
Streaming Data Analytics with Amazon MSK


In the era of big data, the ability to analyze streaming data in real-time is essential for gaining timely insights and making data-driven decisions. Amazon Managed Streaming for Apache Kafka (MSK) is a powerful solution for this purpose. This article guides you through setting up Amazon MSK, ingesting data from Twitter, and analyzing it using Apache Flink.
Setting Up Amazon MSK
First of all, we will create our MSK cluster configuration. Click on the Cluster configurations link.
Click on the Create cluster configuration button.
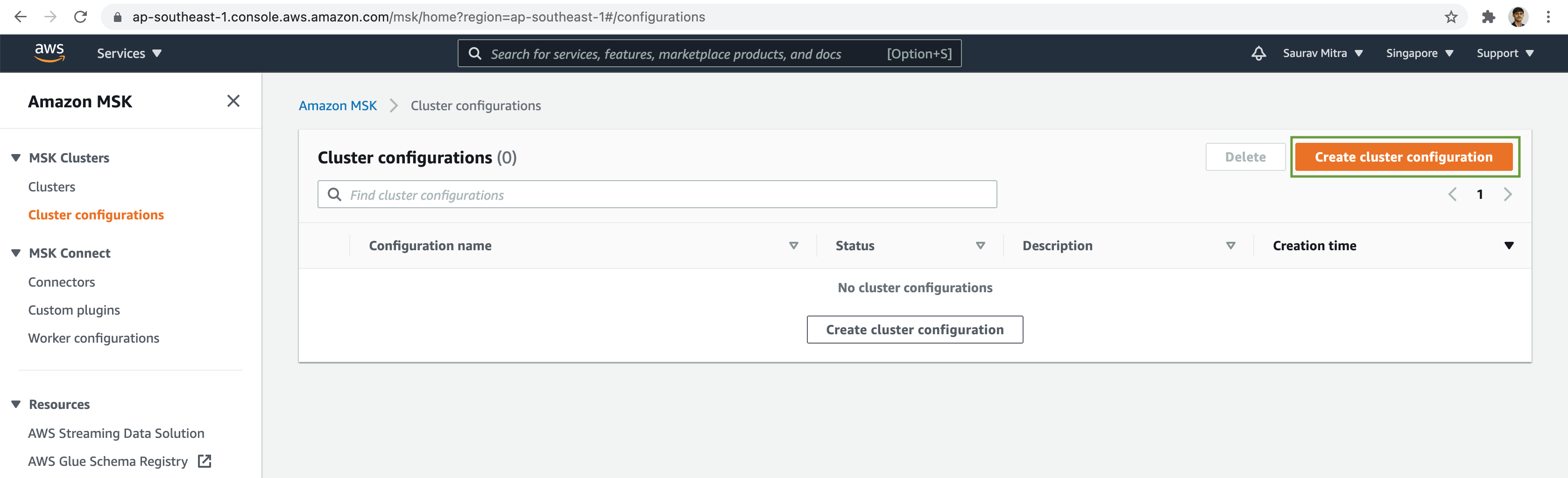
Add a name for our configuration & set the Configuration properties. Next click on the Create button.
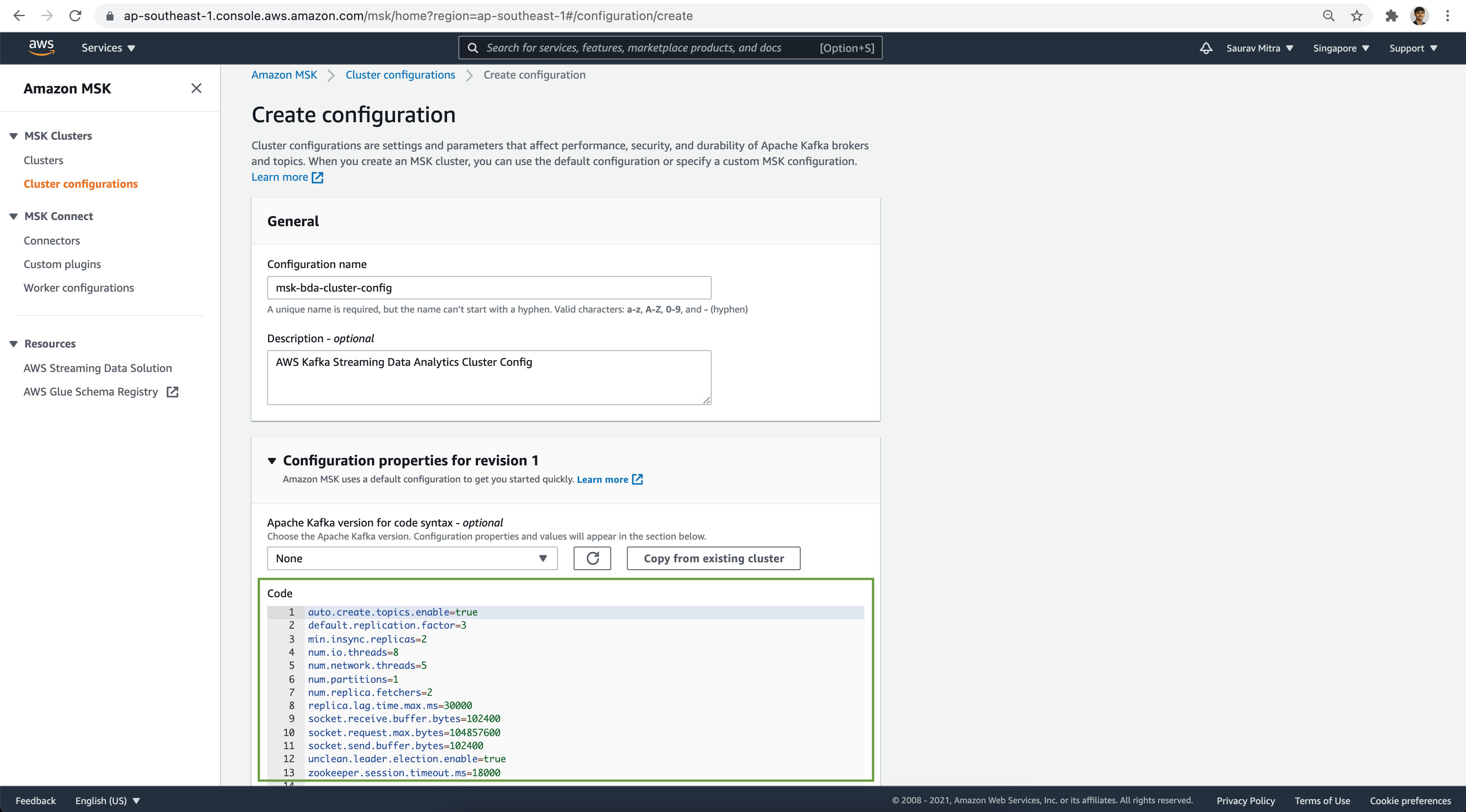
auto.create.topics.enable=true
default.replication.factor=3
min.insync.replicas=2
num.io.threads=8
num.network.threads=5
num.partitions=1
num.replica.fetchers=2
replica.lag.time.max.ms=30000
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
socket.send.buffer.bytes=102400
unclean.leader.election.enable=true
zookeeper.session.timeout.ms=18000
Next click on the Clusters link, and then click on the Create cluster button.
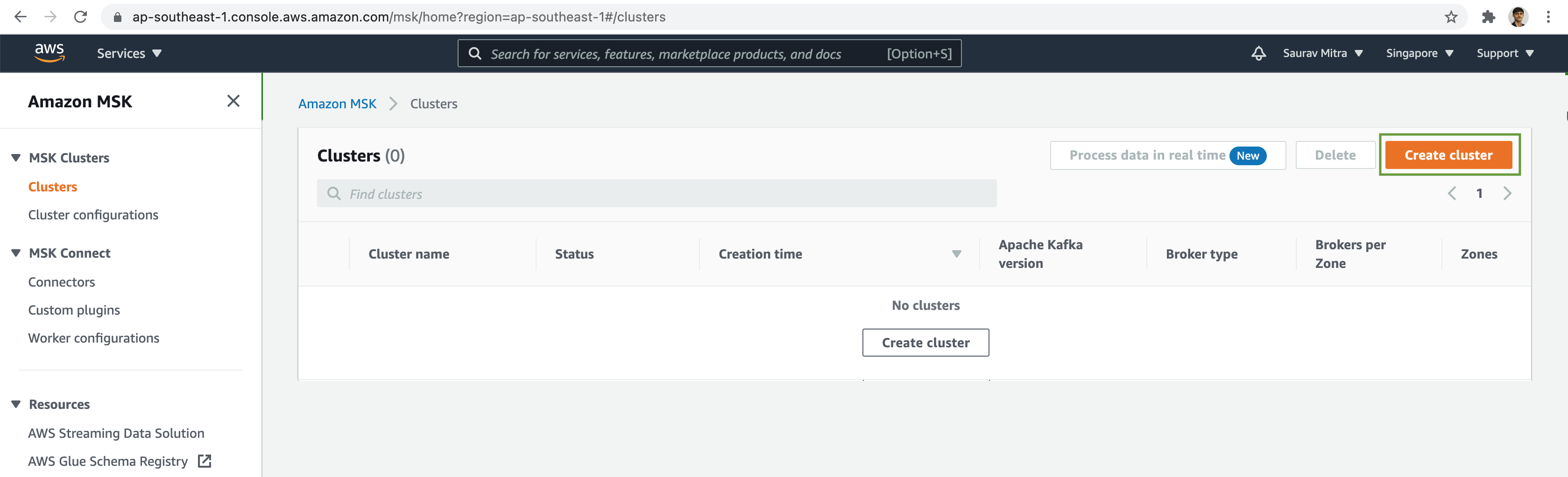
Select the Custom create method. Next add a name for the MSK Cluster & choose the Apache Kafka version from the dropdown list.
