis for real-time analytics using Twitter as a data source.
As an use-case we are going to collect, process & analyze, streaming Twitter tweets in real-time and finally save the datasets in S3 Data lake bucket.
Setting up Twitter Application
Go to https://developer.twitter.com/en/portal/projects-and-apps. Under the Standalone Apps section, click on + Create App button to create a new Twitter application. Add an App name & click Next button.
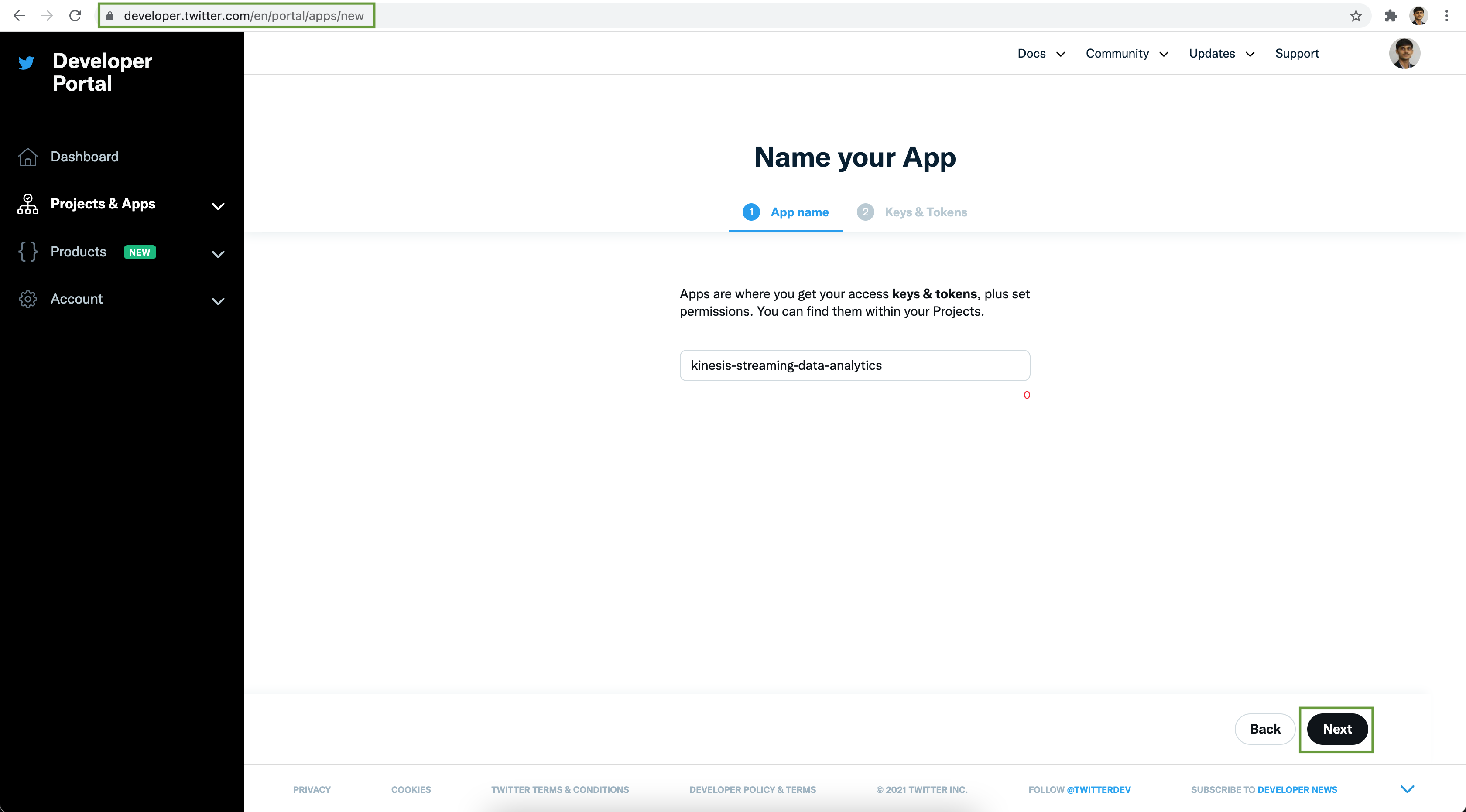
Save the API Key & API Key Secret securely. Next click on the App settings button
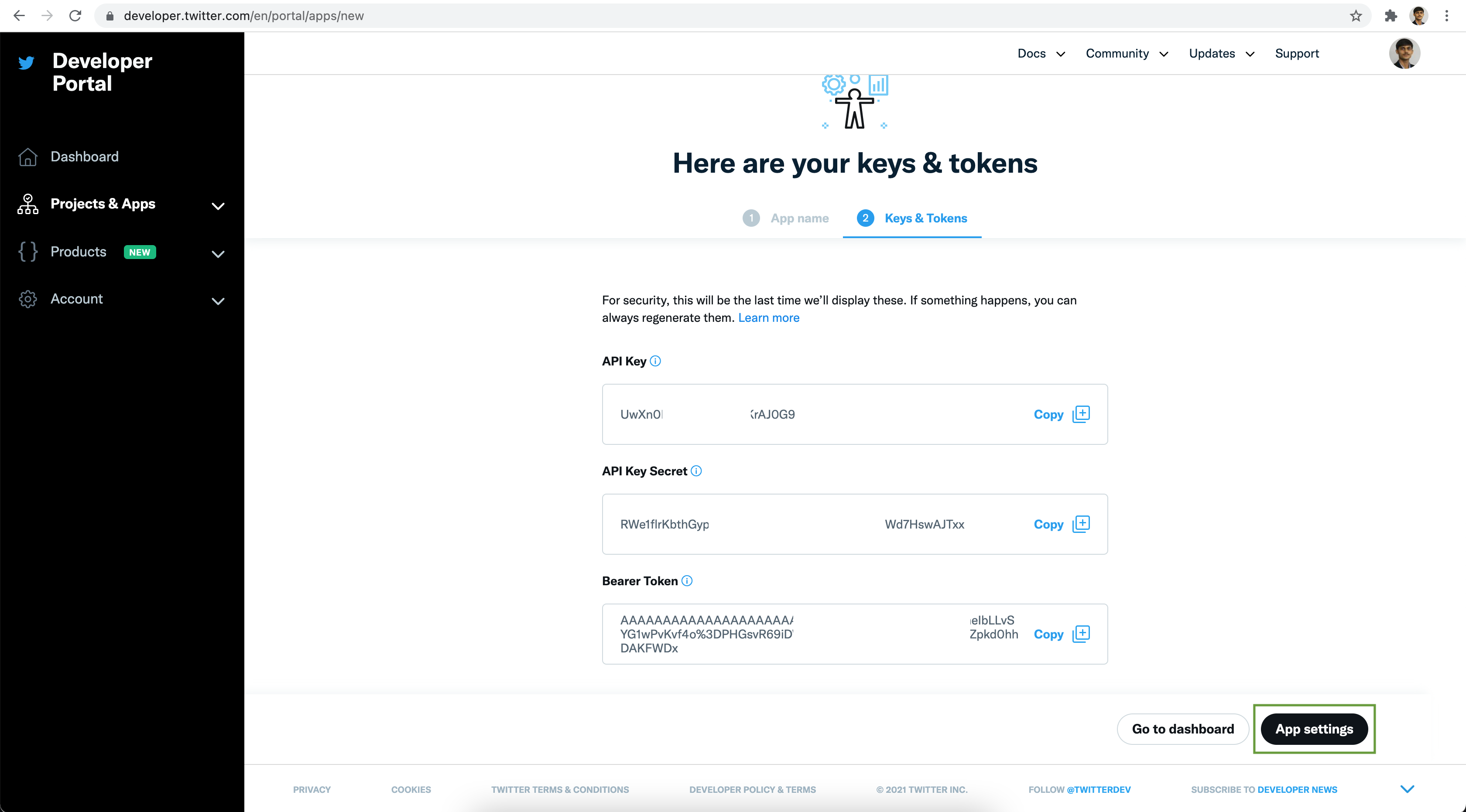
To read streaming tweets from Twitter, the Read Only App permission is good enough.
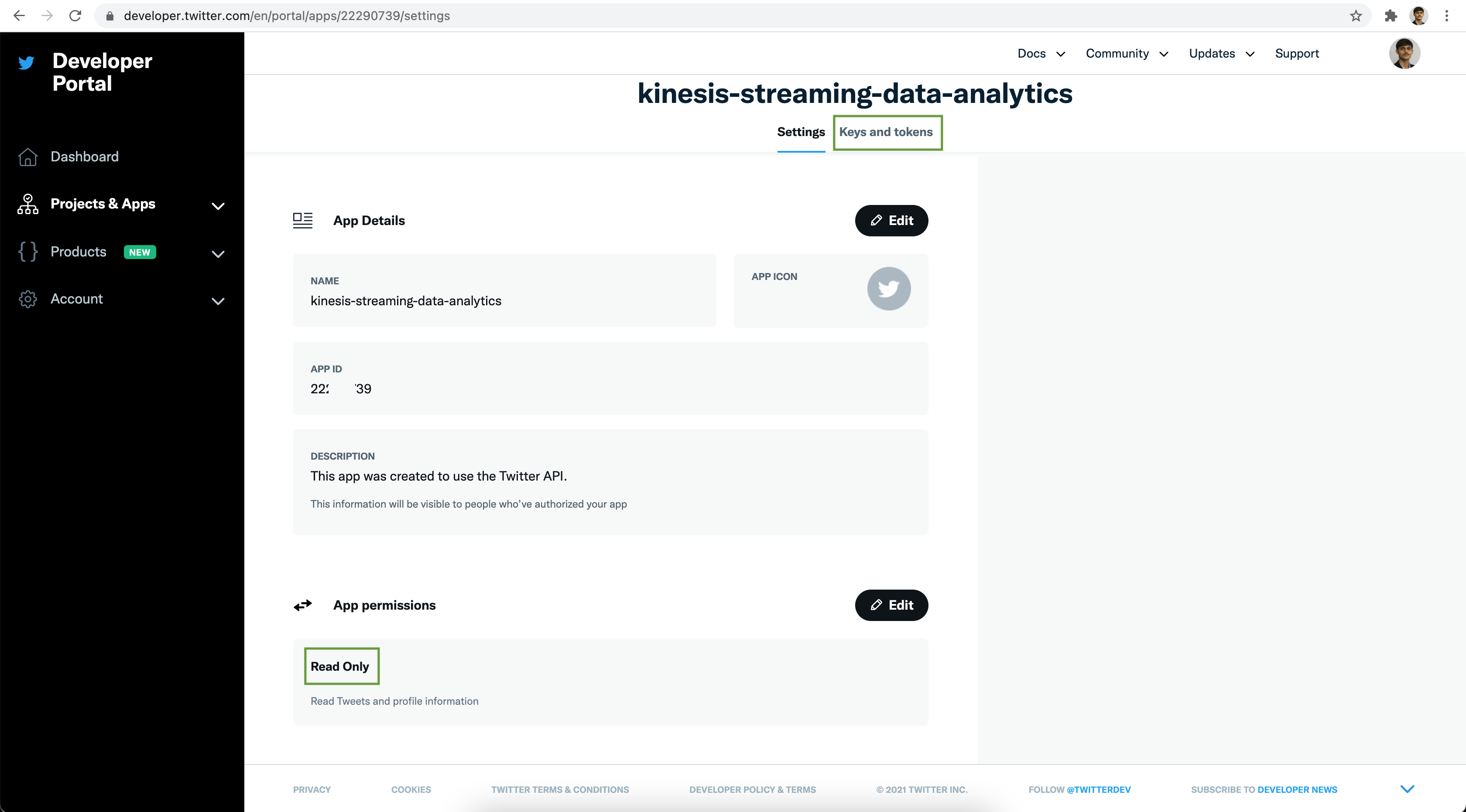
Next click on the Keys and token tab. Under the Authentication Tokens section
click on the Generate Access Token and Secret button.
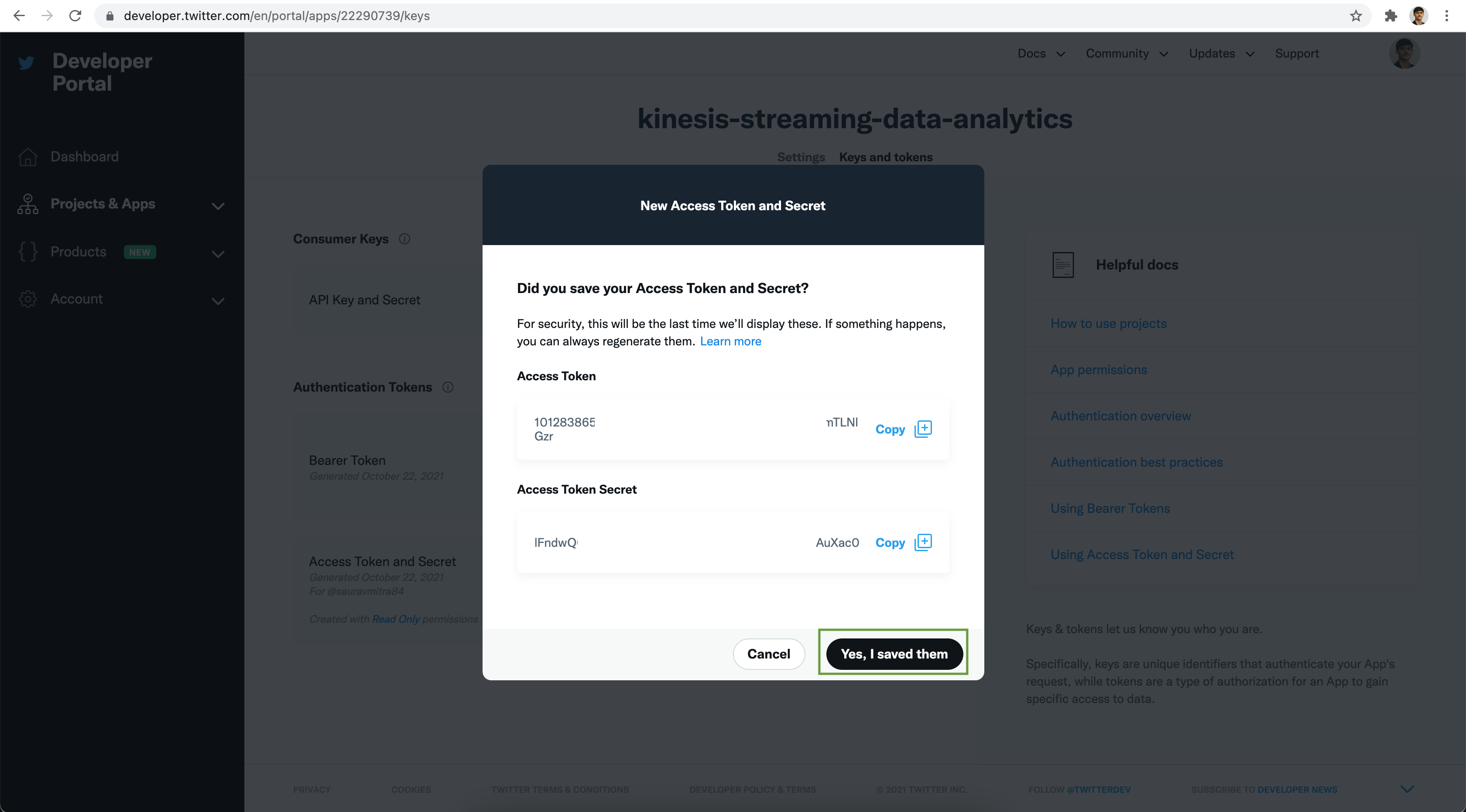
Save the Access Token & Access Token Secret securely. Next click on the Yes, I saved them button.
