
How to use Data Services Pivot Transformation

In this article, we will learn how to use SAP Data Services Pivot Transform. The Pivot transformation allows us to change how the relationship between rows is displayed. For each value in each pivot column, Data Services produces a row in the output data set. We can create pivot sets to specify more than one pivot columns. It basically convert Columns to Rows.
This article is part of our comprehensive data services tutorial Learning SAP Data Services - Online Tutorial, you may want to check that tutorial first if you have not already done so.
Implementation
Let us consider we have source data of sales for different stores based on quarters. We may want to transform the sales data based on the quarters for each of the stores. Find below the implementation Data Flow.
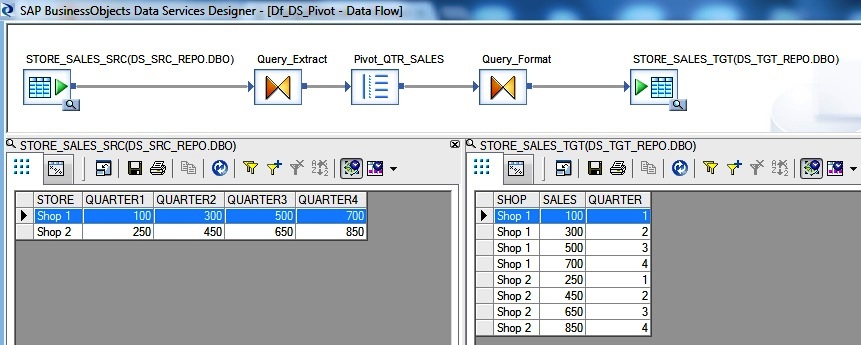
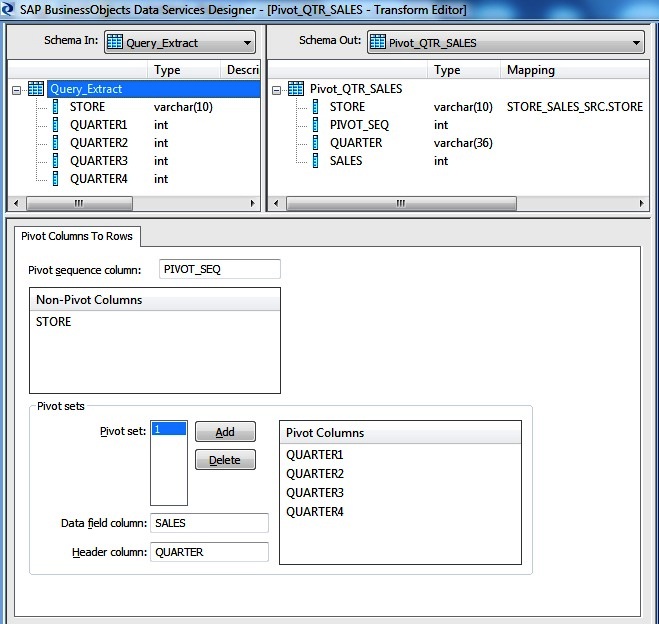
To solve the problem we are using the SAP Data Services Pivot transform. We first set the Pivot sequence column value as PIVOT_SEQ. So the sequence value will be 1 for QUARTER1 column, 2 for QUARTER2 column .. when being transformed to multiple rows. Select the STORE as the Non-Pivoted column. In this example we are dealing with only one Pivot set for QUARTER. Hence the Pivot set is set to 1. Next include all the input QUARTER columns as the Pivot Columns. Set the output Header column name as QUARTER and the corresponding Data fields as SALES.
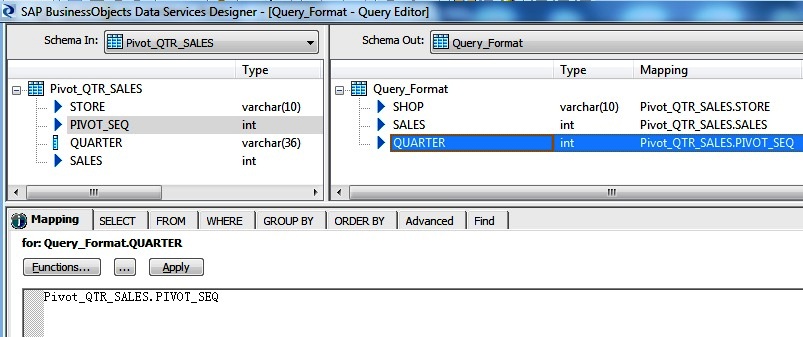
Finally we map the quarter to the Pivot Sequence in the Query transform. So for the first quarter sales value the corresponding QUARTER will be 1 and so on.
Transform Options
- Pivot sequence column : The name we assign to the sequence number column. For each row created from a pivot column, Data Services increments and stores a sequence number. Data Services resets the sequence to 1 when creating an output row from an original row. For example, if the row corresponds to the first pivoted column, the sequence number for the row is 1.
- Non-pivot columns : The input schema columns that appear in the output schema without modification.
- Pivot set : The number that identifies a pivot set. For each pivot set, we need to define a group of pivot columns, a pivot data field, and a pivot header name. Each pivot set must have a unique Data field column and the Header column. Data Services automatically saves this information.
- Pivot columns : A set of columns to be rotated into rows. Describe these columns desired output name in the Header column and corresponding data in these columns in the Data field column.
- Data field column : The name of the column that contains the pivoted data. This column contains all of the Pivot columns values.
- The data type of this column is determined by the data type of Pivot columns. If two or more Pivot columns contains different data types, Data Services converts the columns to a single data type i.e. the data type of the first column we added to the pivot set.
- Header column : The name of the column that contains the pivoted column names. This column lists the names of the source columns where the corresponding data originated.