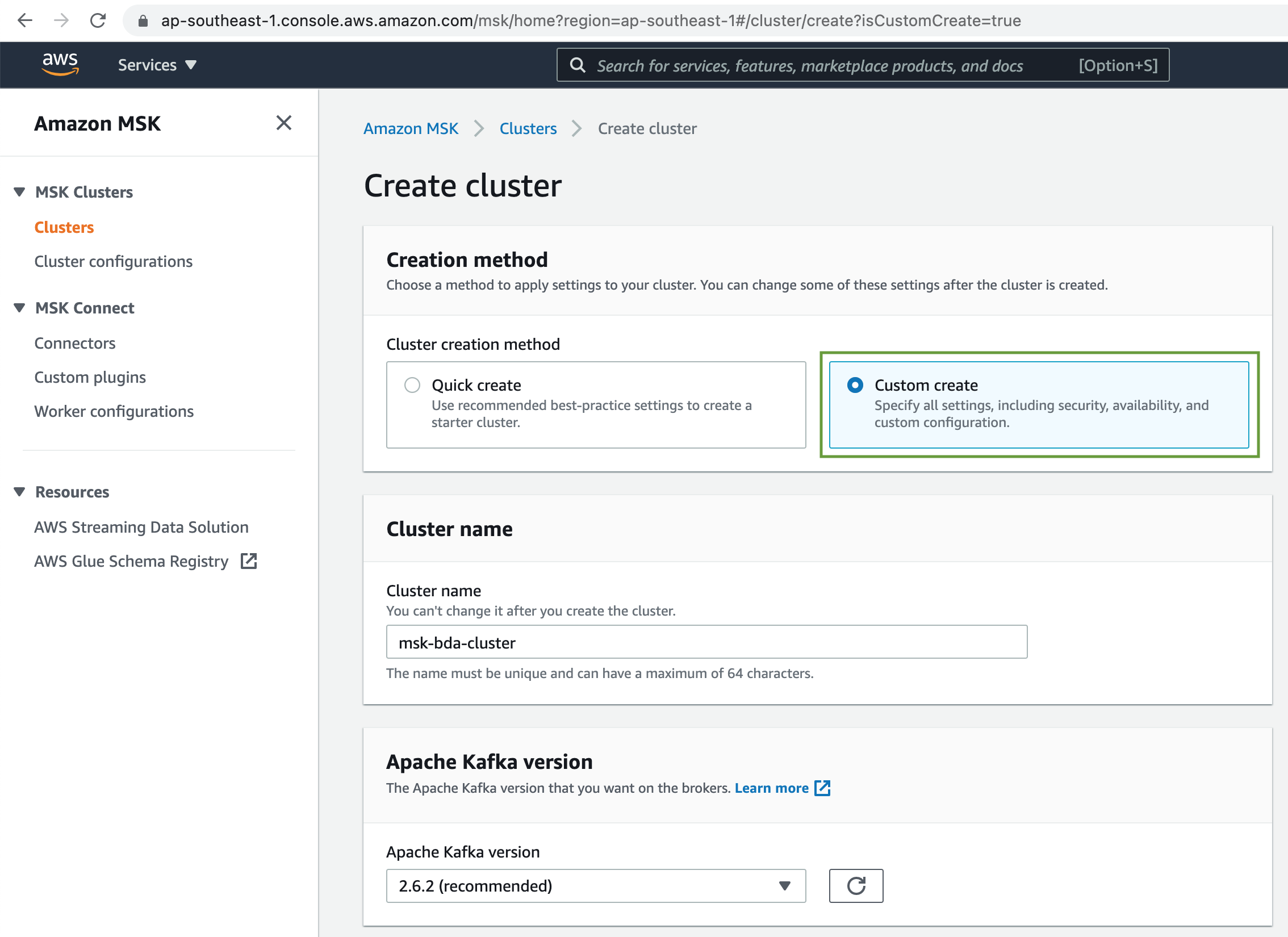
Under the Configuration, select the MSK Cluster configuration we created earlier from the dropdown list.
Next select the VPC & Subnets to deploy the MSK cluster.
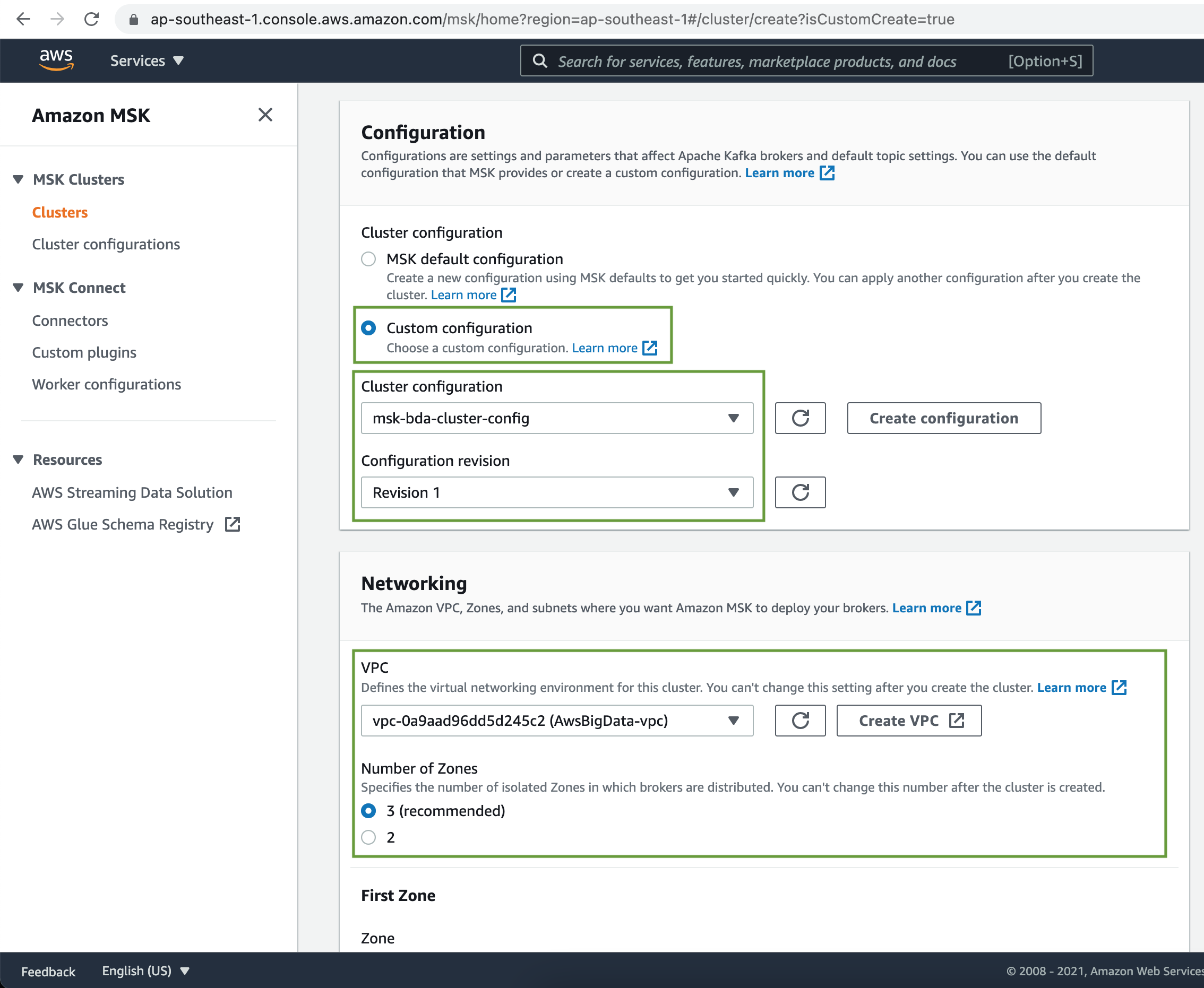
Select the appropriate Subnets to deploy the Kafka Brokers.