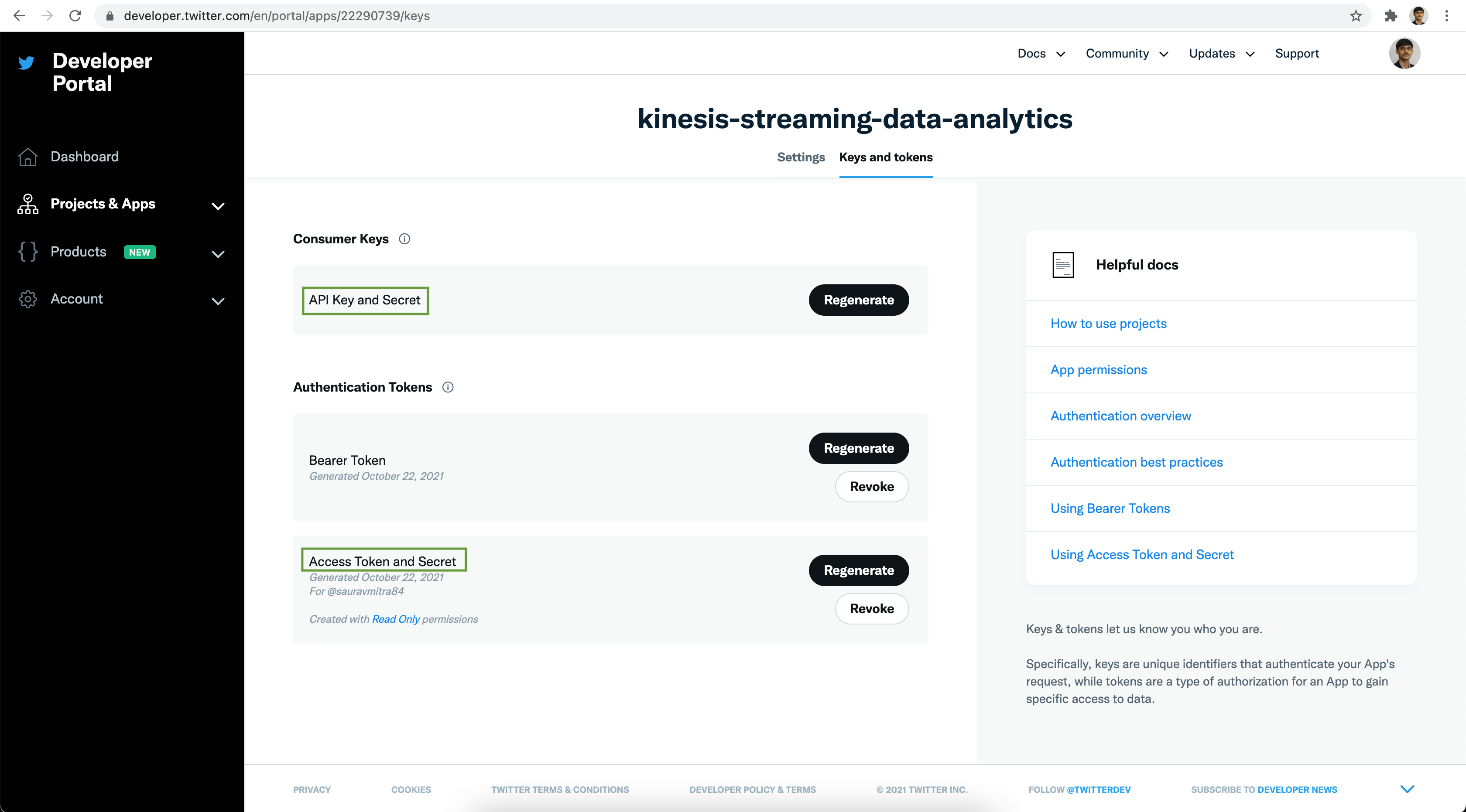
You can Regenerate the API Key, API Key Secret, Access Token & Access Token Secret anytime as per your need. Now we are all set with the Twitter App part.
Configuring Amazon Kinesis
Now let's go to AWS console and go to Kinesis Services. First of all we will create a data stream to collect & store the tweets. Click on the Create data stream button.
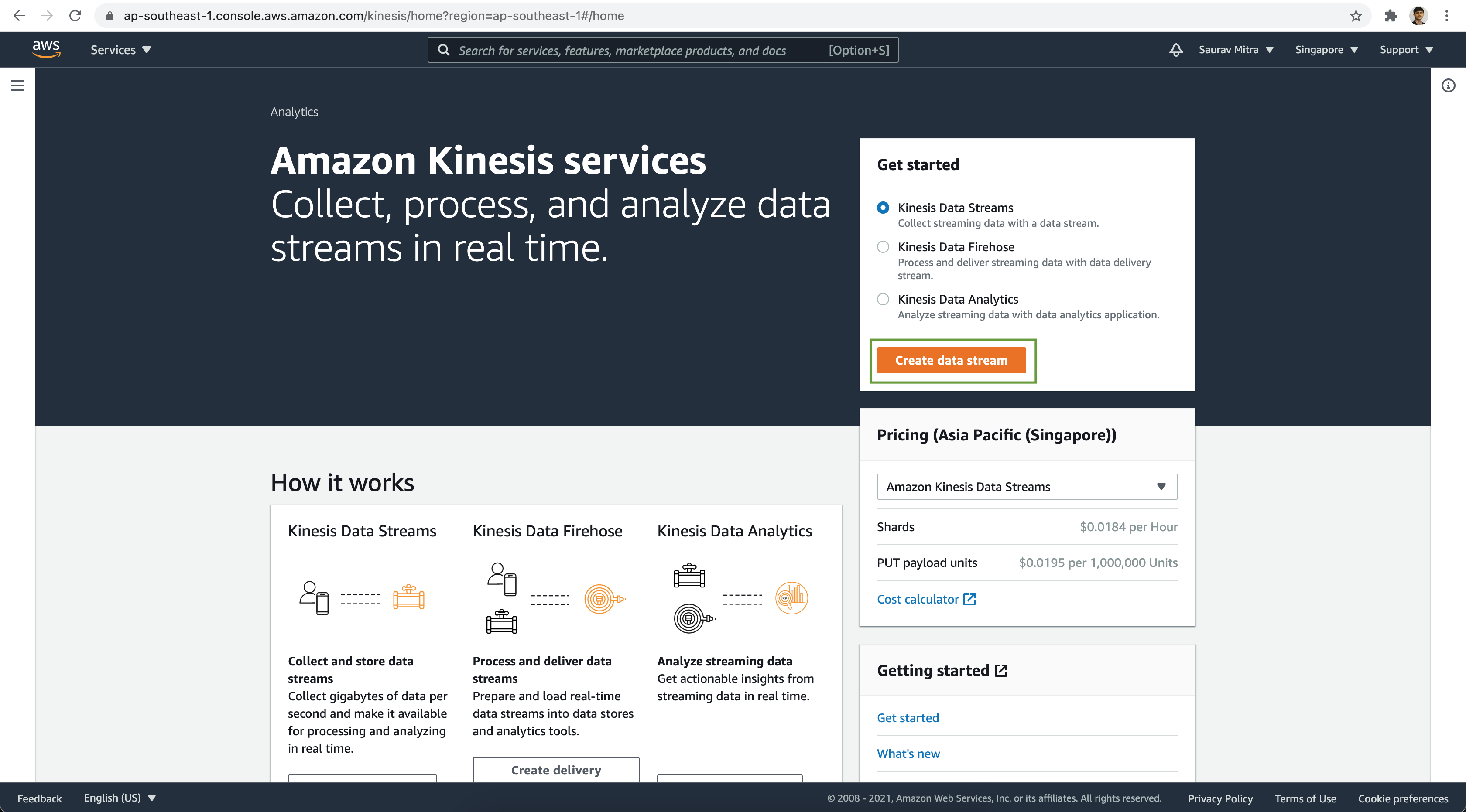
Create a Kinesis Data Stream
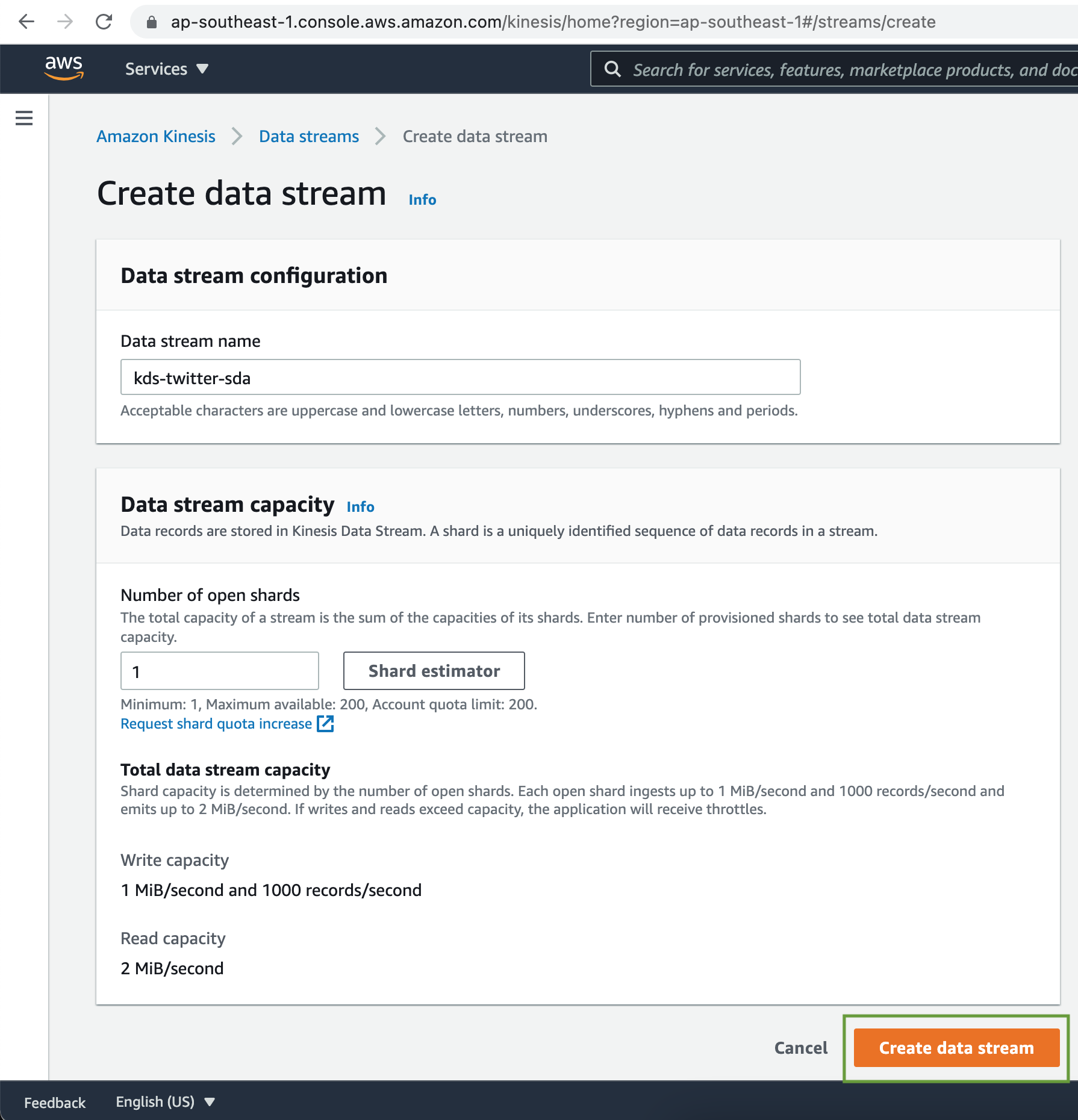
Add a name for the Kinesis Data Stream. For the Data stream capacity, we will go with 1 shard only, for this demo. Next click on the Create data stream button.
