
Data Services Scenario Questions Part 6

In this tutorial we will discuss some scenario based questions and their solutions using SAP Data Services. This article is meant mainly for Data Services beginners.
This article is one of the series of articles written to showcase the solutions of different business scenarios in SAP Data Services. You may browse all the scenarios from the below list.
- Cumulative Sum of salaries, department wise
- Getting the value from the previous row in the current row
- Getting the value from the next row in the current row
- Getting total Sum of a value in every row
- Cumulative String Concatenation (Aggregation of string)
- Cumulative String Aggregation partition by other column
- String Aggregation
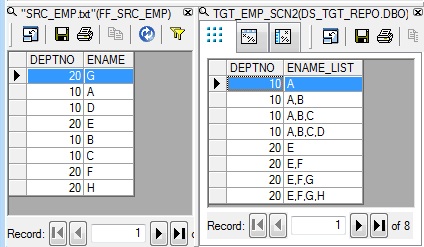
Scenario 6: With reference to the previous department-employee source file, lets try to load the target table data as below:
| DEPTNO | ENAME_LIST |
| 10 | A |
| 10 | A,B |
| 10 | A,B,C |
| 10 | A,B,C,D |
| 20 | E |
| 20 | E,F |
| 20 | E,F,G |
| 20 | E,F,G,H |
Solution:
1. Let us reuse the File Format as defined in the previous example( Scenario 5 ) as Source.
2. Next we use the same Batch Job, JB_SCENARIO_DS. Within the Job we create a Data Flow, say DF_SCENARIO_6.
3. At the Data flow level i.e. Context DF_SCENARIO_6, we Insert two Parameter using the Definitions tab. Let's name them as $PREV_NAME and $PREV_DEPT. Their Data types being varchar(100) and int respectively and Parameter type as Input.
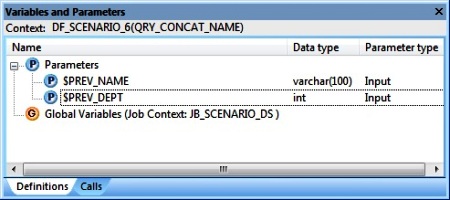
At the Job level i.e. Context JB_SCENARIO_6, we initialize the Parameters $PREV_NAME and $PREV_DEPT using the Calls tab. We set both the Agrument values to NULL.
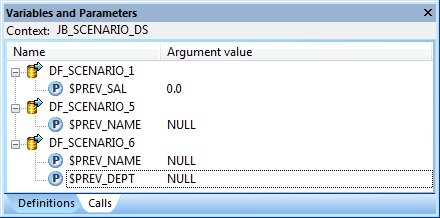
4. Next we create a New Custom Function from the Local Object Library. Let's name it CF_CONCAT_ENAME_BY_DEPT. Within the Custom Function Smart Editor, first we define four Parameters as below:
| Parameter Name | Parameter Type | Data type |
| $CURR_DEPT | Input | int |
| $PREV_DEPT | Input/Output | int |
| $CURR_NAME | Input | varchar(20) |
| $PREV_NAME | Input/Output | varchar(20) |
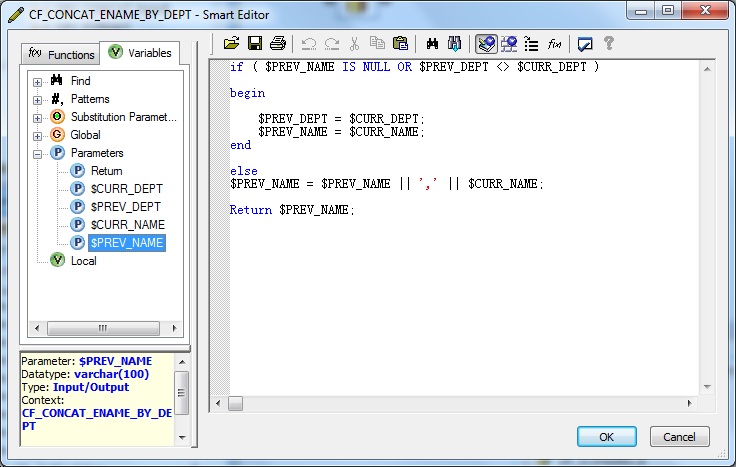
Also we modify the Return Parameter Data type to varchar(100).
5. Next we define the custom function as below and Validate the same.
if ( $PREV_NAME IS NULL OR $PREV_DEPT <> $CURR_DEPT )
begin
$PREV_DEPT = $CURR_DEPT;
$PREV_NAME = $CURR_NAME;
end
else
$PREV_NAME = $PREV_NAME || ',' || $CURR_NAME;
Return $PREV_NAME;The purpose of defining the Parameter and Custom Function is to perform Parameter Short-circuiting. Here within the function, we basically set the $PREV_NAME Parameter of type Input/Output to concatenate all employee names till the current processing row. Since it is of type Input/Output the concatenated string value is passed back into the Dataflow Parameter. Also in this scenario, for change in department we reinitialize the concatenated string. So by using Custom Function we can modify and pass values to a Dataflow Parameter. Hence the Parameter defined at Dataflow level is short-circuited with the Input/Output Parameter of the Custom Function.
6. Let's go back and design the Data flow. First of all we take the File Format defined earlier, from the Local Object Library as Source.

7. Next we place a Query transform, say QRY_SORT. First we select the columns DEPTNO and ENAME from the Schema In of the Query transform and Map to Output. Specify the ORDER BY on DEPTNO and ENAME in Ascending type.
8. Next we place a Query transform, say QRY_CONCAT_NAME. First we select the columns DEPTNO from the Schema In of the Query transform and Map to Output.
Next we specify a New Function Call in Schema Out of the Query transform. Choose the Custom Functions from the Function categories and select the Function name CF_CONCAT_ENAME_BY_DEPT.
Next we Define Input Parameters. We specify the inputs as below:
$CURR_DEPT = QRY_SORT.DEPTNO
$PREV_DEPT = $PREV_DEPT
$CURR_NAME = QRY_SORT.ENAME
$PREV_NAME = $PREV_NAME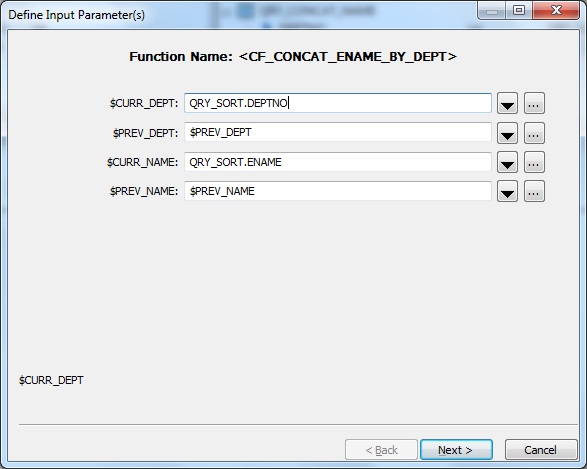
Select the Return column as the Output Parameter.
9. Next we place a Query transform, say QRY_FORMAT. First we select the columns DEPTNO and Return from the Schema In of the Query transform and Map to Output. Rename the Return column to ENAME_LIST.
10. Finally we place a Template Table as Target in the Target Datastore.
Click here to read the next scenario - String Aggregation.
