
Text Data Processing using SAP Data Services

This article deals with Text Data Processing using SAP Business Objects Data Services with the intension of Text Analytics. SAP BODS provides a single ETL platform for both Structured and Unstructured data as well as Data Quality, Data Profiling and Data Cleansing functionalities.Entity Extraction transform available as a part of Text Data Processing of Data Services, helps to extract entities, entity relationships and facts from unstructured data for downstream analytics. The transform performs linguistic processing on content by using semantic and syntactic knowledge of words, to identify paragraphs, sentences, clauses, entities and facts from textual information.
Base_EntityExtraction Transform
This transform provides a user friendly GUI interface, having three tabs namely Input, Options and Output. The transform accepts textual format such as a text, HTML, or XML. We need to specify explicitly the language for processing the text content. Entity extraction is performed with the help of in-built SYSTEM source or user defined DICTIONARY or RULE to filter specific entities as output.
Text Data Processing
Let's see the basic feature of this transform using a small example. Later we will manipulate the entity extraction further using Dictionary and Rule.
1. Create a New File Format with file type as Unstructured text.
- Next define the Root directory to specify the file location.
- Enter the File name(s) to process. Also we can use wild-character in this placeholder as *.*. This will process all the textual files present in the directory for entity extraction.
- Other properties like Read subfolders and Skip empty files by default are set to Yes.
- Additionally at the dataflow level we have the option to provide value for the Number of files to read. By default this is set to {None}.
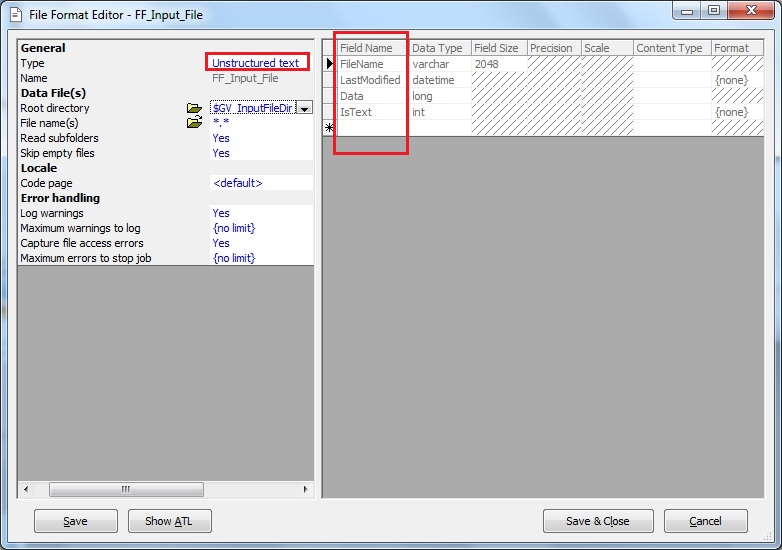
Next take a look at the default fields created for the file format. Four fields have been generated automatically namely FileName, LastModified, Data and IsText. Here the FileName field will extract the absolute file names to be processed in the Data Files directory.The Data field will actually extract the entire content of the file as long format.
2. Next in the dataflow, place a Base_EntityExtraction transform of Data Services, after the unstructured file format. Link the transform with the file format.