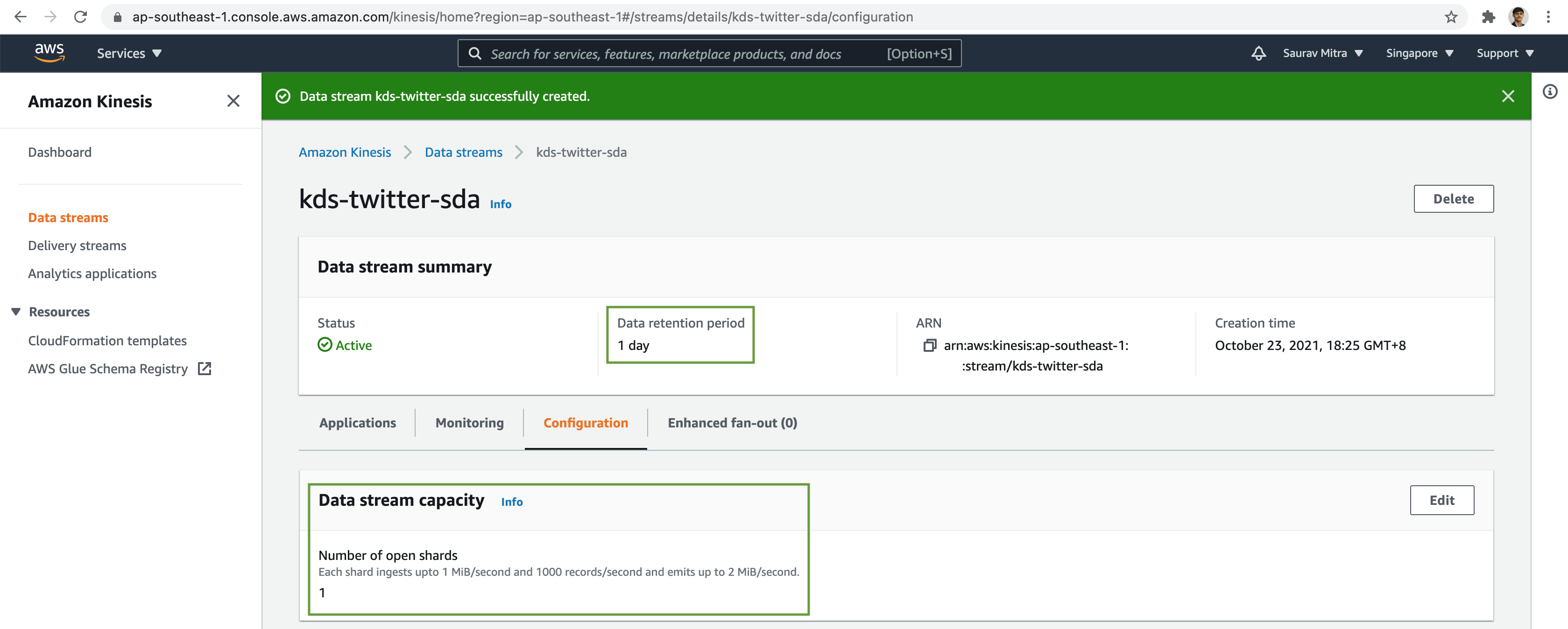
The Kinesis Data Stream was successfully created with 1 shard & the default data retention period is 1 day.
Python Script for Data Collection
Next we will use a python script to collect streaming data from Twitter & forward the tweets to the Kinesis Data Stream shard.
tweets.py
import boto3
import json
import os
import tweepy
import uuid
consumer_key = os.environ['CONSUMER_KEY']
consumer_secret = os.environ['CONSUMER_SECRET']
access_token = os.environ['ACCESS_TOKEN']
access_token_secret = os.environ['ACCESS_TOKEN_SECRET']
kinesis_stream_name = 'kds-twitter-sda'
twitter_filter_tag = '#Covid19'
class StreamingTweets(tweepy.Stream):
def on_status(self, status):
data = {
'tweet_text': status.text,
'created_at': str(status.created_at),
'user_id': status.user.id,
'user_name': status.user.name,
'user_screen_name': status.user.screen_name,
'user_description': status.user.description,
'user_location': status.user.location,
'user_followers_count': status.user.followers_count,
'tweet_body': json.dumps(status._json)
}
response = kinesis_client.put_record(
StreamName=kinesis_stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
print('Status: ' +
json.dumps(response['ResponseMetadata']['HTTPStatusCode']))
def on_error(self, status):
print(status)
session = boto3.Session()
kinesis_client = session.client('kinesis')
partition_key = str(uuid.uuid4())
stream = StreamingTweets(
consumer_key, consumer_secret,
access_token, access_token_secret
)
stream.filter(track=[twitter_filter_tag])requirements.py
# Python Packages
boto3
tweepyInstall the python dependency packages, setup the environment variables add finally execute the python script.
pip3 install -r requirements.txt -t ./
export AWS_ACCESS_KEY_ID="...."
export AWS_SECRET_ACCESS_KEY="...."
export AWS_DEFAULT_REGION="ap-southeast-1"
export CONSUMER_KEY='....'
export CONSUMER_SECRET='....'
export ACCESS_TOKEN='....'
export ACCESS_TOKEN_SECRET='....'
python tweets.pySetting Up Kinesis Data Firehose
Next click on the Delivery streams link. Now we will first deliver the raw tweets to staging S3 data lake bucket. Click on the Create delivery stream button.
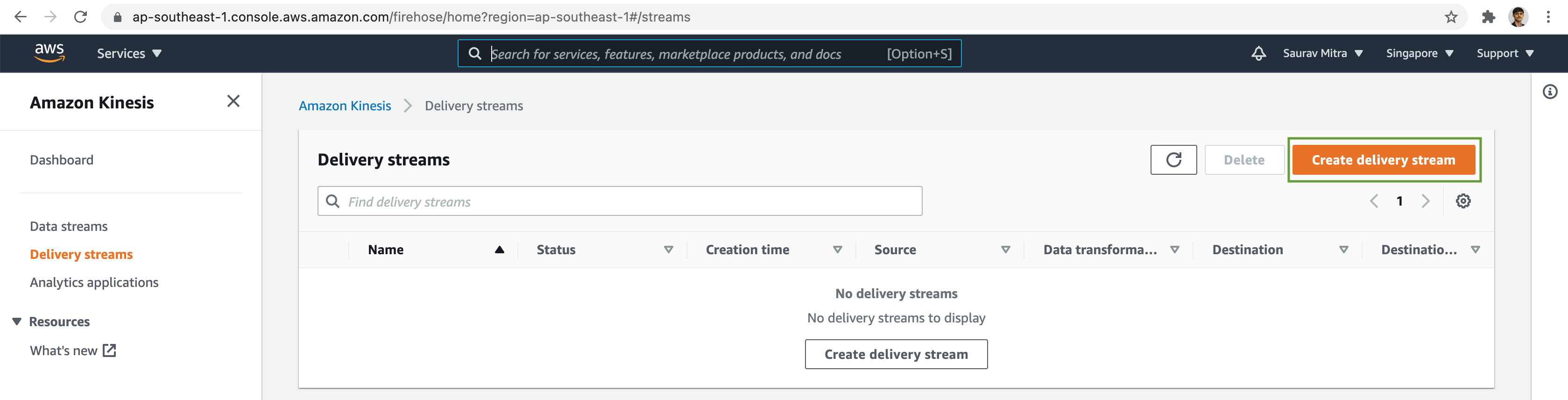
Our Source for the streaming data will be the Amazon Kinesis Data Stream & the destination will be Amazon S3 bucket.
Under the Source settings, click on the Browse button & Choose the Kinesis data stream we created earlier.
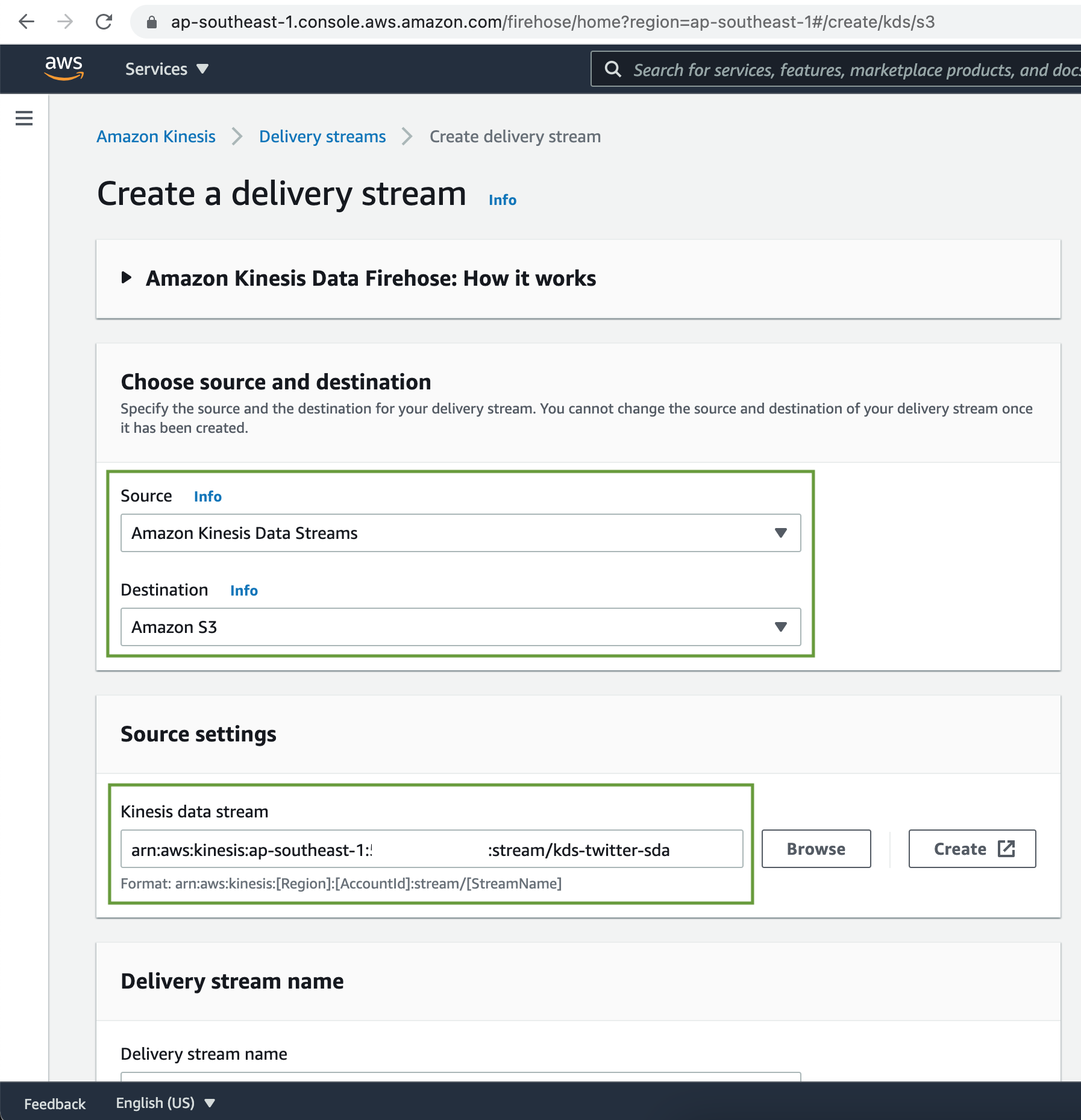
Add a name for our Delivery Stream. There is provision to perform pre processing of source records using Lambda function. Also if the dataset is meant for analysis in Data lake, Delivery Stream has provision to convert the source record format to Apache Parquet or ORC.
For this demo we are not going to perform any data transformation & record format conversion.
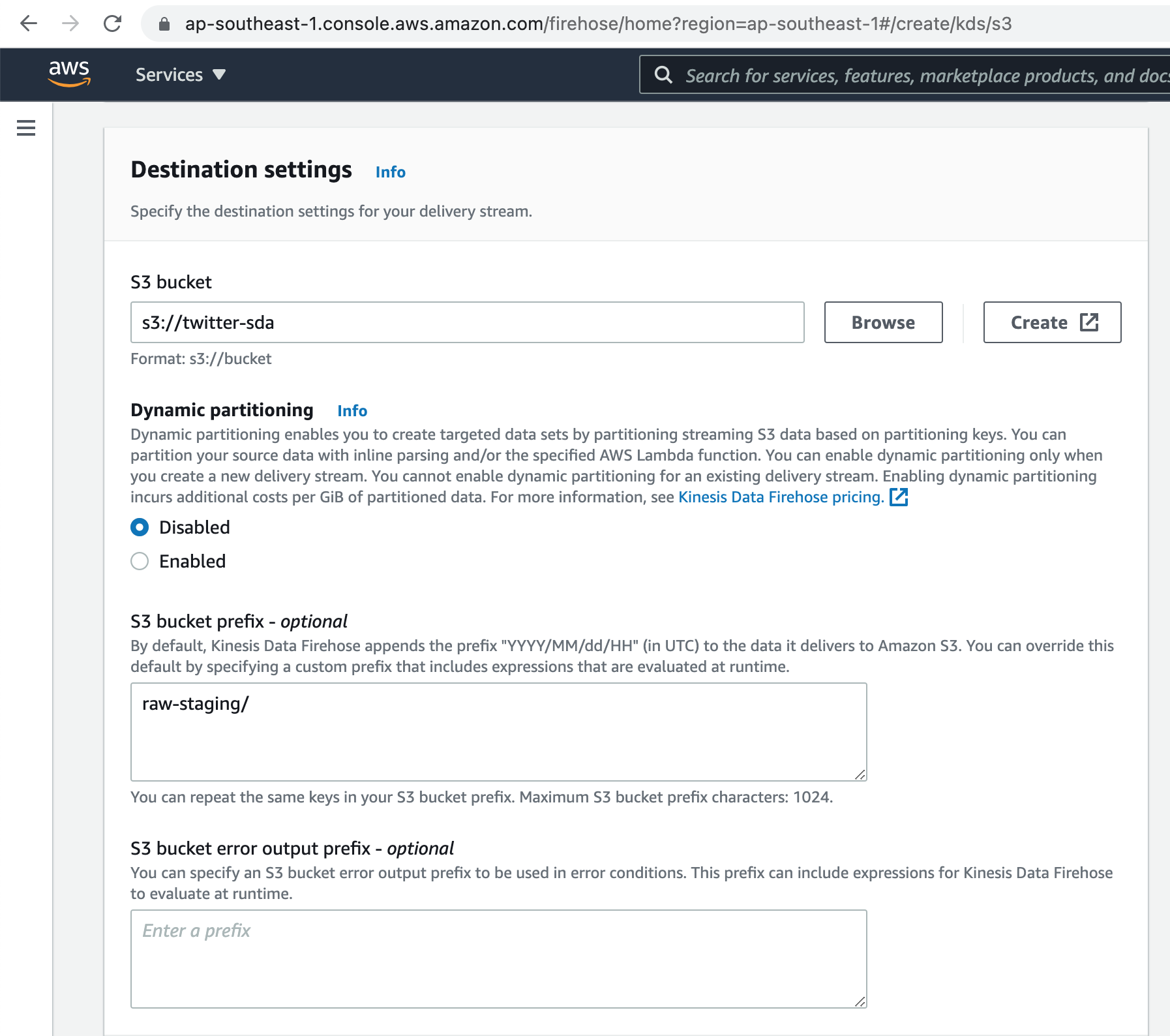
Kinesis Data Firehose buffers incoming records before delivering them to your S3 bucket. Record delivery is triggered once the value of either of the specified buffering hints is reached.