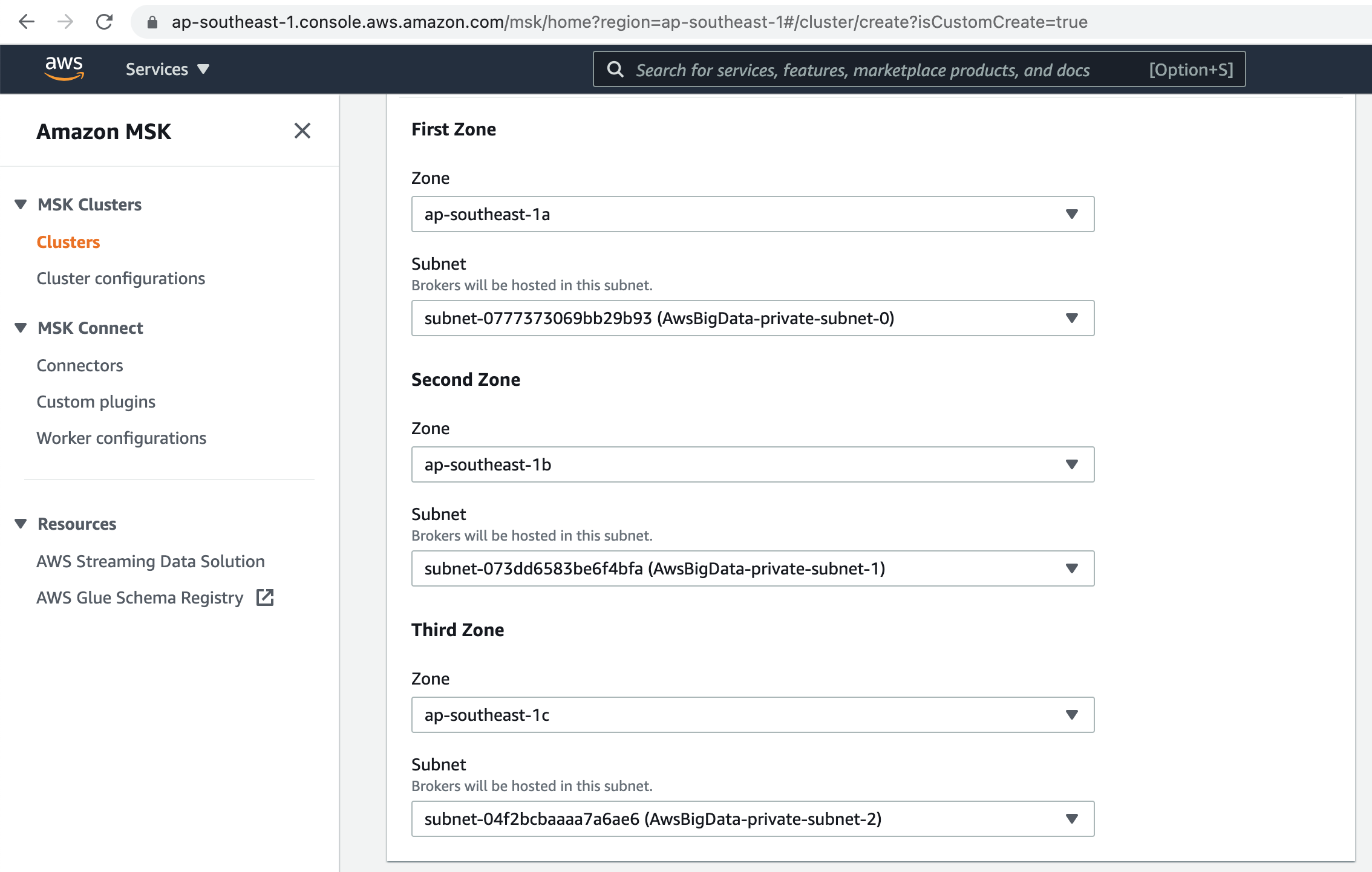
Next select a Security Group. Choose Broker Instance type & Number of Brokers per Zone.
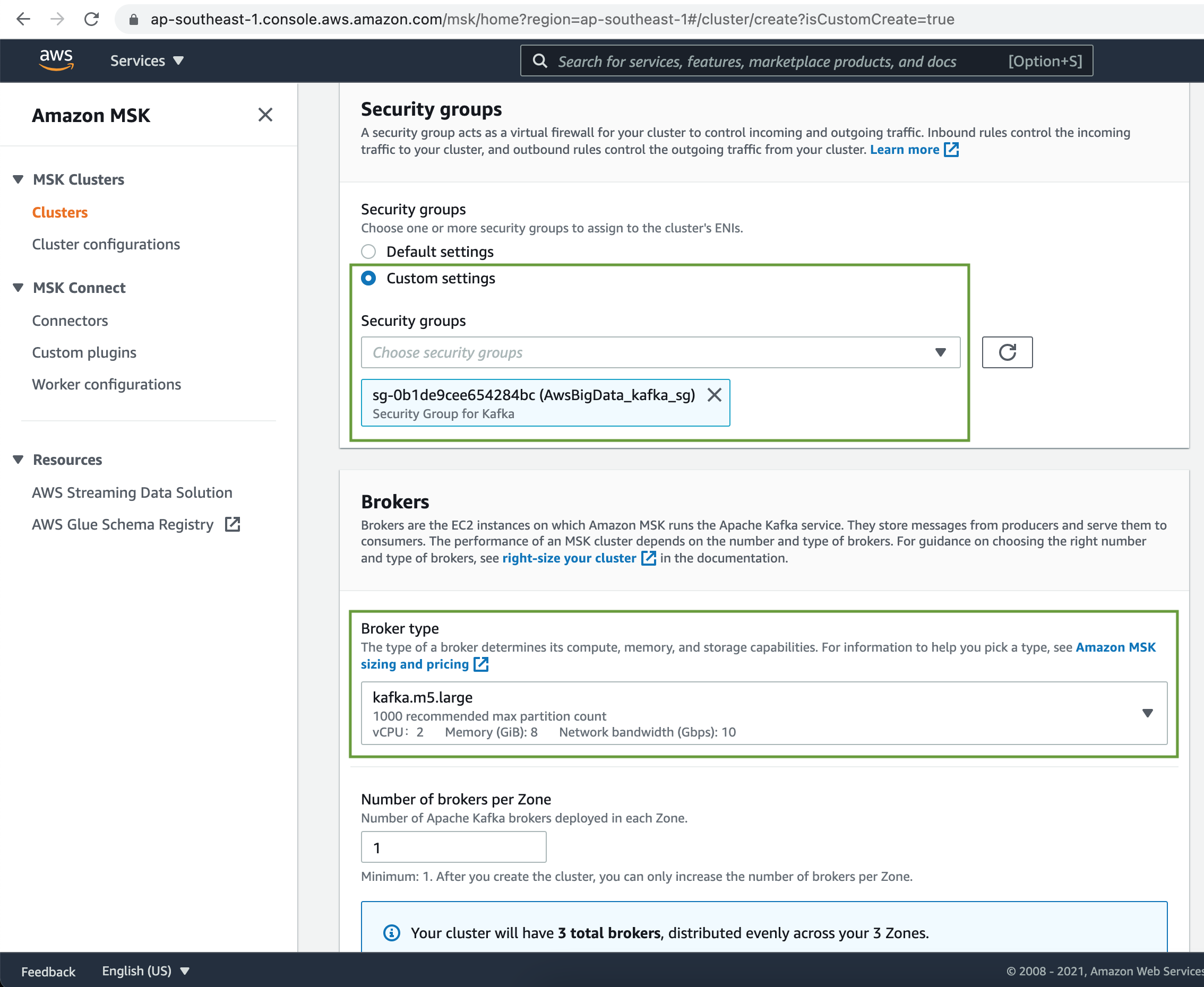
Select the Broker Storage size.
MSK Cluster allows multiple access control methods. Let's choose unauthenticated access as well as IAM role-based authentication.
