
How to implement SCD Type 3 in Data Services

In this tutorial we will learn how to implement Slowly Changing Dimension of Type 3 using SAP Data Services. SCD type 3 design is used to store partial history. Here we are only interested to maintain the "current value" and "previous value" of an attribute. That is, even though the value of that attribute may change numerous times, at any time we are only concerned about its current and previous values.
This article is part of our comprehensive data services tutorial Learning SAP Data Services - Online Tutorial, you may want to check that tutorial first if you have not already done so.
Let us consider we have customer source data with Address details. We are interested to capture only the current and previous address information for each customer. Find below the implementation Data Flow.
Implementation

Lets assume we are using an ETL batch load control table to log the last extraction date for customer records from source.
Next we assign the last extraction date to a global variable to capture the Changed Data from the source.
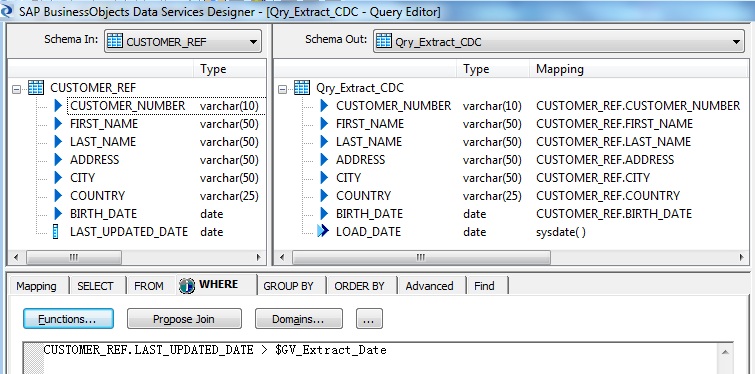
Next we lookup the target dimension table using the source customer key and get the surrogate key, current address from the dimension table as return values from function call lookup_ext.

Next we check if the incoming source record exists in the dimension table or not. If the record does not exist in the dimension table we flag it for INSERT.
If the record exist in the dimension table but the Present address is not same as the current address coming from source system we flag it for UPDATE.
Else we mark the record as REJECT.

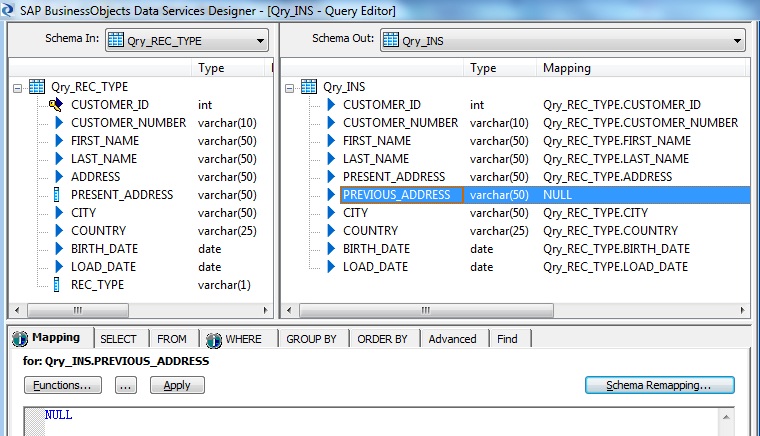
Next for the records marked for Insertion i.e WHERE REC_TYPE='I', we map the PRESENT_ADDRESS to the incoming ADDRESS from the source and make the PREVIOUS_ADDRESS as NULL.
Next we use a Key_Generation transform to generate the surrogate key for the incoming new records from the source and insert into the target Dimension table.

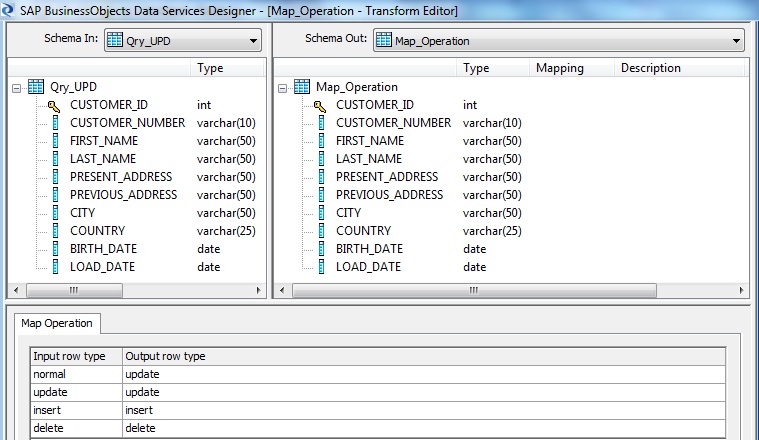
Now for the UPDATE path Query transform for those records marked for Update i.e WHERE REC_TYPE='U', we map the PRESENT_ADDRESS to the incoming ADDRESS from the source. Also we map the PREVIOUS_ADDRESS to the PRESENT_ADDRESS coming from the lookup dimension table.

Next we use a Map_Operation transform to changed the OPCODE for the incoming NORMAL records to type UPDATE and map it to the target dimension table.
This is how our target dimension table data for SCD Type 3 implementation looks like.