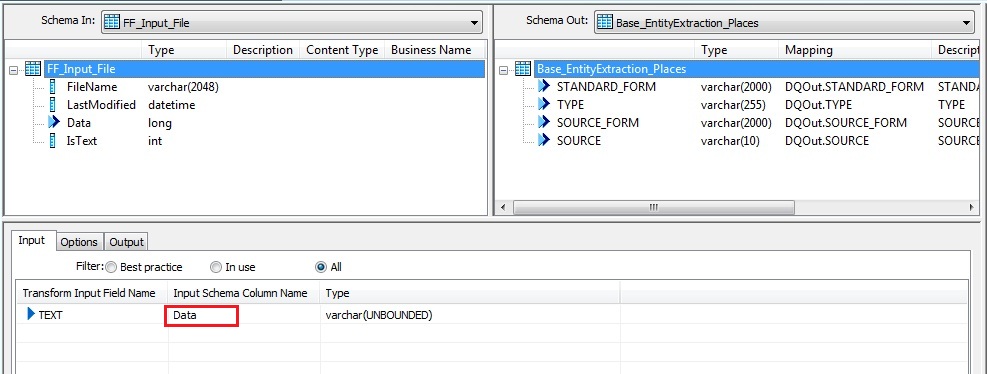
3. Next in the Input tab of the transform, drag and drop the Data column of the input schema to the Input Schema Column Name so as to map with the Transform Input Field Name TEXT.
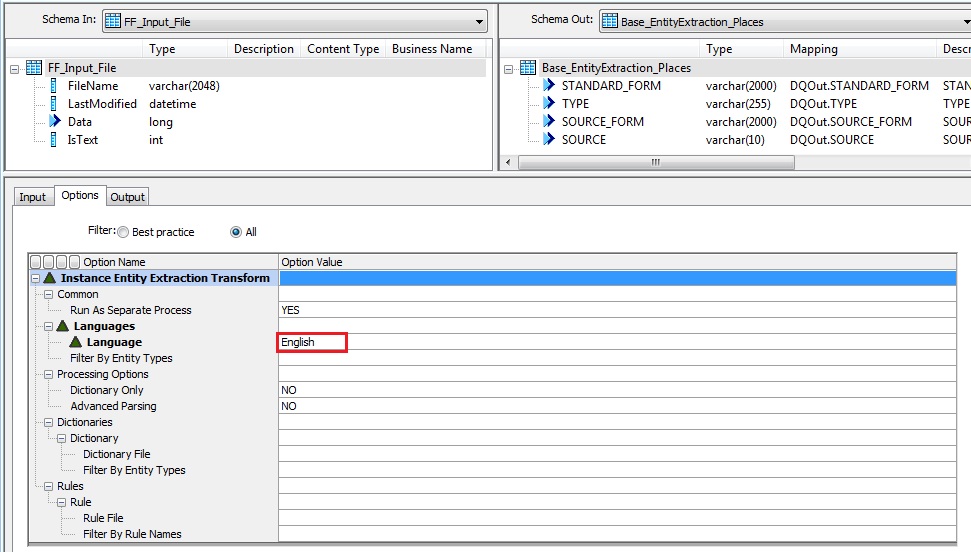
4. Check the Options tab and set the Language value accordingly, in my case English. Leave the rest of the options as it is. Later we will deal with Dictionary File and Rules.
5. On the Output tab select the fields of interest. Best practice deals with only the fields STANDARD_FORM and TYPE. By default the output schema of the transform will generate a maximum of 11 fields. We can use them if we want.

Typically our interest will be on the fields TYPE, SOURCE, SOURCE_FORM and STANDARD_FORM. Sample output contents of these fields are as below:
- STANDARD_FORM: Intel Corporation, 200 USD, 2009-11-25
- SOURCE_FORM: Intel Corp, $200, Nov. 25, 2009
- TYPE: Action, Address, BuyEvent, Organization, Phone, Price, PRODUCT, CURRENCY, DATE, TIME
- SOURCE: SYSTEM, DICTIONARY, RULE
6. Next we just add a Template Table as target. Run the job and let's check the meaningful text data extracted by the transform.
Please find the input text data file and the output dataset generated as screenshots below:
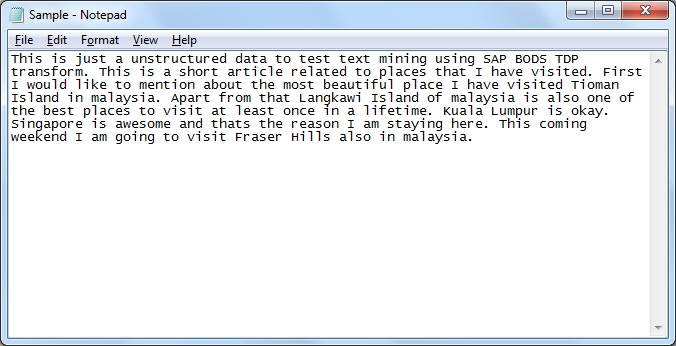
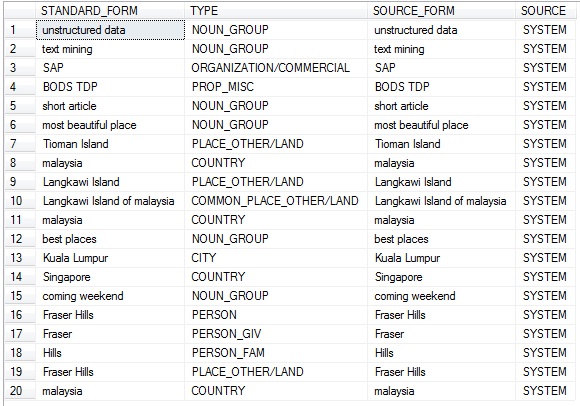
Also a little bit of analysis, to know places of interest as in the textual data:
SELECT STANDARD_FORM
FROM STG_UNSTRUCT_DATA
WHERE TYPE IN
('COUNTRY', 'CITY', 'PLACE_OTHER/LAND', 'COMMON_PLACE_OTHER/LAND')
Next we will learn how to create and use Dictionary and Rule to filter the entities of interest during extraction from the unstructured source data file.