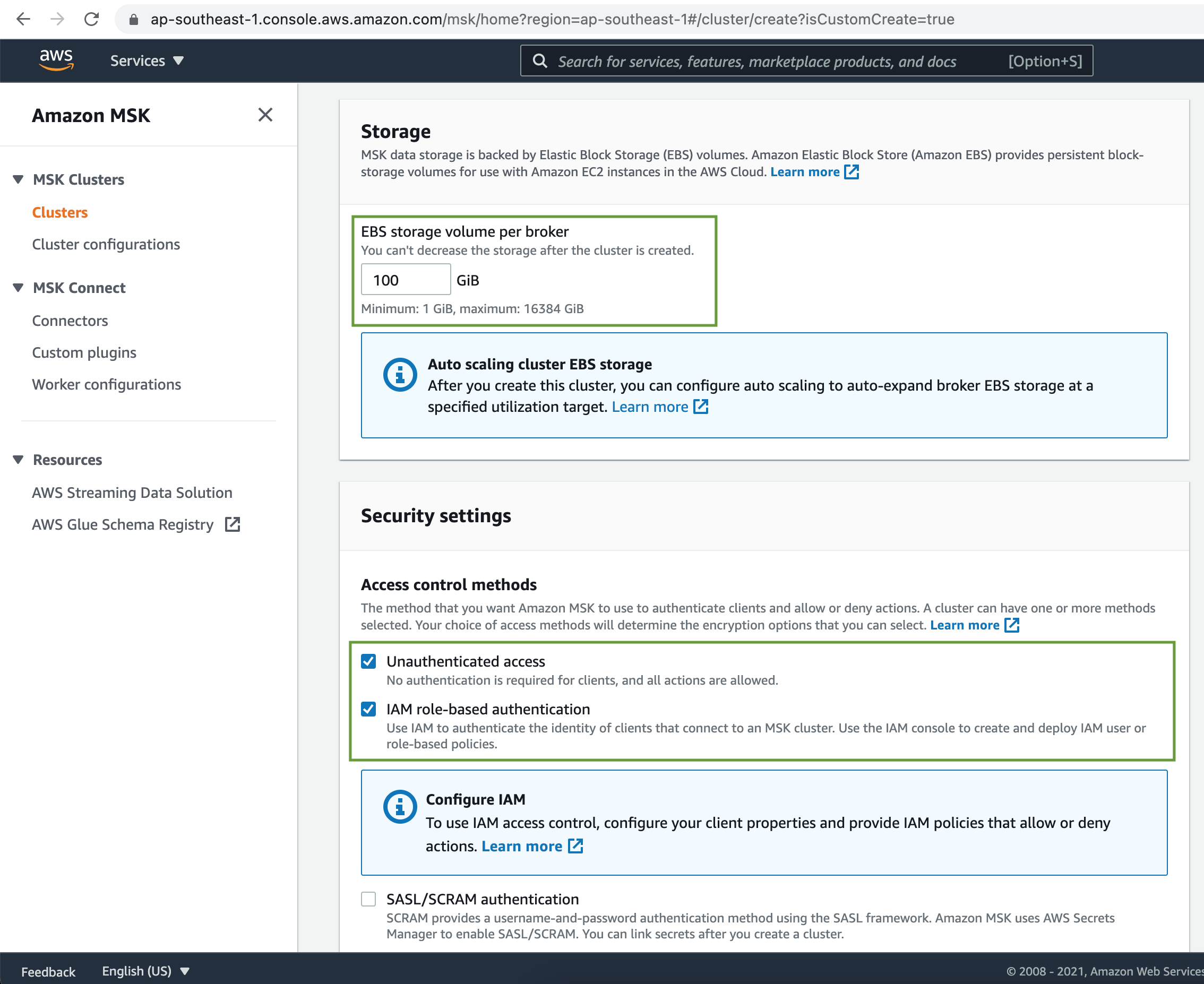
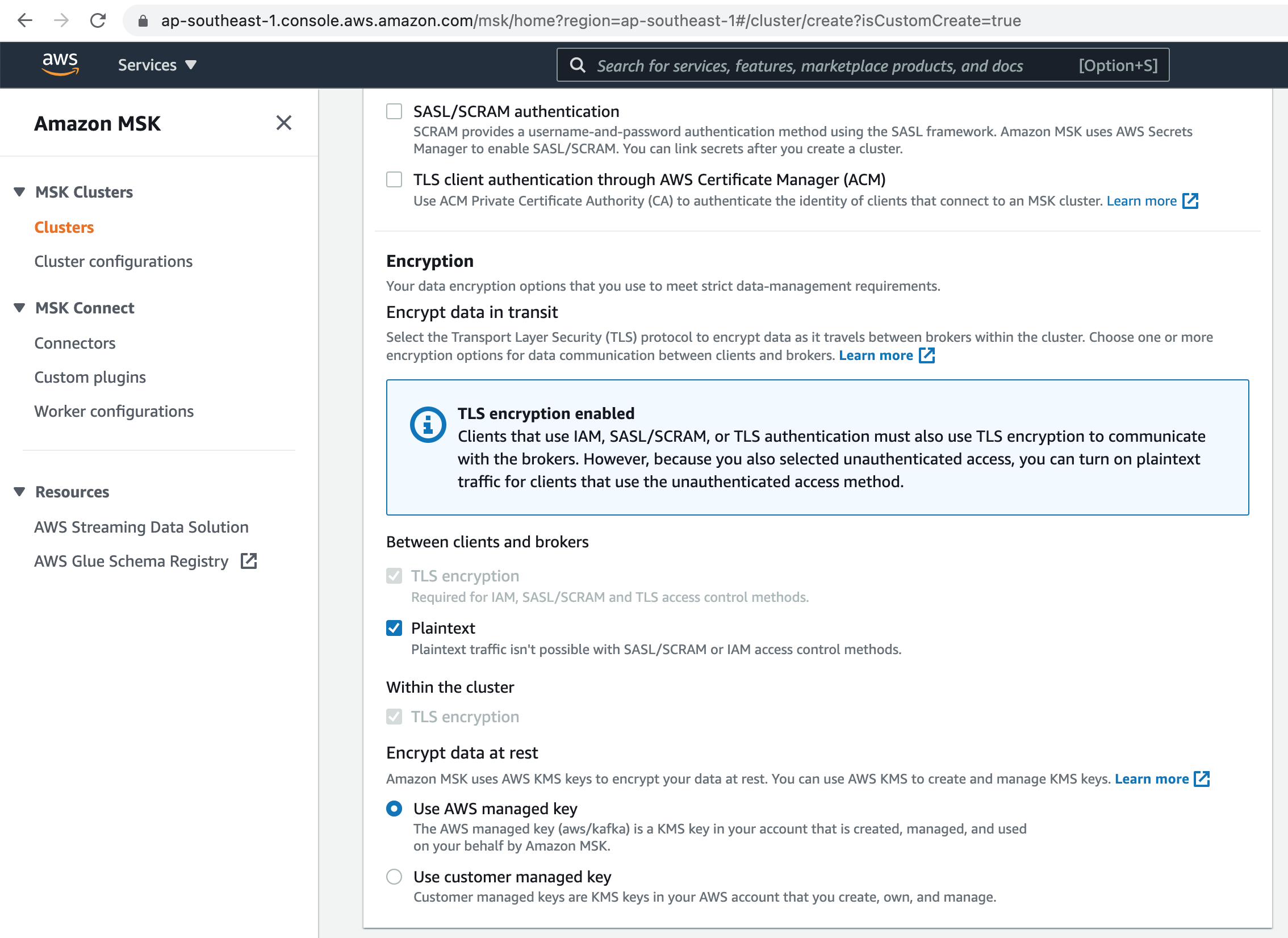
Choose Plaintext as the encryption in transit method for MSK Cluster. Use encryption of data in rest using AWS managed key.
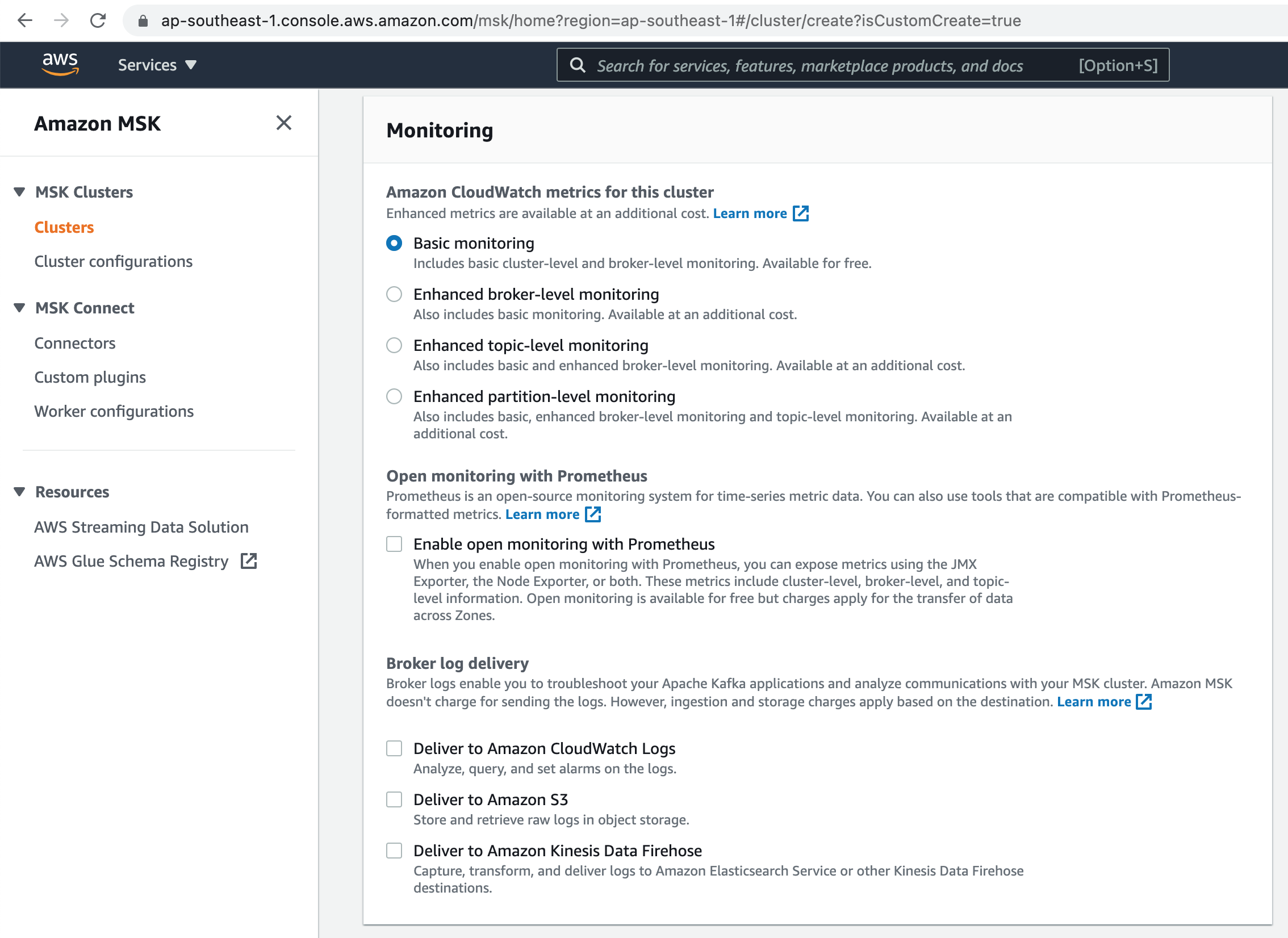
Choose Basic monitoring for our MSK Cluster.