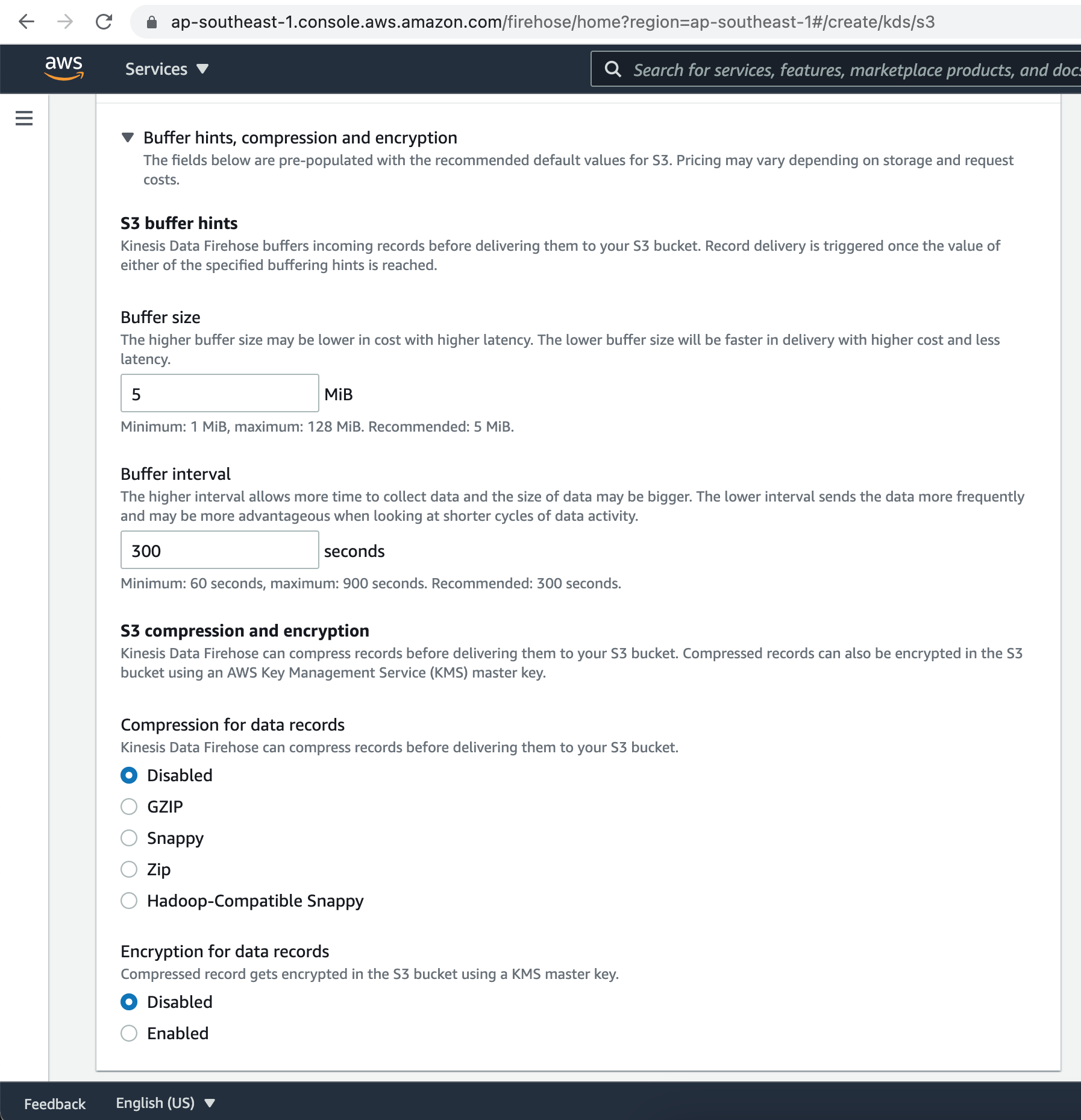
Kinesis Data Firehose can compress records before delivering them to your S3 bucket. Compressed records can also be encrypted in the S3 bucket using an AWS Key Management Service (KMS) master key.
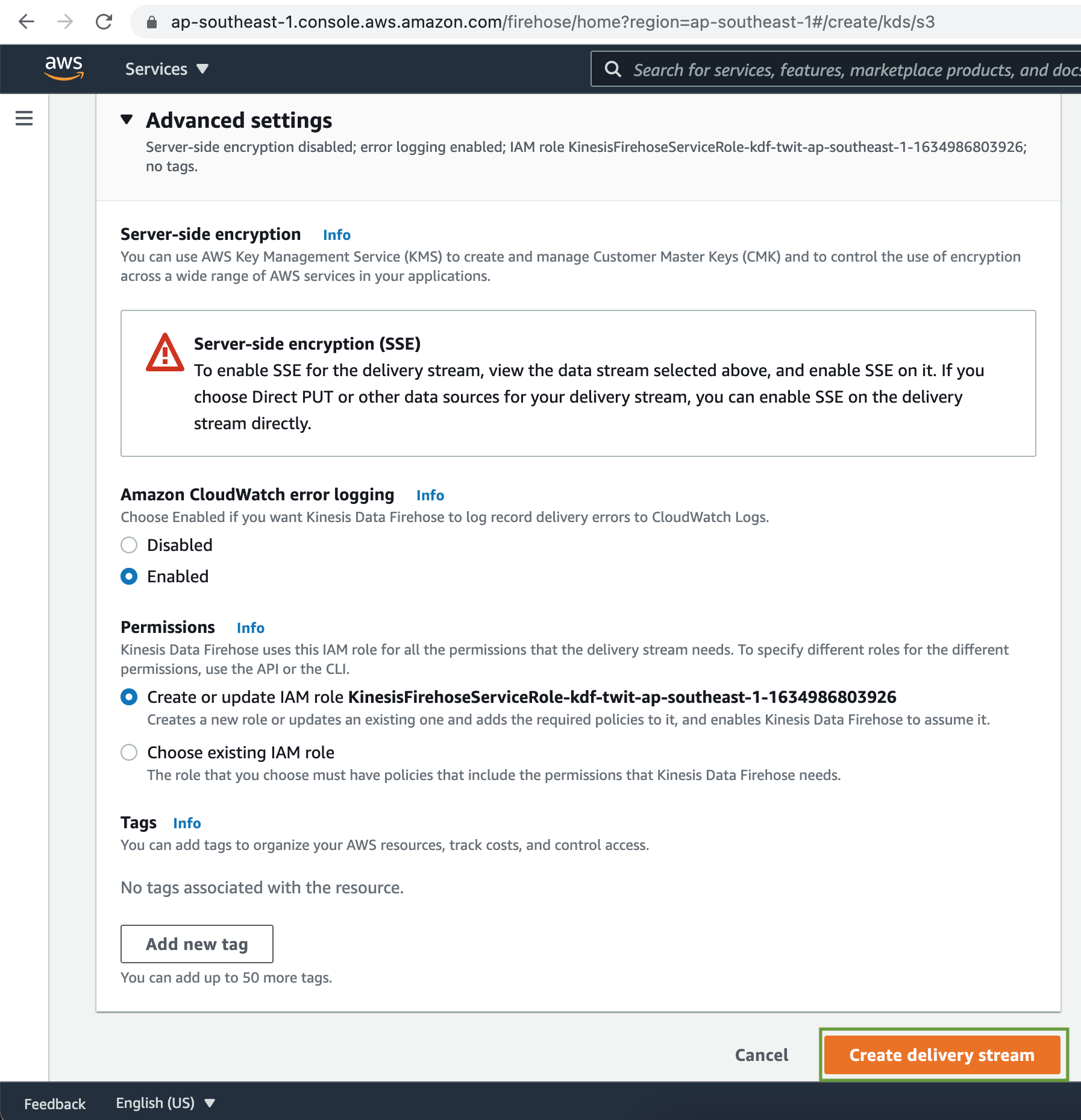
Under the Advanced settings, there is provision to enable Server Side data Encryption, as well as CloudWatch error logging. Finally click on the Create delivery stream button.
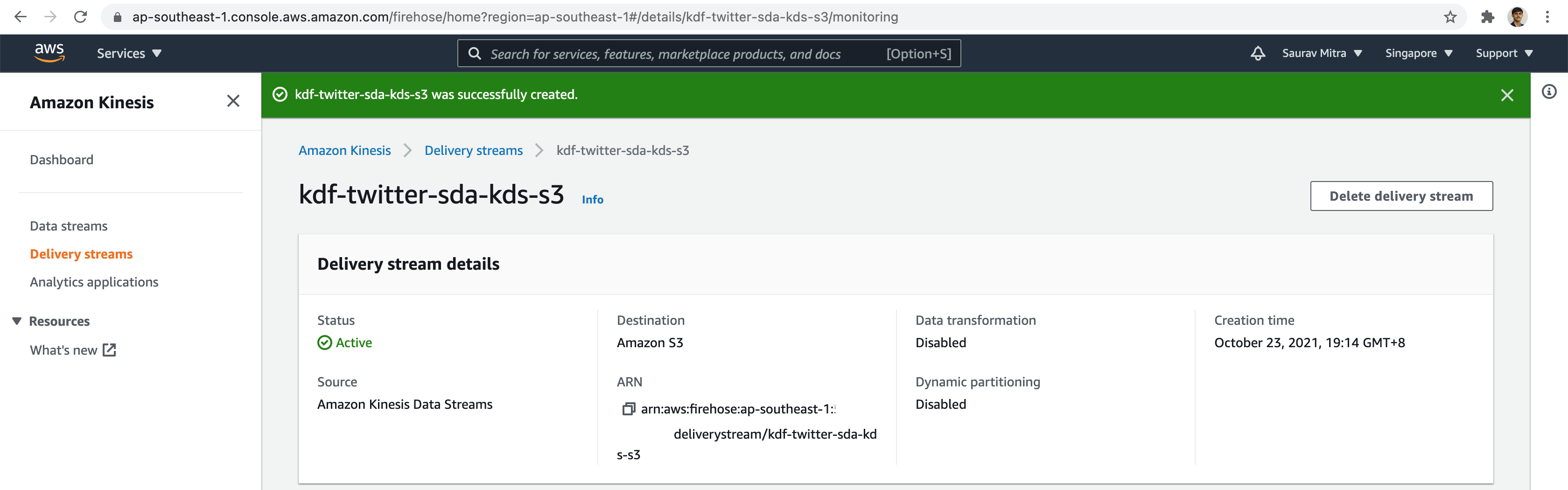
The Kinesis Delivery Stream is successfully created.
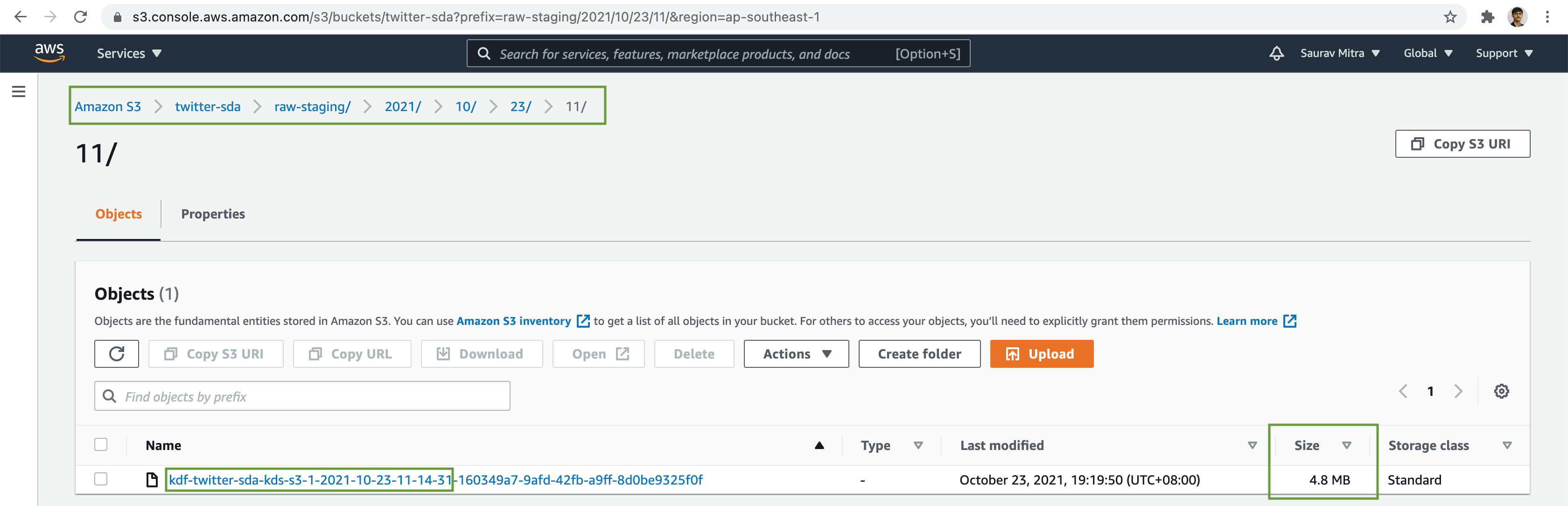
Verify that the streaming tweets are written durably in the S3 Bucket.
Streaming Data Analytics with Kinesis Data Analytics
Next we will perform Streaming Analytics on the tweets using Kinesis Data Analytics. Kinesis Data Analytics continuously reads and analyzes data from a connected streaming source in real time.
