
Top 50 Data Warehousing/Analytics Interview Questions and Answers

This article attempts to explain the rudimentary concepts of data warehousing in the form of typical data warehousing interview questions along with their standard answers. After reading this article, you should gain good amount of knowledge on various concepts of data warehousing.
Let us begin with the most simplest questions first, we will gradually move towards more complex concepts later.
What is data warehouse?
A data warehouse is a electronic storage of an Organization's historical data for the purpose of Data Analytics, such as reporting, analysis and other knowledge discovery activities.
Other than Data Analytics, a data warehouse can also be used for the purpose of data integration, master data management etc.
According to Bill Inmon, a datawarehouse should be subject-oriented, non-volatile, integrated and time-variant.
Explanatory Note
Non-volatile means that the data once loaded in the warehouse will not get deleted later. Time-variant means the data will change with respect to time.
The above definition of the data warehousing is typically considered as "classical" definition. However, if you are interested, you may want to read the article - What is a data warehouse - A 101 guide to modern data warehousing - which opens up a broader definition of data warehousing.
What is meant by Data Analytics?
Data analytics (DA) is the science of examining raw data with the purpose of drawing conclusions about that information. A data warehouse is often built to enable Data Analytics
What are the benefits of data warehouse?
A data warehouse helps to integrate data (see Data integration) and store them historically so that we can analyze different aspects of business including, performance analysis, trend, prediction etc. over a given time frame and use the result of our analysis to improve the efficiency of business processes.
Why Data Warehouse is used?
For a long time in the past and also even today, Data warehouses are built to facilitate reporting on different key business processes of an organization, known as KPI. Today we often call this whole process of reporting data from data warehouses as "Data Analytics". Data warehouses also help to integrate data from different sources and show a single-point-of-truth values about the business measures (e.g. enabling Master Data Management).
Data warehouse can be further used for data mining which helps trend prediction, forecasts, pattern recognition etc. Check this article to know more about data mining
What is the difference between OLTP and OLAP?
OLTP is the transaction system that collects business data. Whereas OLAP is the reporting and analysis system on that data.
OLTP systems are optimized for INSERT, UPDATE operations and therefore highly normalized. On the other hand, OLAP systems are deliberately denormalized for fast data retrieval through SELECT operations.
Explanatory Note
In a departmental shop, when we pay the prices at the check-out counter, the sales person at the counter keys-in all the data into a "Point-Of-Sales" machine. That data is transaction data and the related system is a OLTP system.
On the other hand, the manager of the store might want to view a report on out-of-stock materials, so that he can place purchase order for them. Such report will come out from OLAP system.
What is data mart?
Data marts are generally designed for a single subject area. An organization may have data pertaining to different departments like Finance, HR, Marketing etc. stored in data warehouse and each department may have separate data marts. These data marts can be built on top of the data warehouse.
What is ER model?
ER model or entity-relationship model is a particular methodology of data modeling wherein the goal of modeling is to normalize the data by reducing redundancy. This is different than dimensional modeling where the main goal is to improve the data retrieval mechanism.
What is dimensional modeling?
Dimensional model consists of dimension and fact tables. Fact tables store different transactional measurements and the foreign keys from dimension tables that qualifies the data. The goal of Dimensional model is not to achieve high degree of normalization but to facilitate easy and faster data retrieval.
Ralph Kimball is one of the strongest proponents of this very popular data modeling technique which is often used in many enterprise level data warehouses.
If you want to read a quick and simple guide on dimensional modeling, please check our Guide to dimensional modeling.
What is dimension?
A dimension is something that qualifies a quantity (measure).
For an example, consider this: If I just say… “20kg”, it does not mean anything. But if I say, "20kg of Rice (Product) is sold to Ramesh (customer) on 5th April (date)", then that gives a meaningful sense. These product, customer and dates are some dimension that qualified the measure - 20kg.
Dimensions are mutually independent. Technically speaking, a dimension is a data element that categorizes each item in a data set into non-overlapping regions.
What is Fact?
A fact is something that is quantifiable (Or measurable). Facts are typically (but not always) numerical values that can be aggregated.
What are additive, semi-additive and non-additive measures?
Non-additive Measures
Non-additive measures are those which can not be used inside any numeric aggregation function (e.g. SUM(), AVG() etc.). One example of non-additive fact is any kind of ratio or percentage. Example, 5% profit margin, revenue to asset ratio etc. A non-numerical data can also be a non-additive measure when that data is stored in fact tables, e.g. some kind of varchar flags in the fact table.
Semi Additive Measures
Semi-additive measures are those where only a subset of aggregation function can be applied. Let’s say account balance. A sum() function on balance does not give a useful result but max() or min() balance might be useful. Consider price rate or currency rate. Sum is meaningless on rate; however, average function might be useful.
Additive Measures
Additive measures can be used with any aggregation function like Sum(), Avg() etc. Example is Sales Quantity etc.
At this point, I will request you to pause and make some time to read this article on "Classifying data for successful modeling". This article helps you to understand the differences between dimensional data/ factual data etc. from a fundamental perspective
What is Star-schema?
This schema is used in data warehouse models where one centralized fact table references number of dimension tables so as the keys (primary key) from all the dimension tables flow into the fact table (as foreign key) where measures are stored. This entity-relationship diagram looks like a star, hence the name.
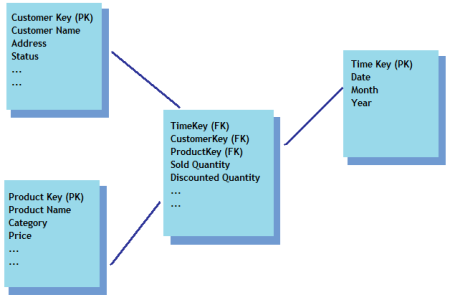
Consider a fact table that stores sales quantity for each product and customer on a certain time. Sales quantity will be the measure here and keys from customer, product and time dimension tables will flow into the fact table.
If you are not very familiar about Star Schema design or its use, we strongly recommend you read our excellent article on this subject - different schema in dimensional modeling
What is snow-flake schema?
Continue to next page of Top Data Warehousing Interview Questions (Page 2) >>
Sample Questions from next page ...
1. What is snow-flake schema?
2. What are the different types of dimension?
3. What is junk dimension?
4. What is a mini dimension? Where is it used?
5. What is fact-less fact and what is coverage fact?
... And many more high frequency questions!