Finally add Tags for management & click on the Create cluster button.
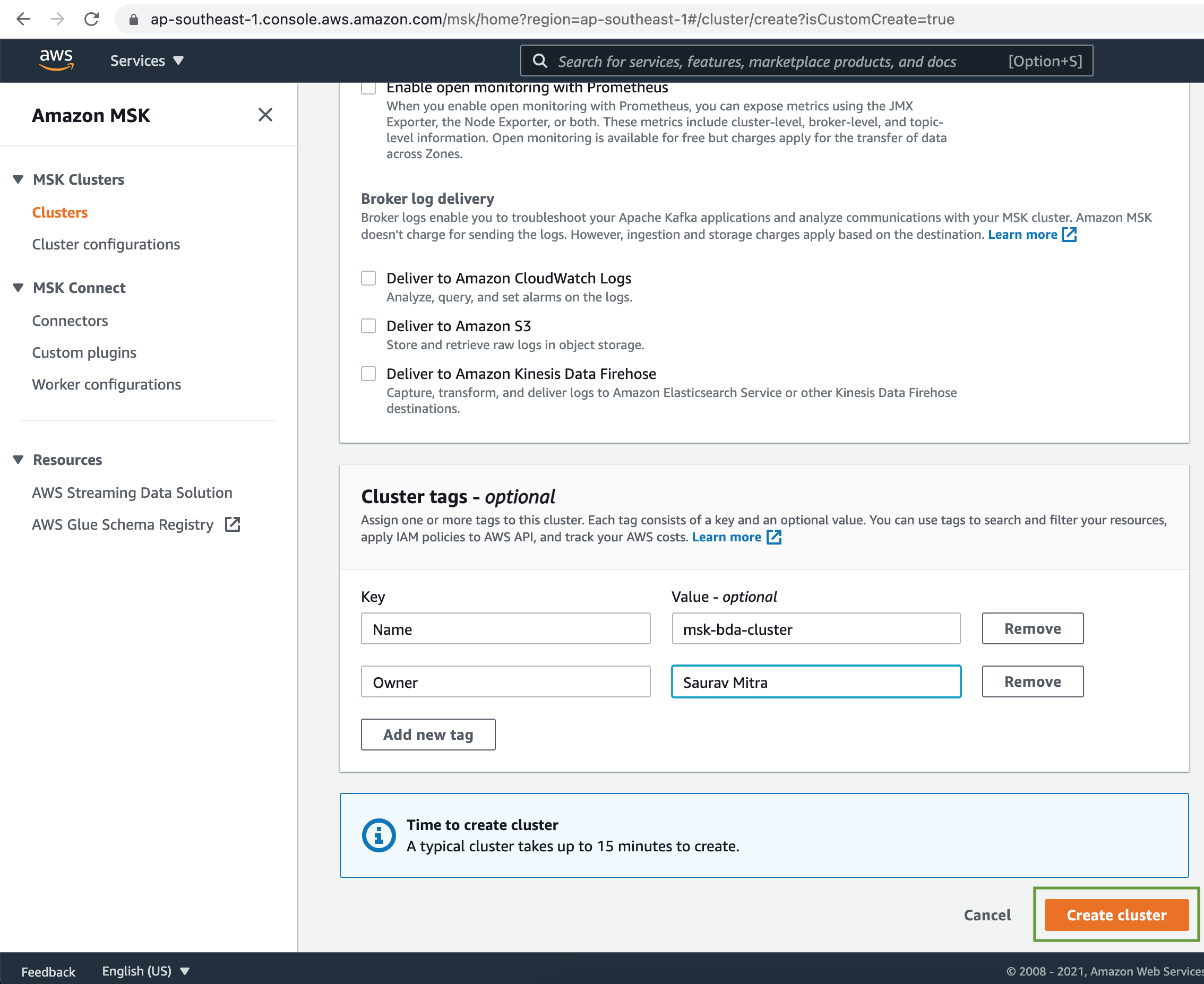
Wait until the Amazon MSK Cluster is ready.
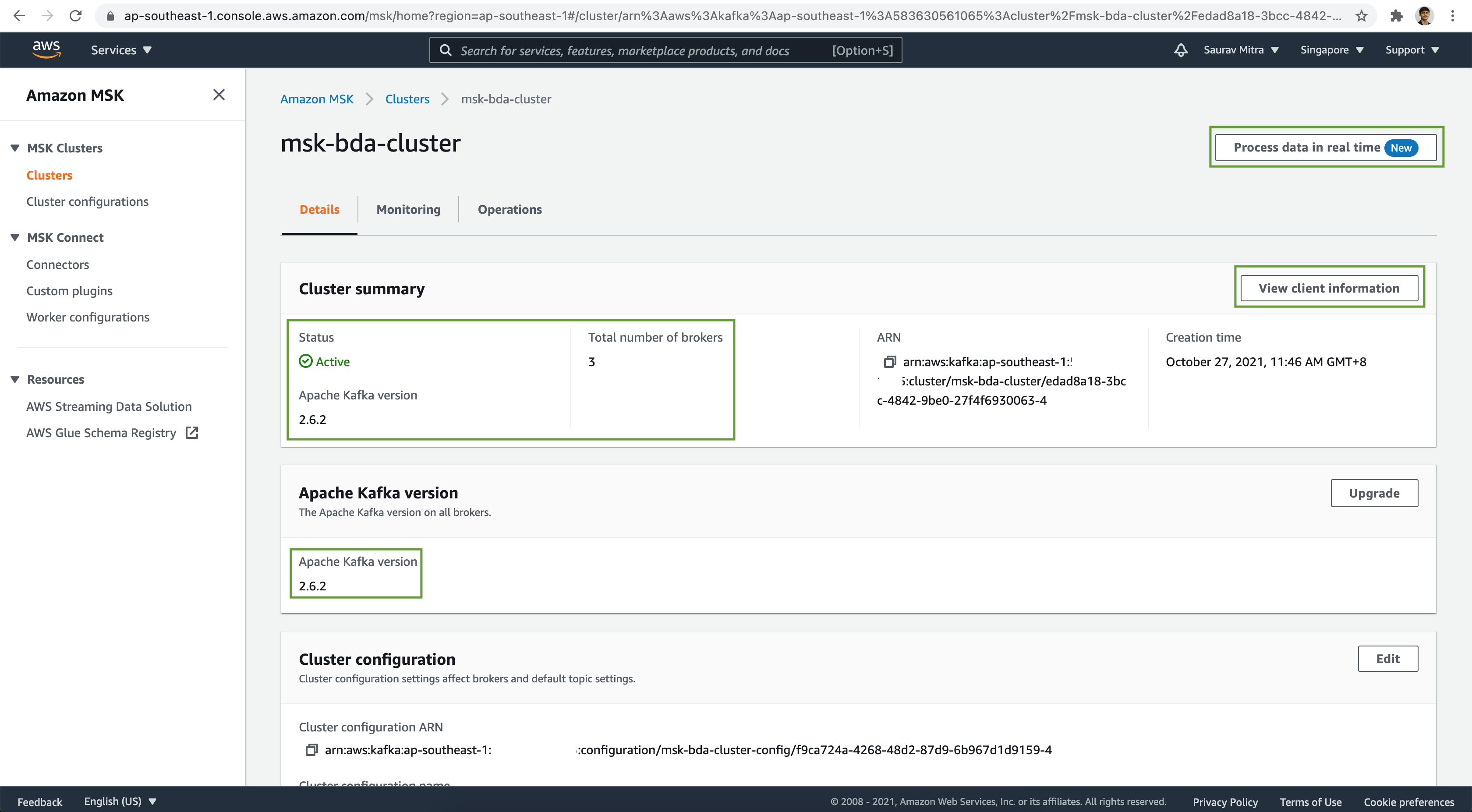
Ingesting Data from Twitter
Set up an EC2 instance to read tweets from Twitter streams and write them to an MSK topic.
The Python script for this process involves using boto3, tweepy, and kafka-python packages
requirements.txt
# Python Packages
boto3
tweepy
kafka-pythontweets.py
import json
import os
import tweepy
from kafka import KafkaProducer
consumer_key = os.environ['CONSUMER_KEY']
consumer_secret = os.environ['CONSUMER_SECRET']
access_token = os.environ['ACCESS_TOKEN']
access_token_secret = os.environ['ACCESS_TOKEN_SECRET']
twitter_filter_tag = os.environ['TWITTER_FILTER_TAG']
bootstrap_servers = os.environ['BOOTSTRAP_SERVERS']
kafka_topic_name = os.environ['KAFKA_TOPIC_NAME']
class StreamingTweets(tweepy.Stream):
def on_status(self, status):
data = {
'tweet_text': status.text,
'created_at': str(status.created_at),
'user_id': status.user.id,
'user_name': status.user.name,
'user_screen_name': status.user.screen_name,
'user_description': status.user.description,
'user_location': status.user.location,
'user_followers_count': status.user.followers_count,
'tweet_body': json.dumps(status._json)
}
response = producer.send(
kafka_topic_name, json.dumps(data).encode('utf-8'))
print((response))
def on_error(self, status):
print(status)
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
stream = StreamingTweets(
consumer_key, consumer_secret,
access_token, access_token_secret
)
stream.filter(track=[twitter_filter_tag])Finally let's proceed to analyze our tweets in the MSK topic.