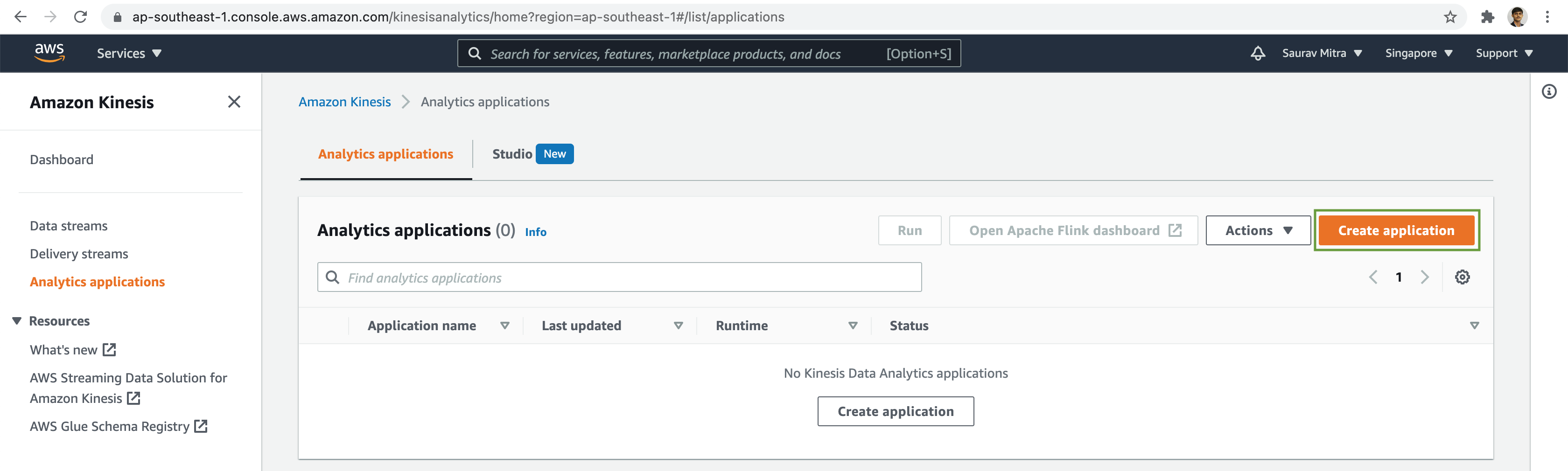
Lets process tweets in real-time using Kinesis Data Analytics legacy SQL engine, which provides an easy way to quickly query large volumes of streaming data.
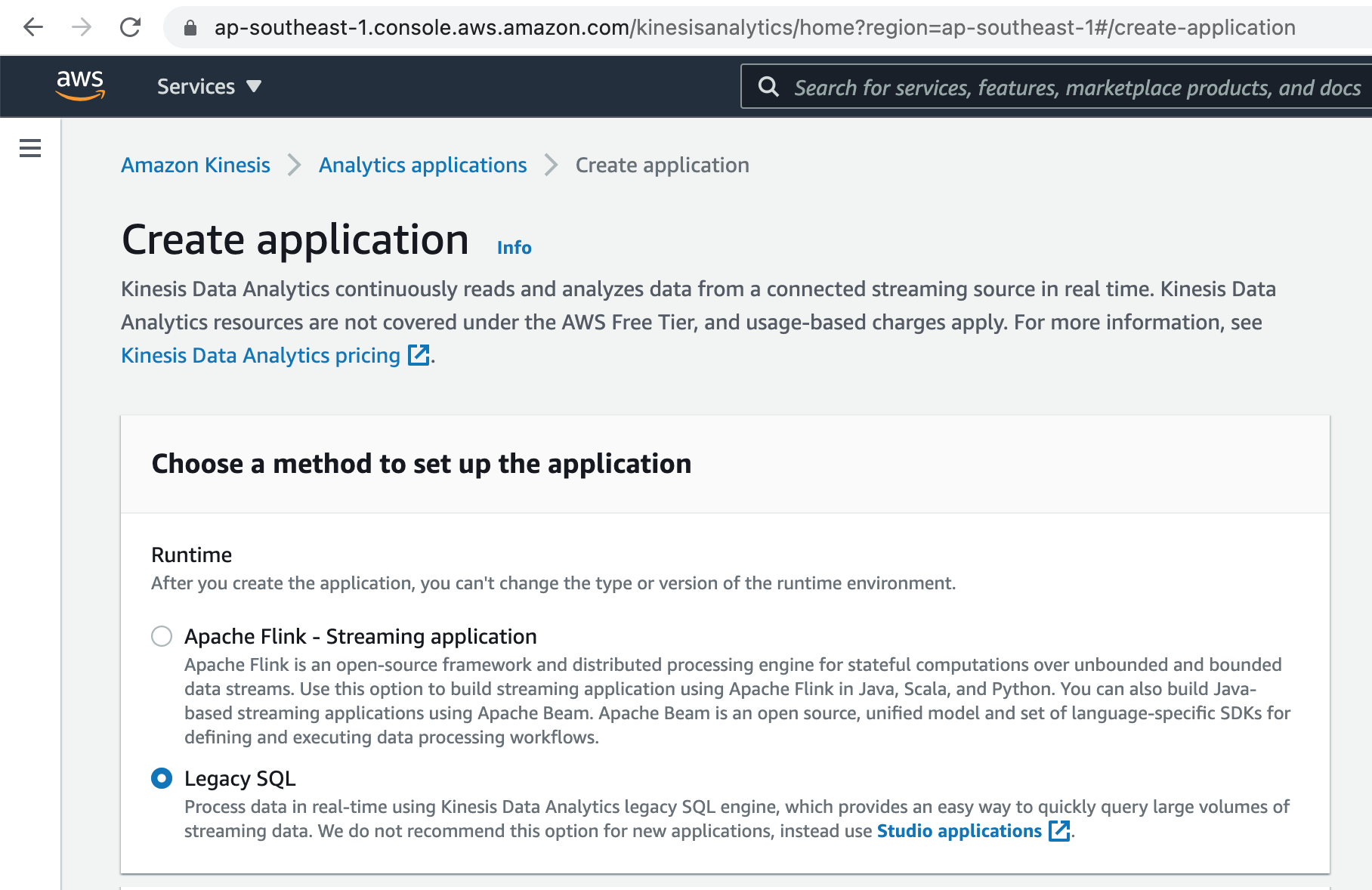
Add Kinesis Data Analytics application name and optional description.
The Kinesis Data Analytics was created successfully. Next we will setup source data stream for analysis, configure SQL to query streaming data and finally store the analysis result to destination. Click on the Configure source stream button.
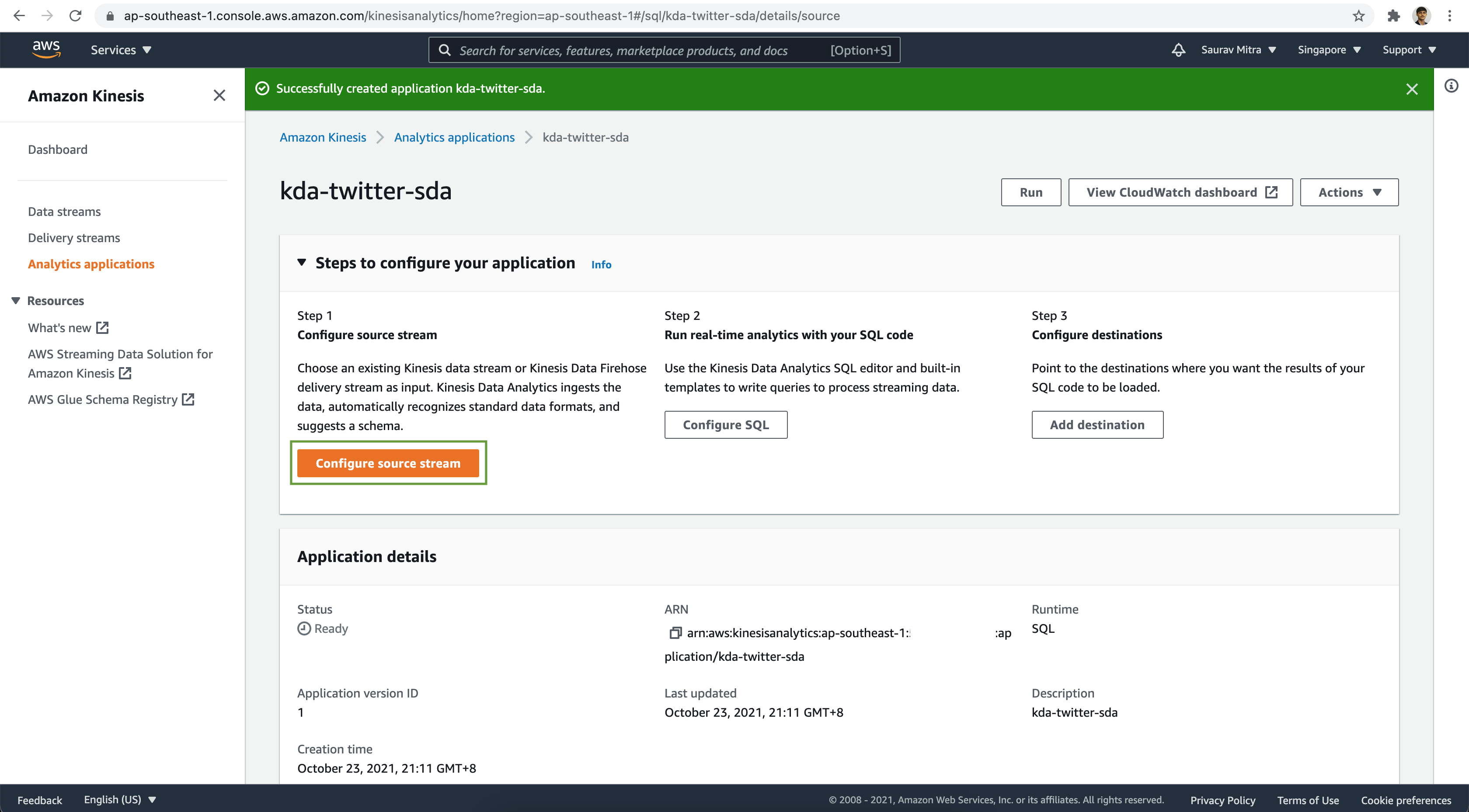
Select Kinesis data stream as Source. Browse & Choose the Kinesis Data Stream we created earlier.
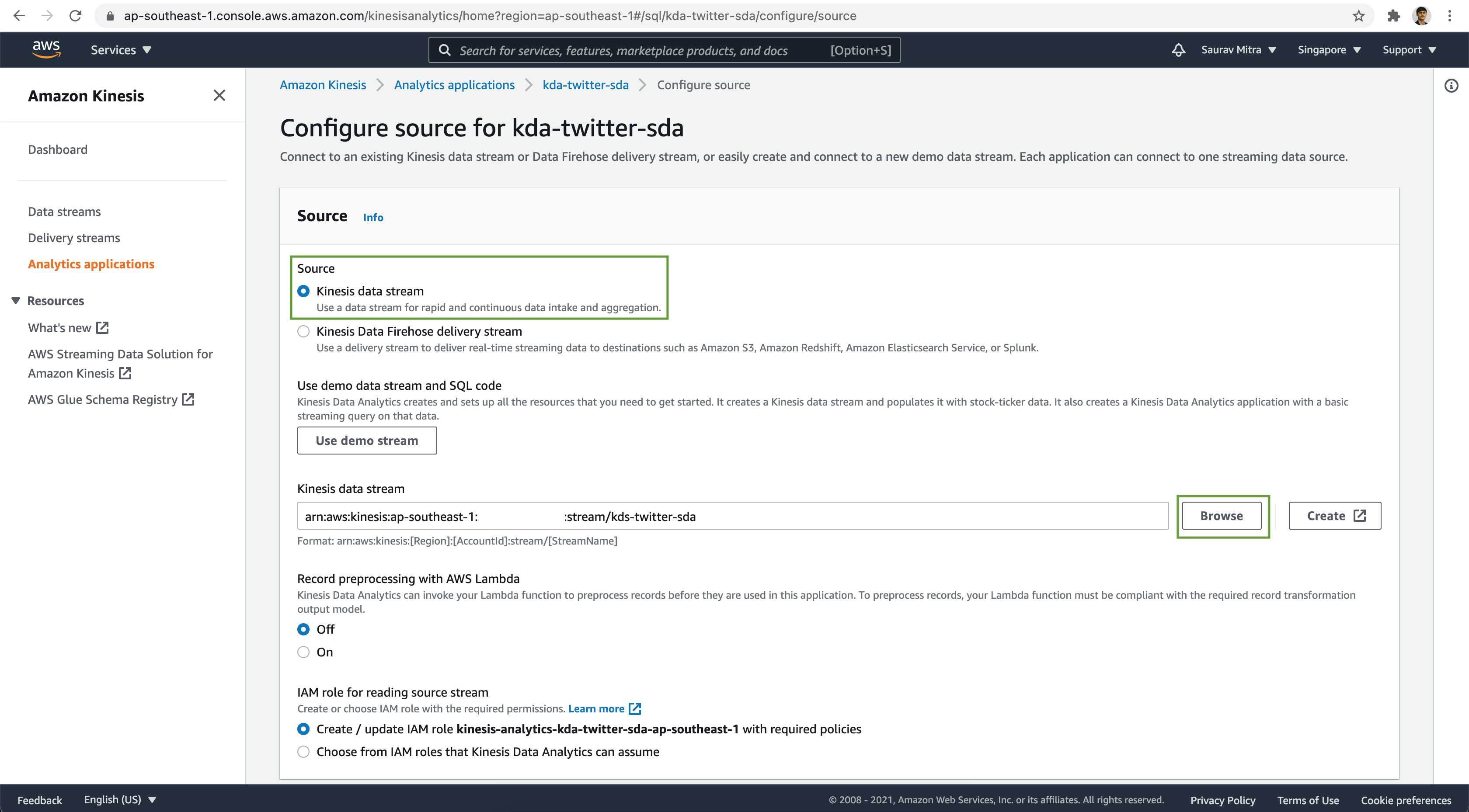
Under the Schema section, click on the Discover schema button. This will try to auto-discover the schema from the messages.
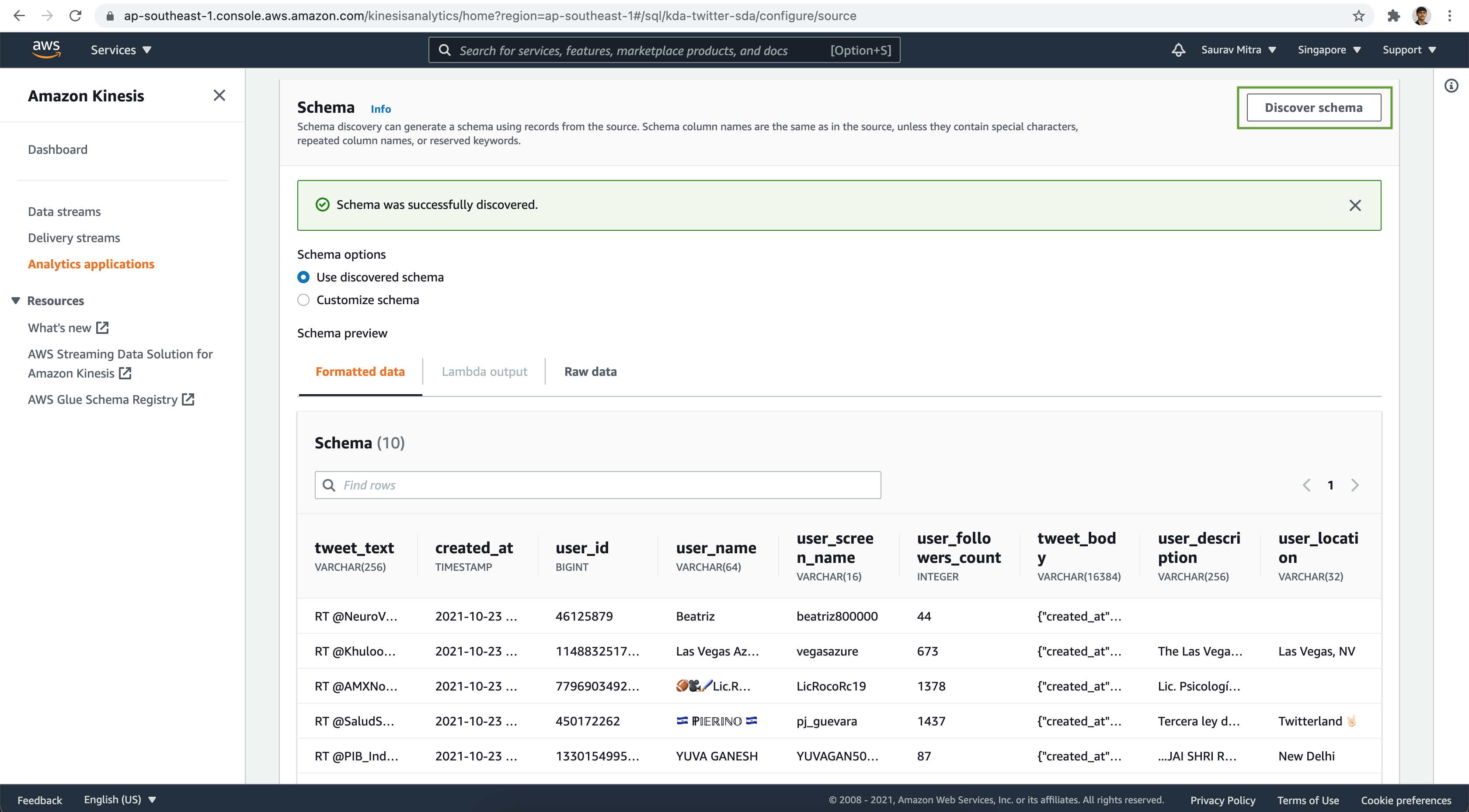
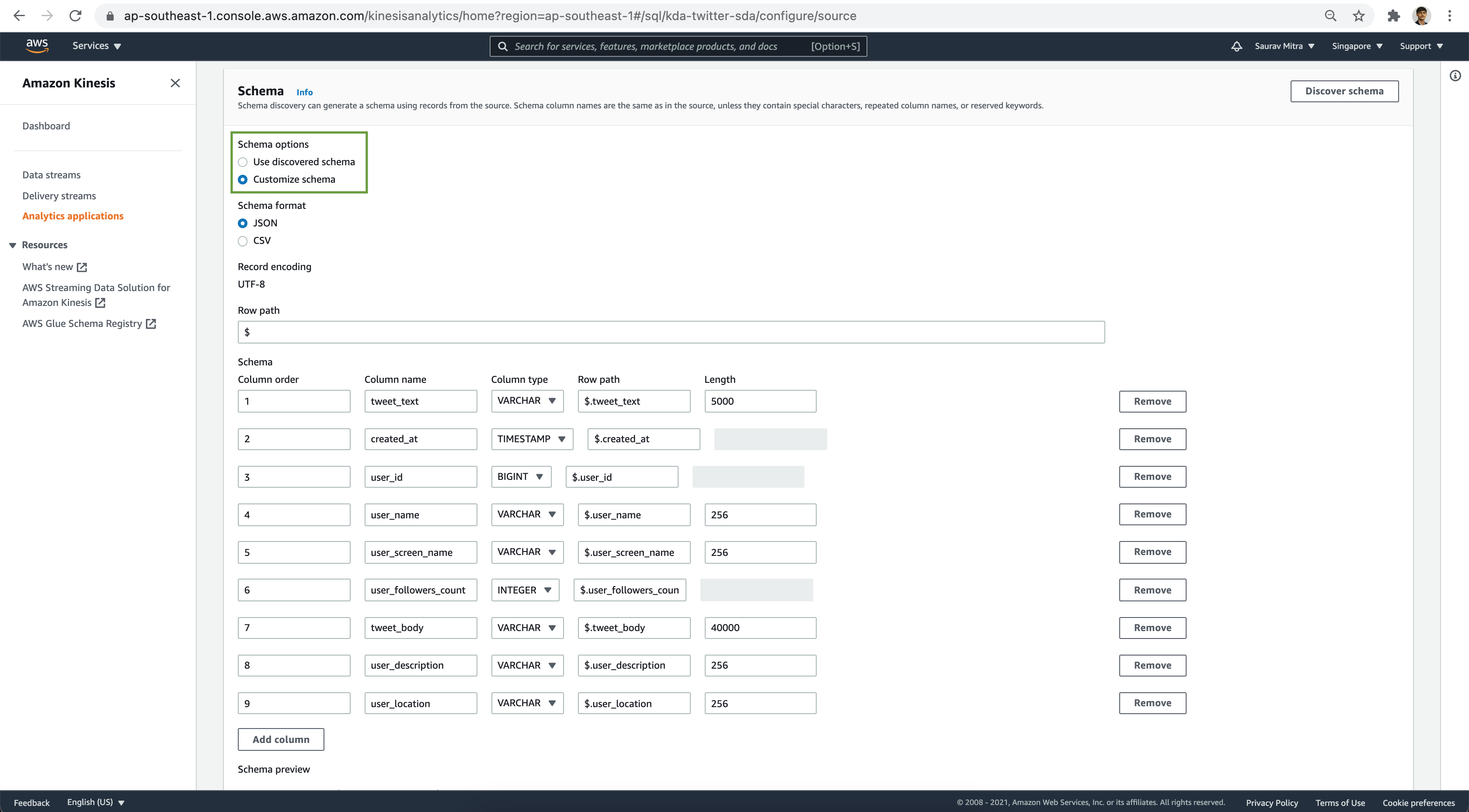
Let's customize the schema to set the data types properly. Click on the Customize schema radio button and modify the schema definition.
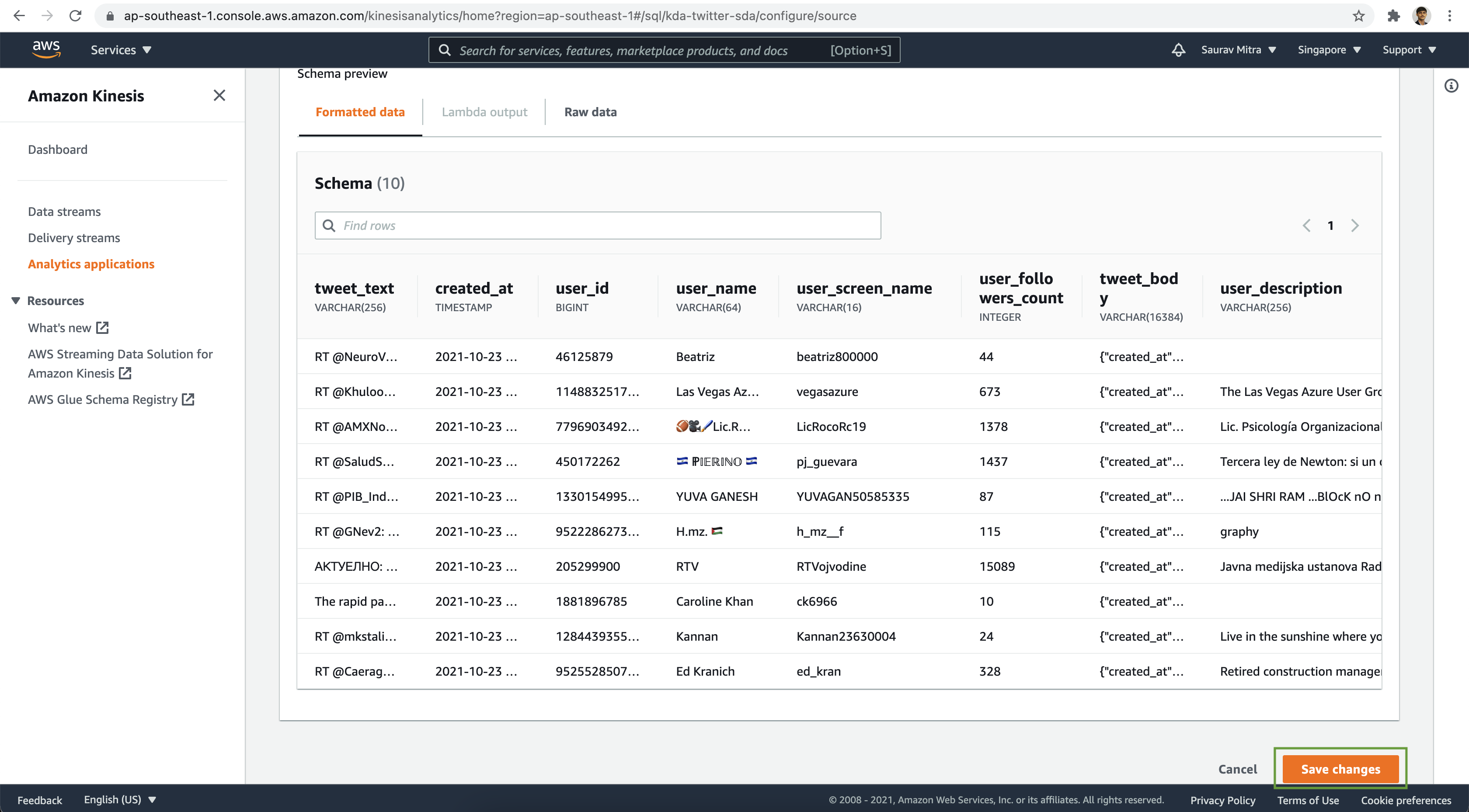
Verify the schema & data preview. Finally click on the Save changes button.
Next we will write SQL query to analyze the streaming messages. Click on the Configure SQL button.
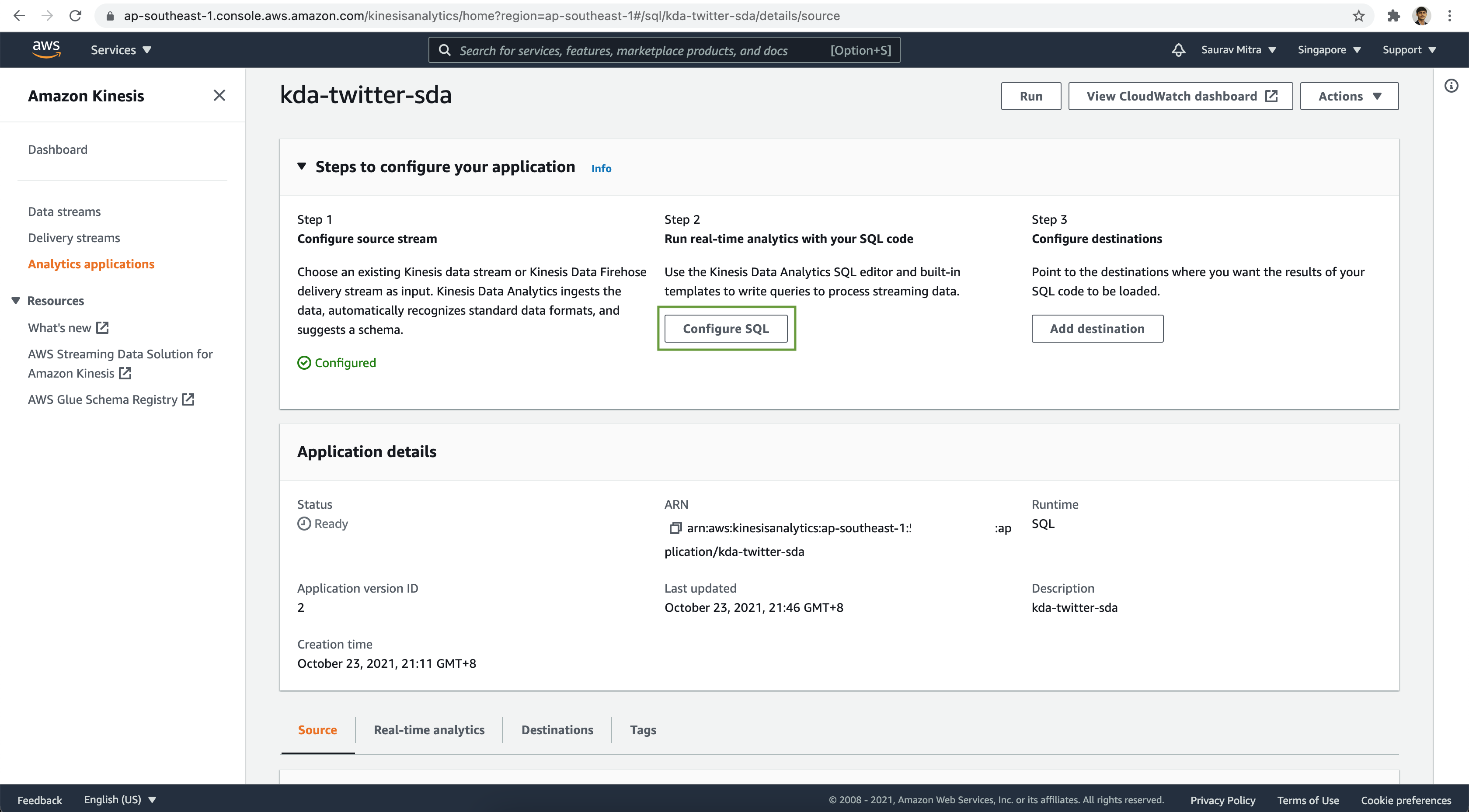
Let's filter the tweets based on user's having followers count greater than 5000. Click on the Save and run application button.