Real-Time Data Analysis with Apache Flink
Click on the Process data in real time button as seen in the previous image.
With Amazon Kinesis Data Analytics for Apache Flink, we can use Java, Scala, or SQL to process and analyze streaming data to perform time-series analytics, feed real-time dashboards, and create real-time metrics.
We can build Java and Scala applications in Kinesis Data Analytics using open-source libraries based on Apache Flink. Apache Flink is a popular framework and engine for processing data streams.
On the popup window, choose Apache Flick - Studio notebook & click on the Create button.
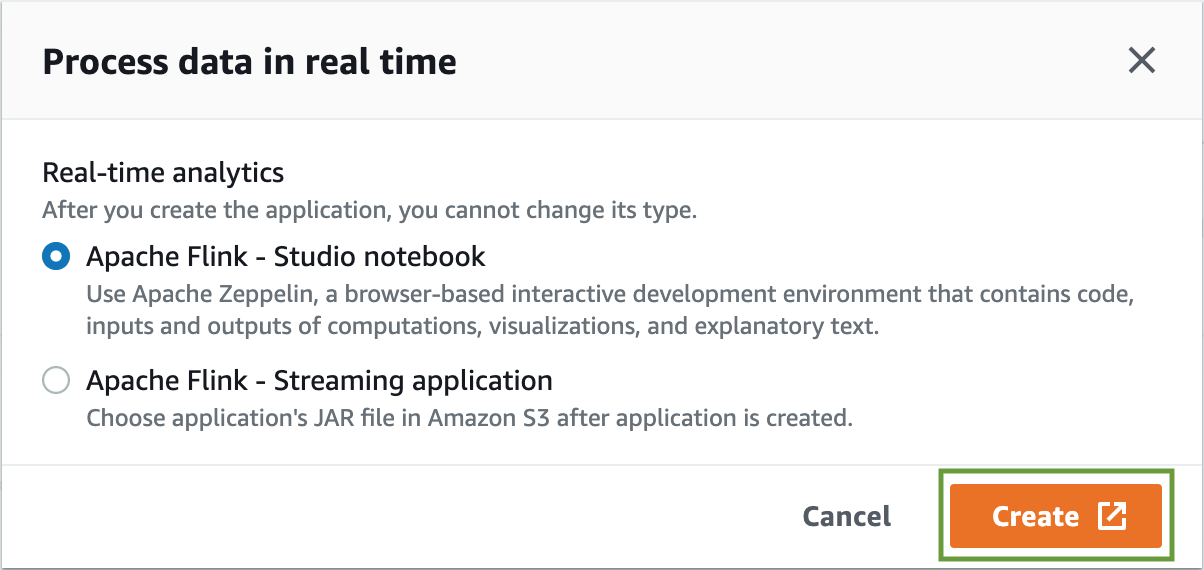
Add a name & description to the Studio Notebook.
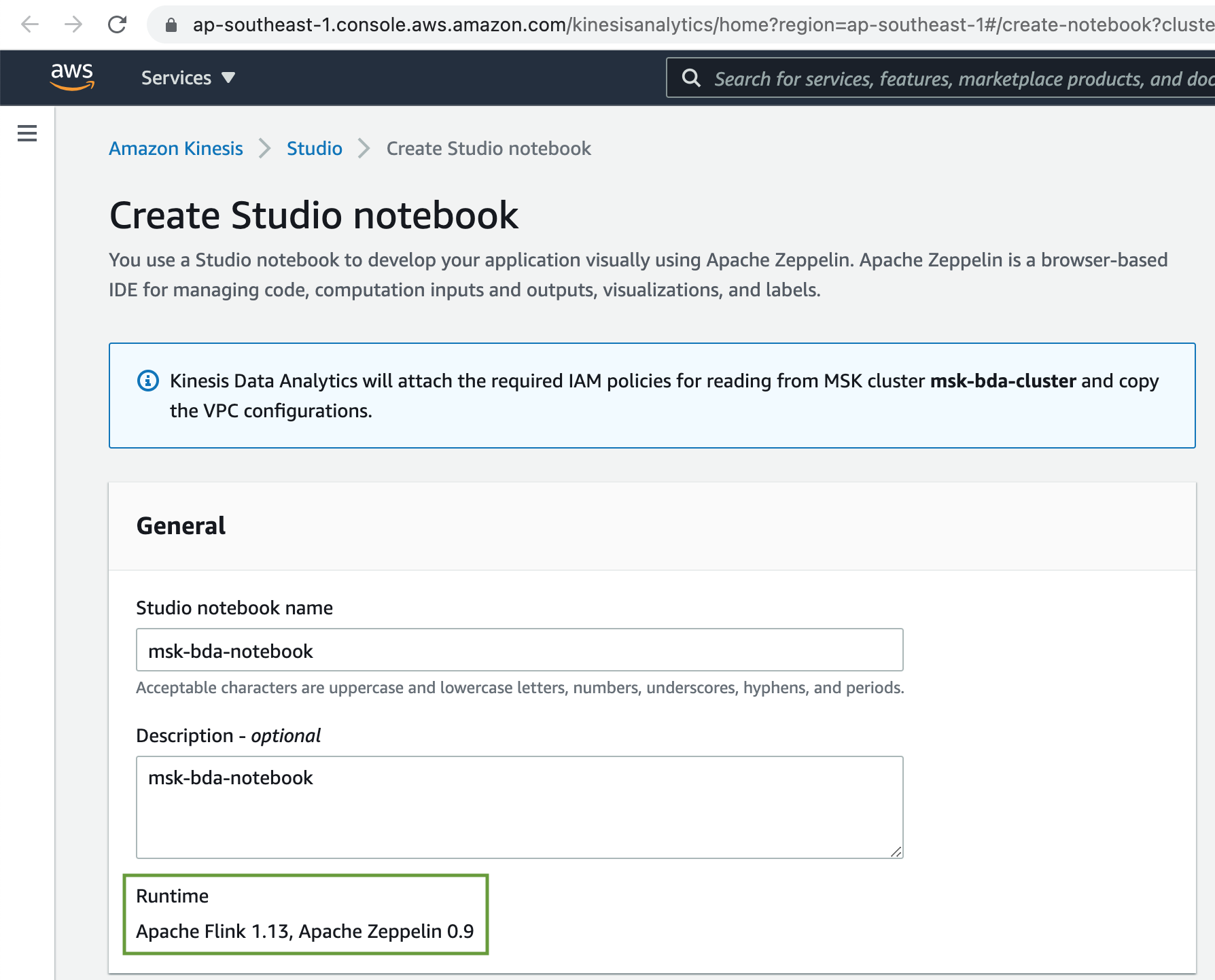
Finally click on the Create Studio notebook button.
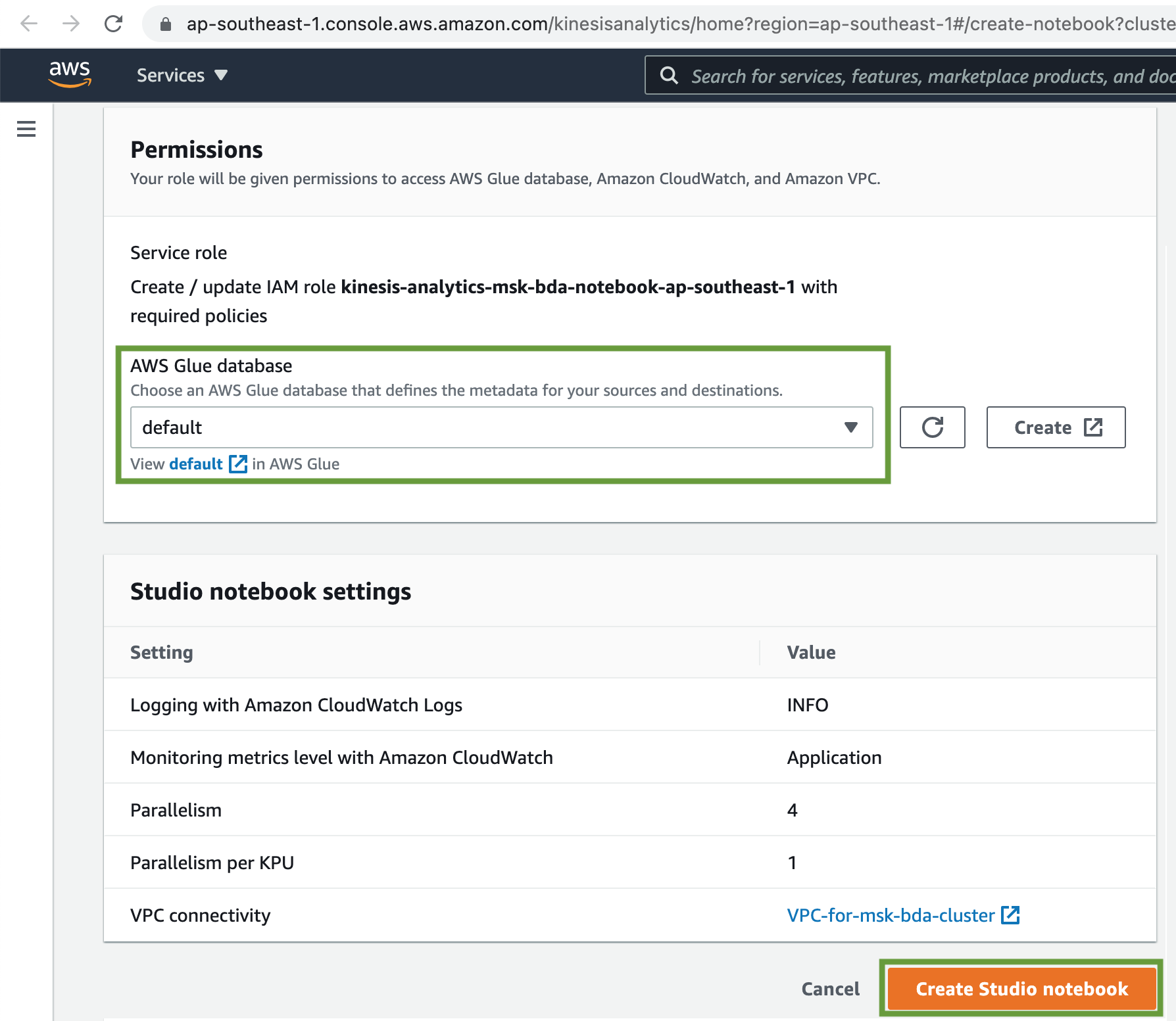
Once the Analytics Studio Notebook is created, click on the Run button to start the Studio notebook.