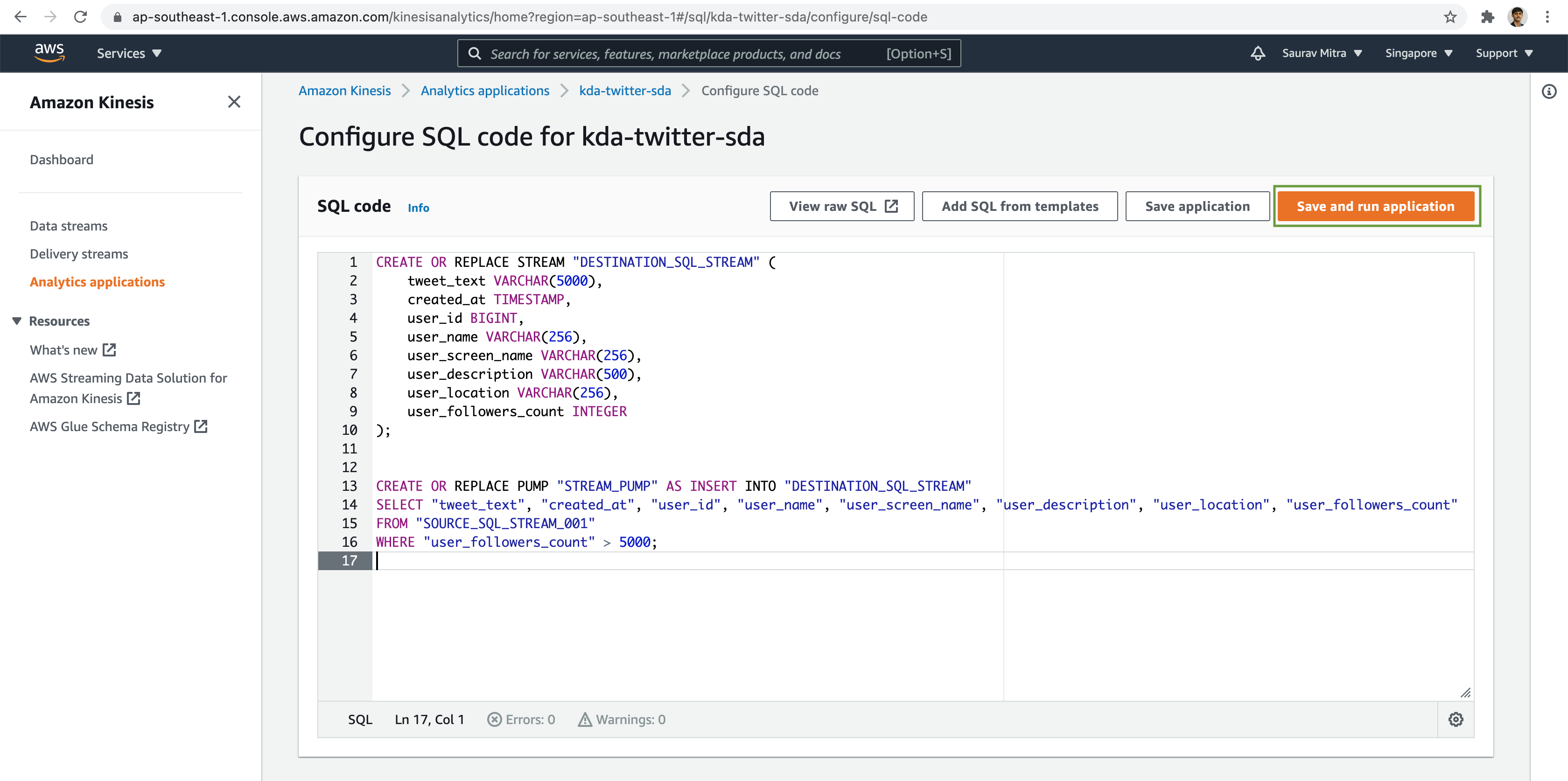
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
tweet_text VARCHAR(5000),
created_at TIMESTAMP,
user_id BIGINT,
user_name VARCHAR(256),
user_screen_name VARCHAR(256),
user_description VARCHAR(500),
user_location VARCHAR(256),
user_followers_count INTEGER
);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT "tweet_text", "created_at", "user_id", "user_name", "user_screen_name", "user_description", "user_location", "user_followers_count"
FROM "SOURCE_SQL_STREAM_001"
WHERE "user_followers_count" > 5000;Once the Kinesis Data Analytics Application has been successfully updated & started, let's verify the analytics output stream data.
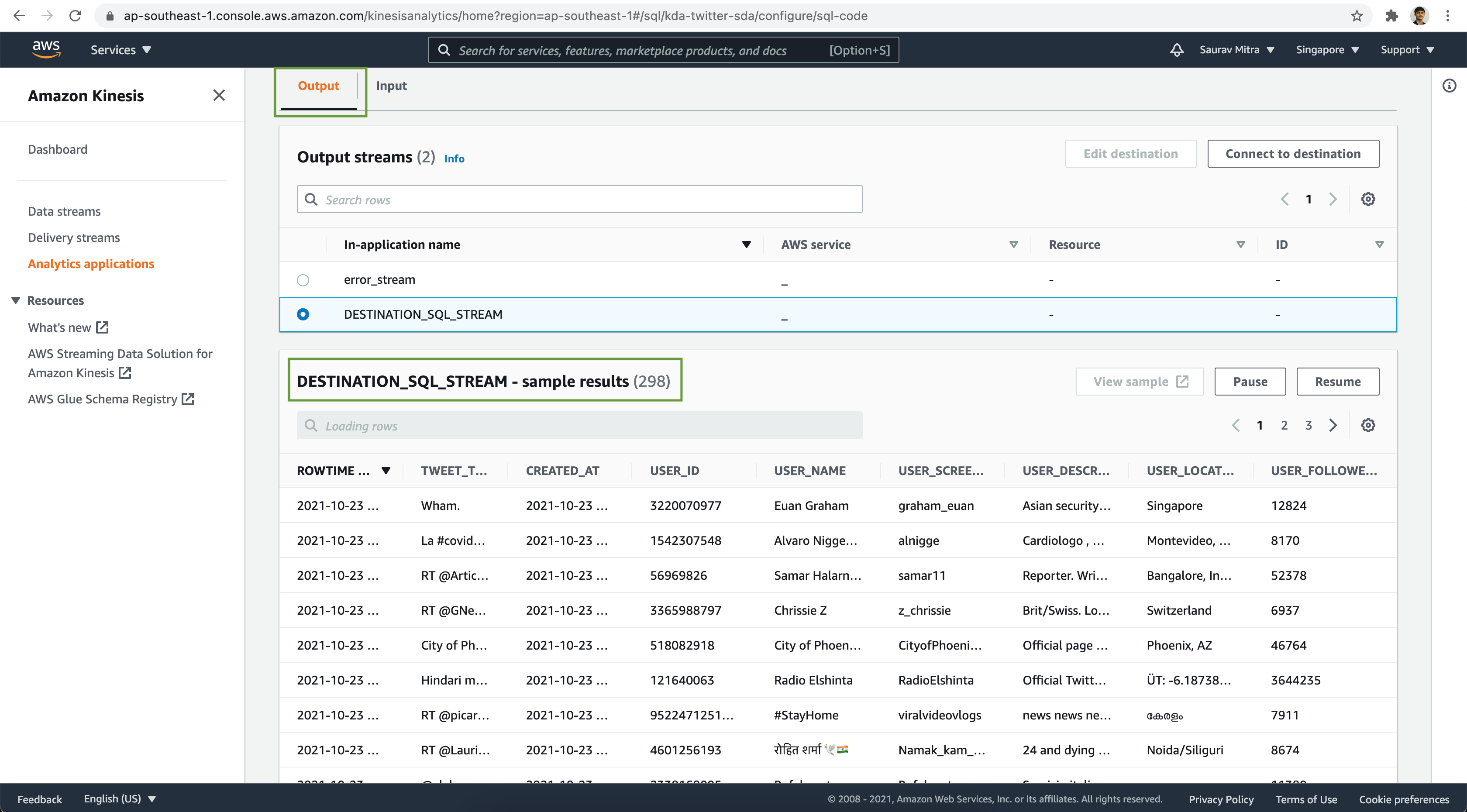
Storing Analytics Results
Finally we will write the analysis results to our processed S3 data lake bucket. First we need to create another Kinesis Delivery Stream/Firehose to write the analysed data from Kinesis Data Analytics to S3 bucket.
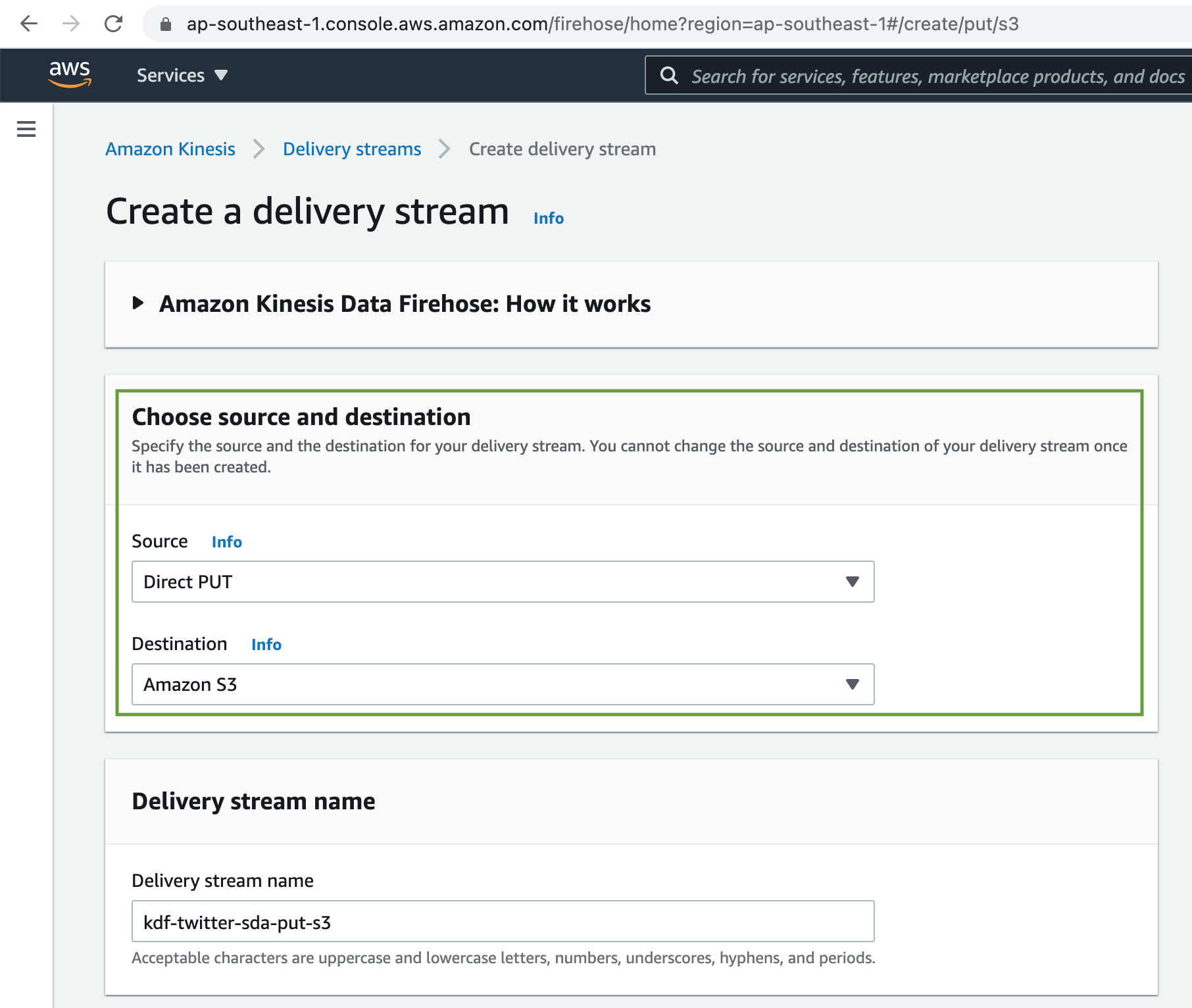
Select the source as Direct PUT and destination as Amazon S3. We are not going to perform any source message transformation or record format conversion.
Under the Destinations settings Browse & Choose the S3 bucket for processed data.