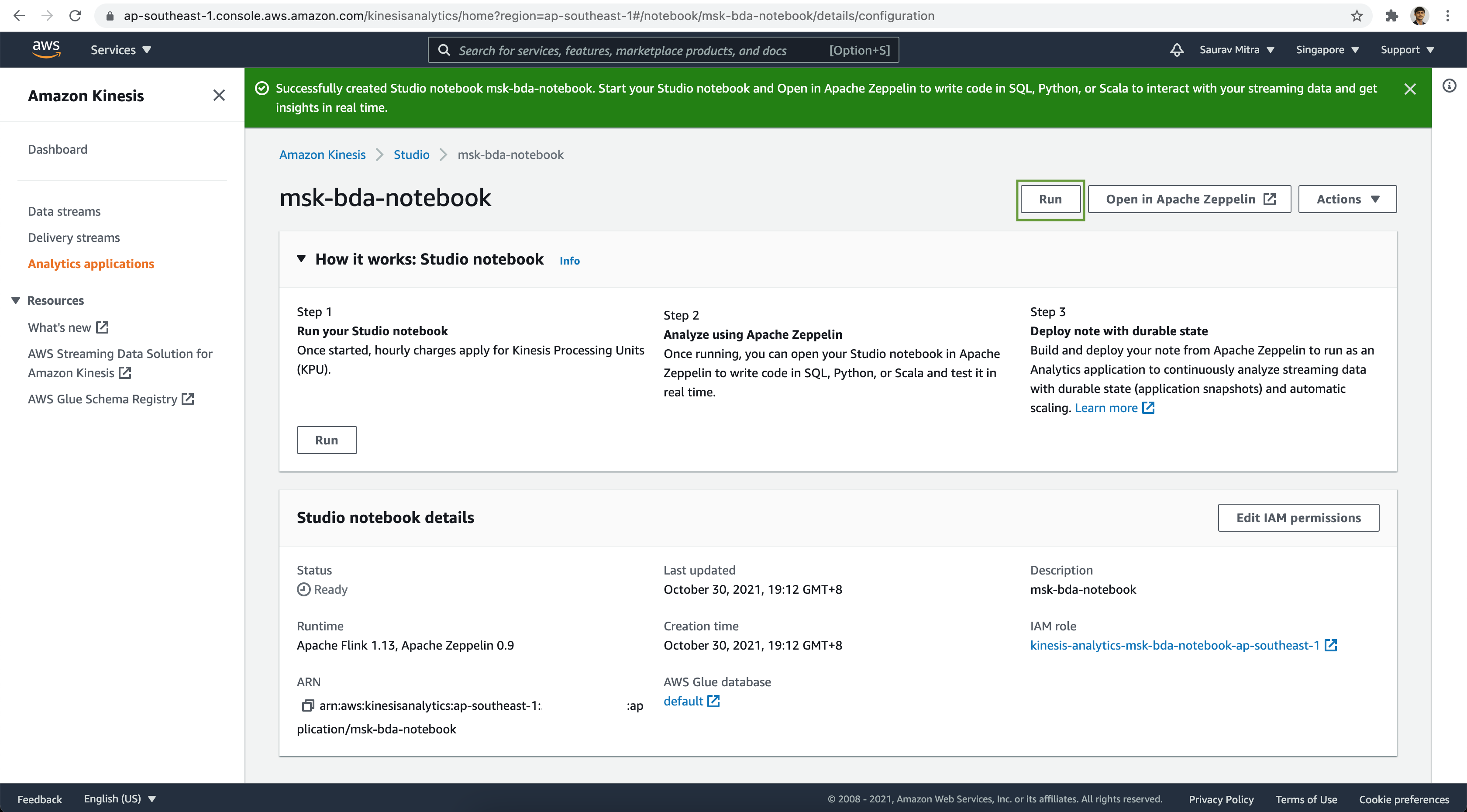
On the confirmation window, click on the Run button.
Now once the Studio Notebook is ready, click on the Open in Apache Zeppelin button.
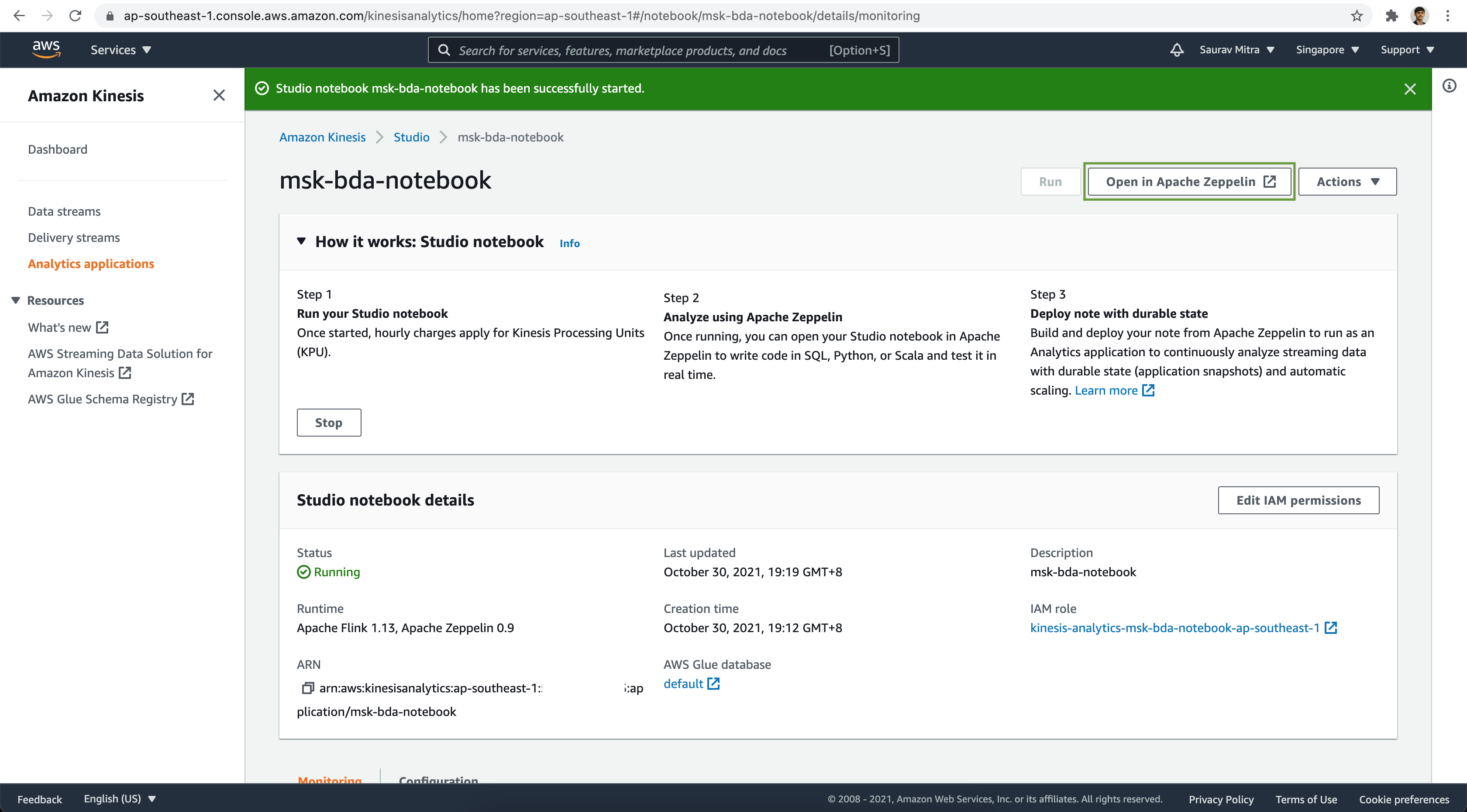
From the Zeppelin Notebook click on the Create new note link.