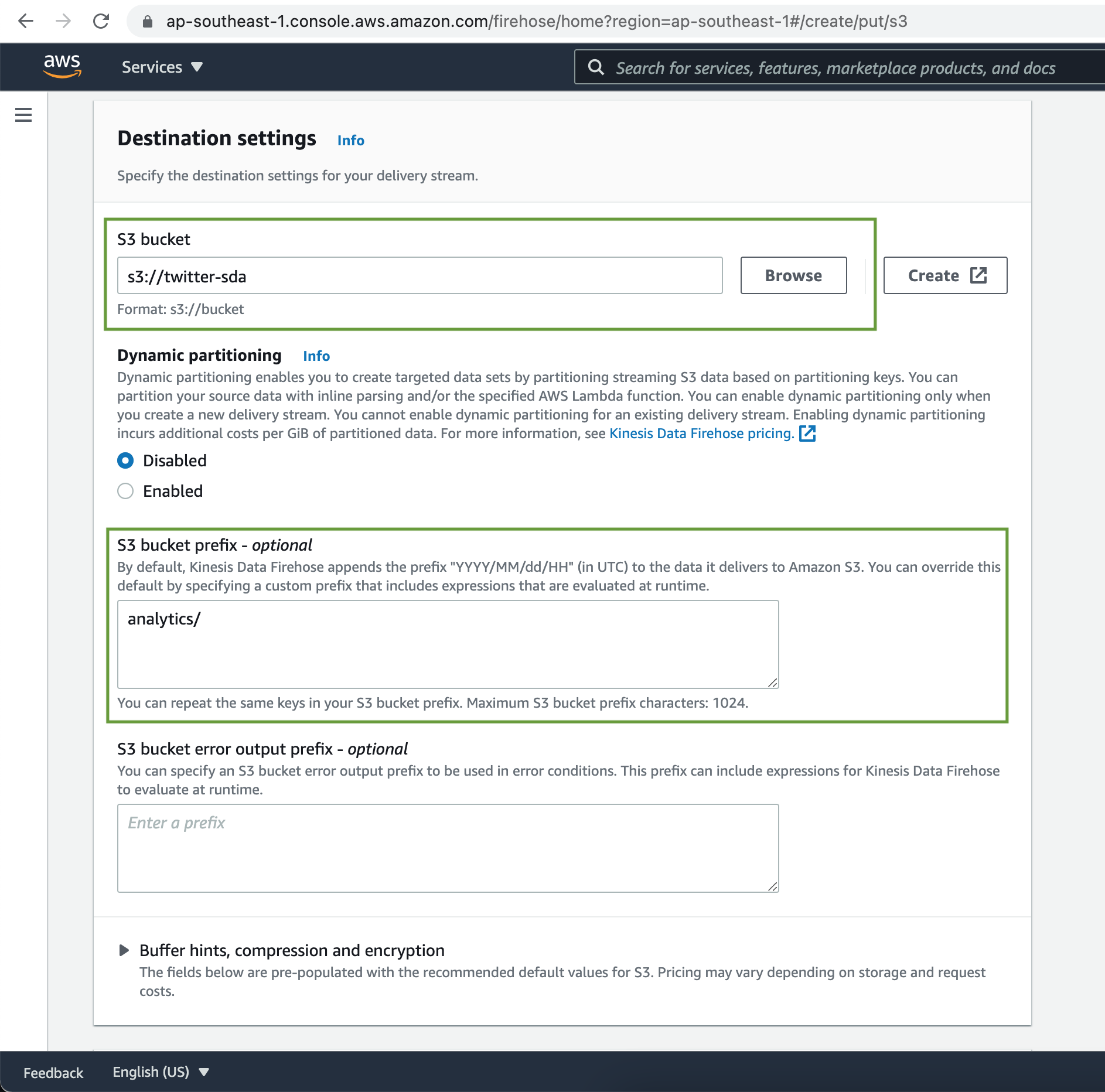
Set Buffer hints, compression and encryption to their defaults. Under Advanced settings set Server-side encryption to disabled and CloudWatch error logging enabled. Finally click on Create delivery stream button
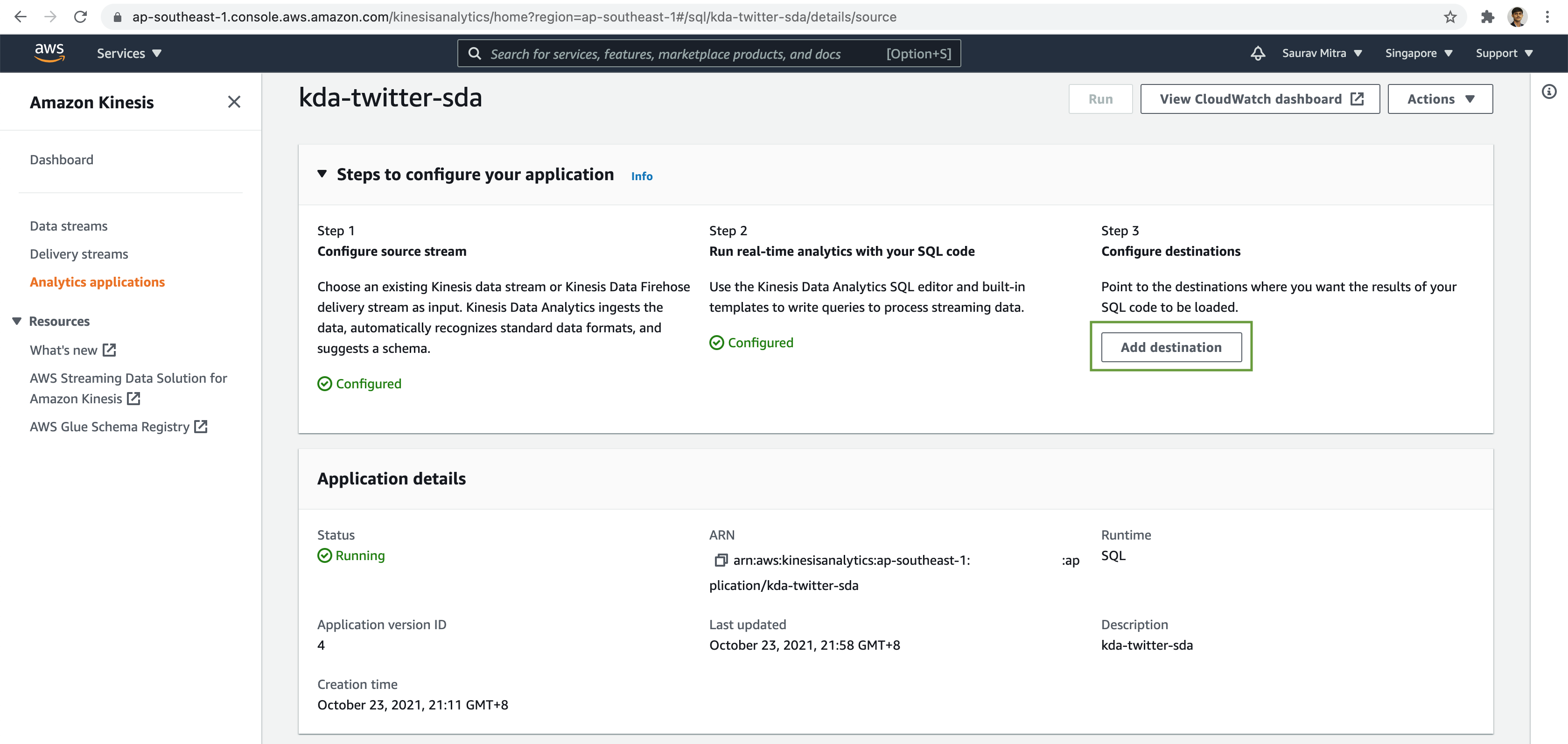
Now back to our Kinesis Data Analytics, Click on the Add destination button.
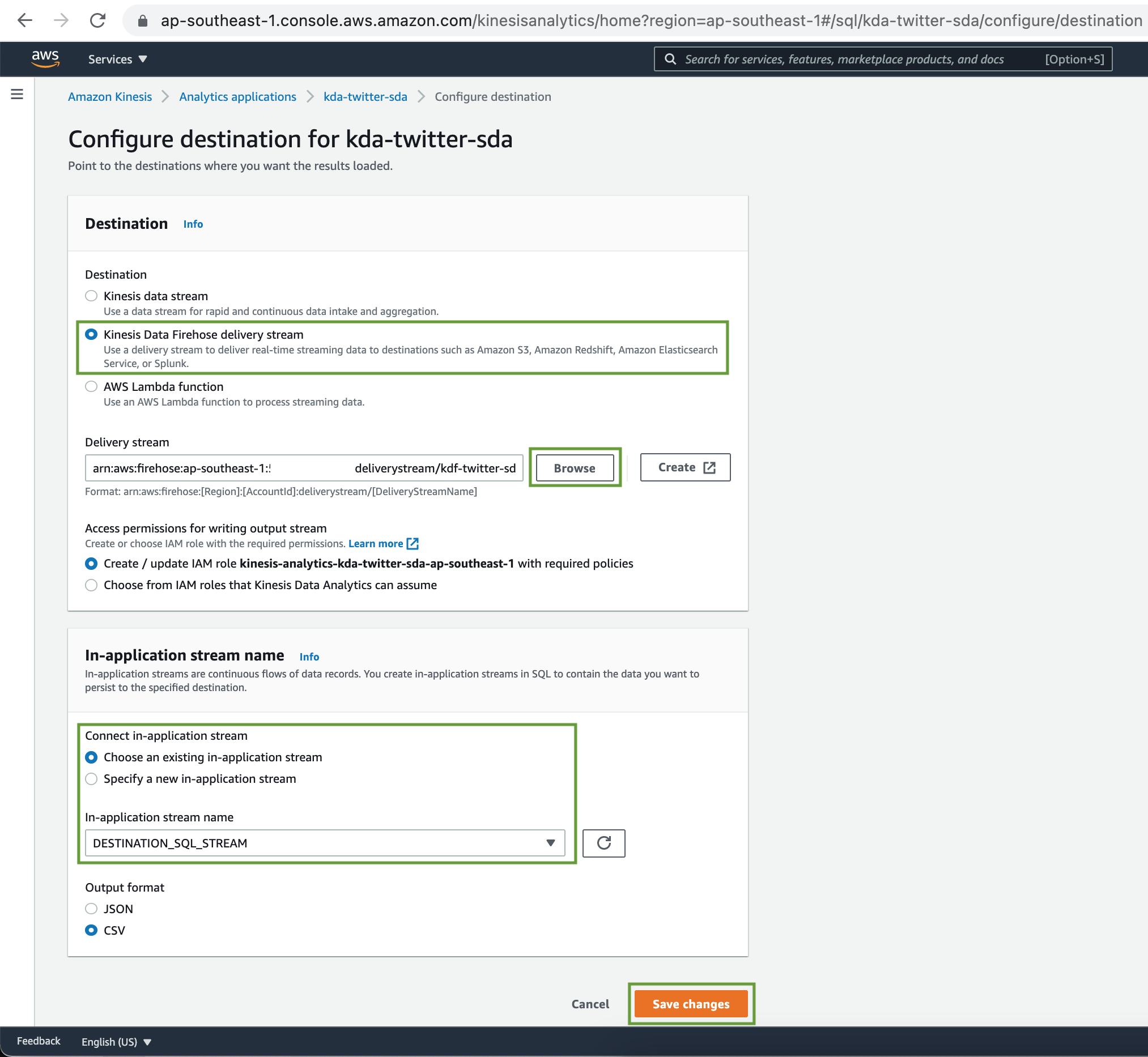
Set Destination as Kinesis Data Firehose delivery stream. Browse & Choose the Kinesis Delivery Stream that we created just now. Select the Application stream name from the dropdown menu. Let's choose our output data file format as CSV. Finally click on the Save changes button.
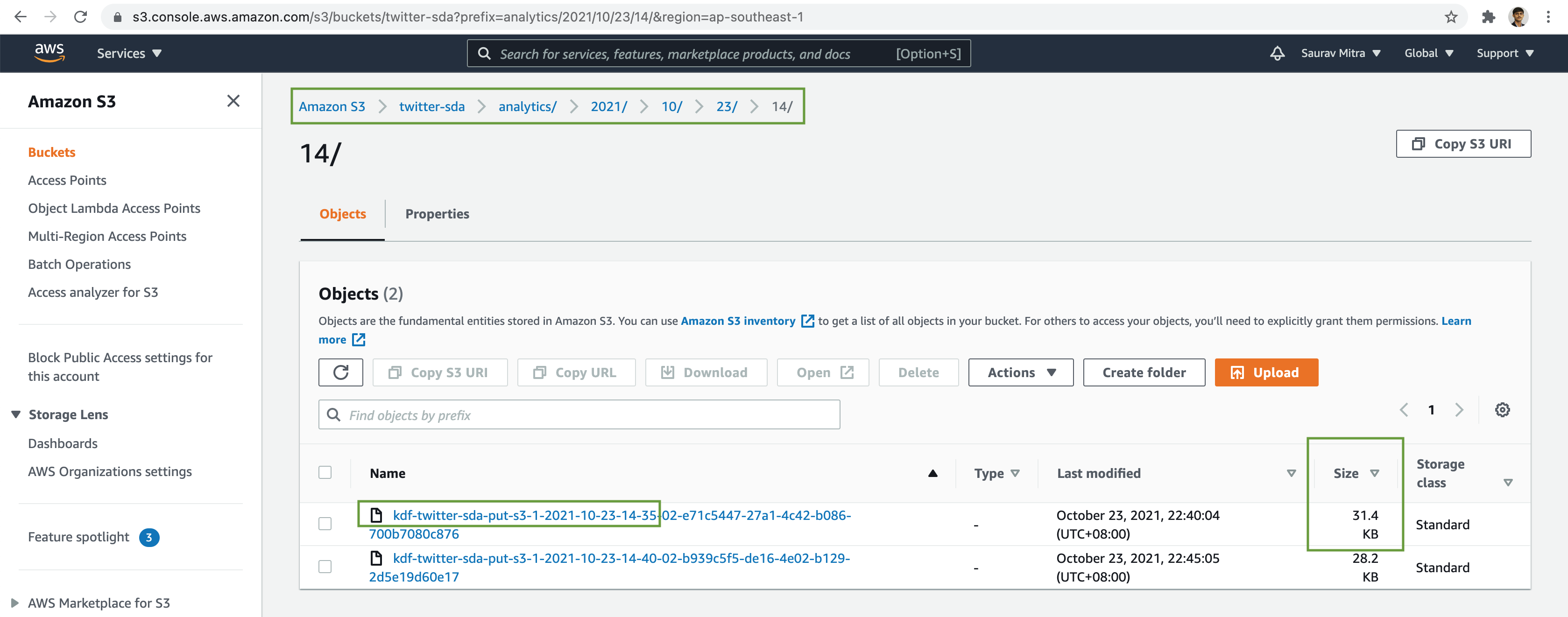
At the very last step, verify the real-time analysed stream dataset has been written durably in the S3 data lake bucket.
By integrating Twitter's streaming API with Amazon Kinesis, you can efficiently collect, process, and analyze real-time data. This setup is powerful for applications requiring timely insights from continuous data streams.