Add a Note Name and click on the Create button.
Create Flink Table
Next we will create a table on top of the Kafka Topic followed by some analytics.
%flink.ssql(type=update)
CREATE TABLE tweets (
tweet_text VARCHAR(5000),
created_at VARCHAR(30),
user_id BIGINT,
user_name VARCHAR(256),
user_screen_name VARCHAR(256),
user_followers_count INT,
tweet_body VARCHAR(40000),
user_description VARCHAR(256),
user_location VARCHAR(256),
created_at_ts as TO_TIMESTAMP (`created_at`, 'yyyy-MM-dd HH:mm:ssz'),
WATERMARK FOR created_at_ts AS created_at_ts -INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'tweets',
'properties.bootstrap.servers' = 'b-2.msk-bda-cluster.laur9p.c4.kafka.ap-southeast-1.amazonaws.com:9092,b-3.msk-bda-cluster.laur9p.c4.kafka.ap-southeast-1.amazonaws.com:9092,b-1.msk-bda-cluster.laur9p.c4.kafka.ap-southeast-1.amazonaws.com:9092',
'format' = 'json',
'properties.group.id' = 'TweetConsumerGroup',
'scan.startup.mode' = 'earliest-offset'
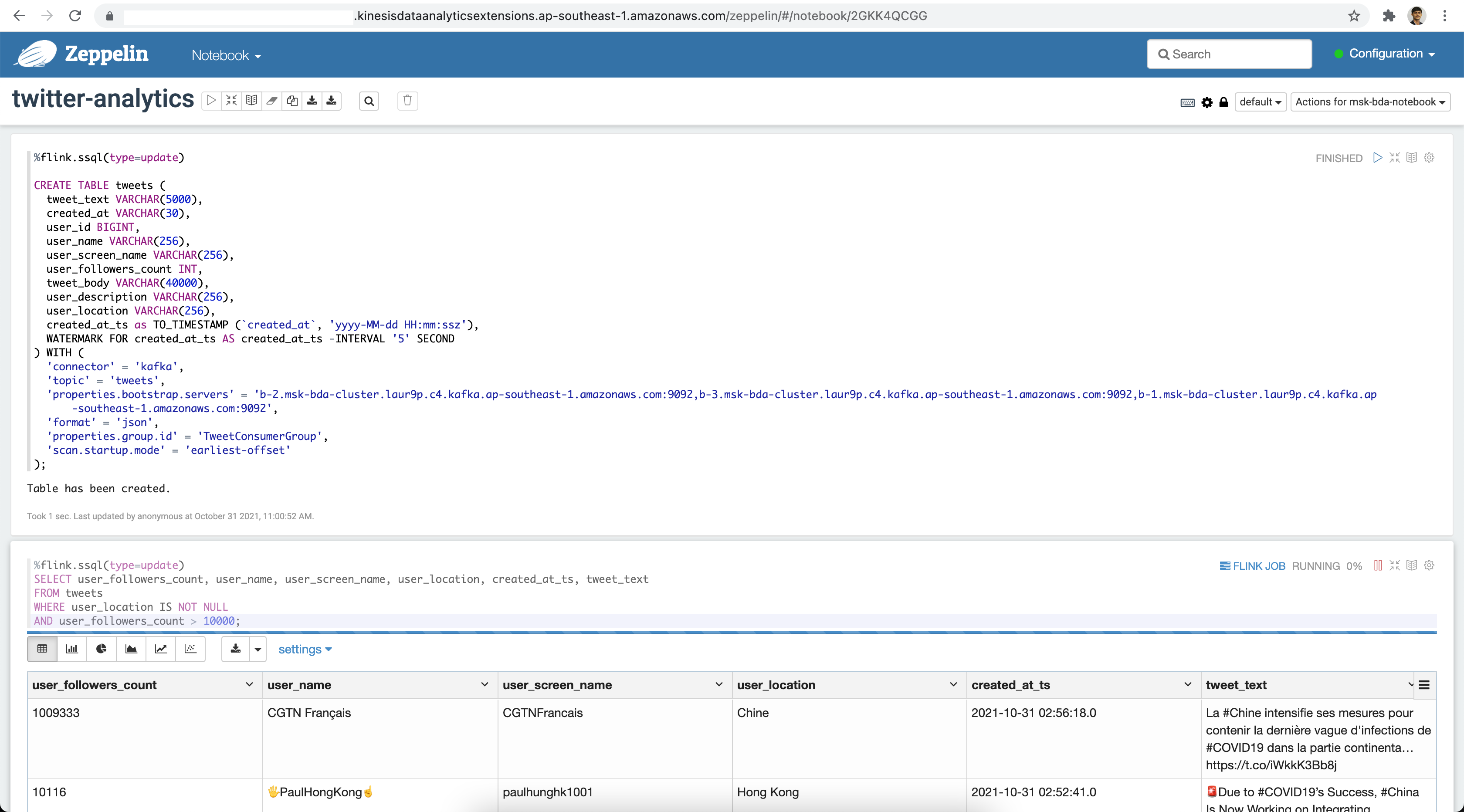
);
Querying Data
Let's perform some query to get the latest tweets from users with more than 1000 followers.
%flink.ssql(type=update)
SELECT user_followers_count, user_name, user_screen_name, user_location, created_at_ts, tweet_text
FROM tweets
WHERE user_location IS NOT NULL
AND user_followers_count > 10000;For aggregating tweet counts:
%flink.ssql(type=update)
SELECT
TUMBLE_ROWTIME(created_at_ts, INTERVAL '60' SECOND) AS window_end,
COUNT(*) AS tweets
FROM tweets
GROUP BY
TUMBLE(created_at_ts, INTERVAL '60' SECOND)
ORDER BY window_end, tweets;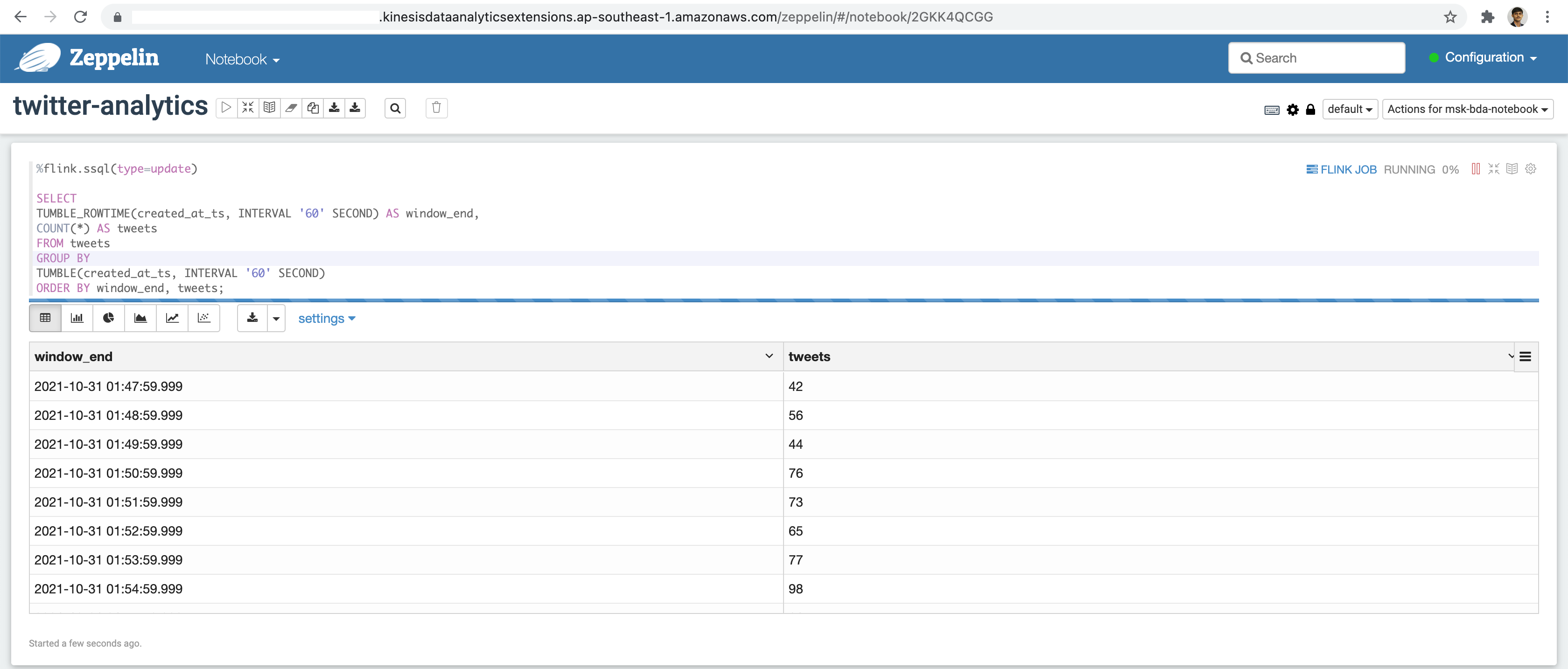
Amazon MSK, coupled with Apache Flink, provides a robust infrastructure for streaming data analytics. By following these steps, you can set up a powerful pipeline to process and analyze real-time data, enabling you to harness the full potential of your streaming data sources.
For automated deployment of the AWS resources using Terraform you may refer https://github.com/sarubhai/aws-big-data-analytics
