
Data Services Flatfiles Tips

Often we come across scenarios where we have the flat file definition in an excel sheet and we need to create corresponding File Format in SAP Data Services. Alternatively we import file format definition from a Sample Source file.
But based on the first 20 records SAP Data Services tries to give the best Data types of the input columns from the flat file. In most of the cases we need to modify the datatype, length or their precision.
Creating New FileFormat
Now consider the scenario when the number of columns is high; Altering data types manually is a real pain. So let us try to play with Metadata. A simple solution to all problems.
So let us assume that, we have the File Location, File Name, Field Name, Datatype with Field Size, Precision and Scale information with us. So just we need to modify the below code to generate the required Flat File Format.
- So first of all open an editor and copy the below code and paste it.
- Next modify all the lines marked in BOLD with the information as per your requirement.
- After alteration save the file to a desired location with .ATL extension.
- Next from SAP Data Services Designer, Go to Tools and select Import From File
- Next select the ATL file and click Open.
- Click Yes to continue import.
- Leave the passphare blank and click Import
- Click OK to continue with warning.
ATL Metadata Code
ALGUICOMMENT( x = '-1', y = '-1', UpperContainer_HeightProp = '43', InputSchema_WidthProp = '50', Input_Width_Description = '130', Output_Width_Decsription = '130', Input_Width_Type = '85', Output_Width_Type = '80', Output_Width_Mapping = '85', Input_Column_Width_3 = '100', Output_Column_Width_4 = '100', Input_Column_Width_4 = '100', Output_Column_Width_5 = '100', Input_1st_Column_Name = 'Type', Input_2nd_Column_Name = 'Description', Input_Column_Name_3 = 'Content_Type', Input_Column_Name_4 = 'Business_Name', Output_1st_Column_Name = 'Type', Output_2nd_Column_Name = 'Mapping', Output_3rd_Column_Name = 'Description', Output_Column_Name_4 = 'Content_Type', Output_Column_Name_5 = 'Business_Name' )
CREATE FILE DATASTORE FF_MyFileFormat(
EMPNO INT,
ENAME VARCHAR(50),
SAL DOUBLE,
ADDR VARCHAR(70),
DOB DATE,
COMM DECIMAL(10, 3))
SET ("abap_file_format" = 'no',
"blank_pad" = 'leading',
"blank_trim" = 'leading',
"cache" = 'yes',
"column_delimiter" = '\\t',
"column_width" = '1',
"column_width1" = '1',
"column_width2" = '50',
"column_width3" = '1',
"column_width4" = '70',
"column_width5" = '1',
"column_width6" = '1',
"date_format" = 'yyyy.mm.dd',
"datetime_format" = 'yyyy.mm.dd hh24:mi:ss',
"file_format" = 'ascii',
"file_location" = 'local',
"file_name" = 'MyFile.txt',
"file_type" = 'delimited_file',
"locale_codepage" = '<default>',
"locale_language" = '<default>',
"locale_territory" = '<default>',
"name" = 'UNNAMED',
"read_subfolders" = 'yes',
"reader_capture_data_conversion_errors" = 'no',
"reader_capture_file_access_errors" = 'yes',
"reader_capture_row_format_errors" = 'yes',
"reader_log_data_conversion_warnings" = 'yes',
"reader_log_row_format_warnings" = 'yes',
"reader_log_warnings" = 'yes',
"reader_maximum_warnings_to_log" = '-99',
"reader_skip_empty_files" = 'yes',
"reader_write_error_rows_to_file" = 'no',
"root_dir" = 'E:\\POC\\',
"row_delimiter" = '\\n',
"table_weight" = '0',
"time_format" = 'hh24:mi:ss',
"transfer_custom" = 'no',
"use_root_dir" = 'no',
"write_bom" = 'no' );Points to Remember
- First of all modify the File Format DataStore name in my case it is FF_MyFileFormat
- Next add the Field Definition section, i.e. Field Name and Data Type, Field Size, Precision and Scale.
- Modify the Column Delimiter of the file format metadata. In my case its Tab \\t
- Next modify the Width section of the file format metadata after column delimiter section.
- Keep "column_width" = '1', as it is. Do not change.
- Going forward "column_width1" signifies our first field, "column_width2" signifies second field width.
- Only set the width for the VARCHAR Data Types corresponding to their Field Size.
- Rest for all the other Data Type Fields put the column_width as 1
- Next modify the "file_name". In my case it is 'MyFile.txt'
- Lastly modify the File Location i.e the "root_dir". In my case it is 'E:\\POC\\'
Flexibility Like Template Table
Template Table in SAP Data Services provides a lot of flexibility as we all know. Similarly we can also create file format with a single button click. SAP Data Services supports File Format Creation for almost all the Transforms in a Data Flow.
So just open any transform, select either the Schema-In or Schema-Out Name and Right-Click and select Create File Format.
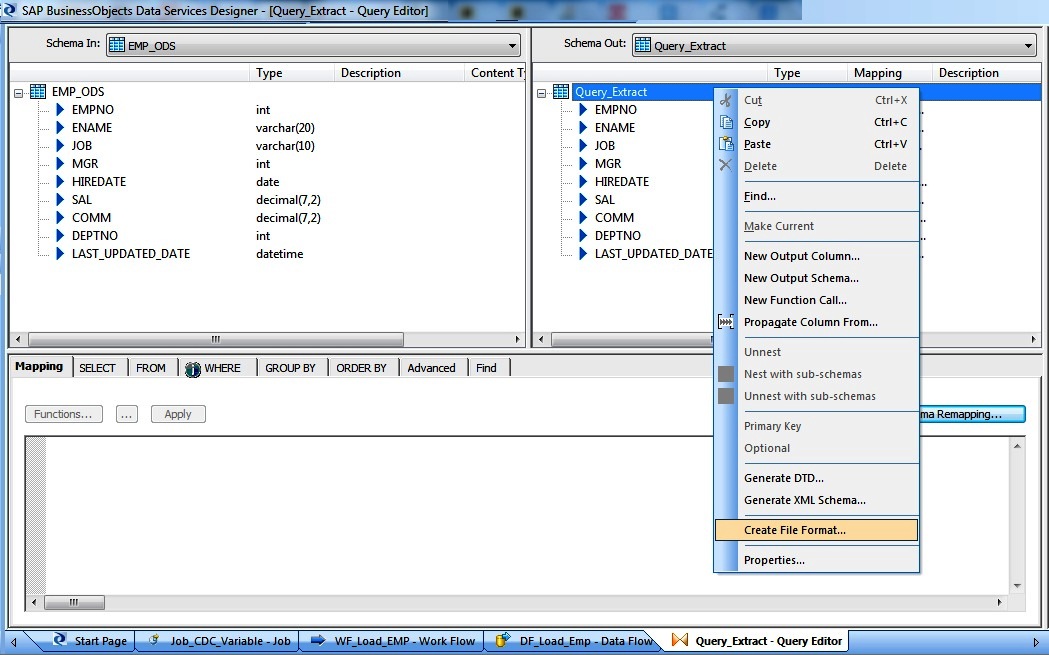
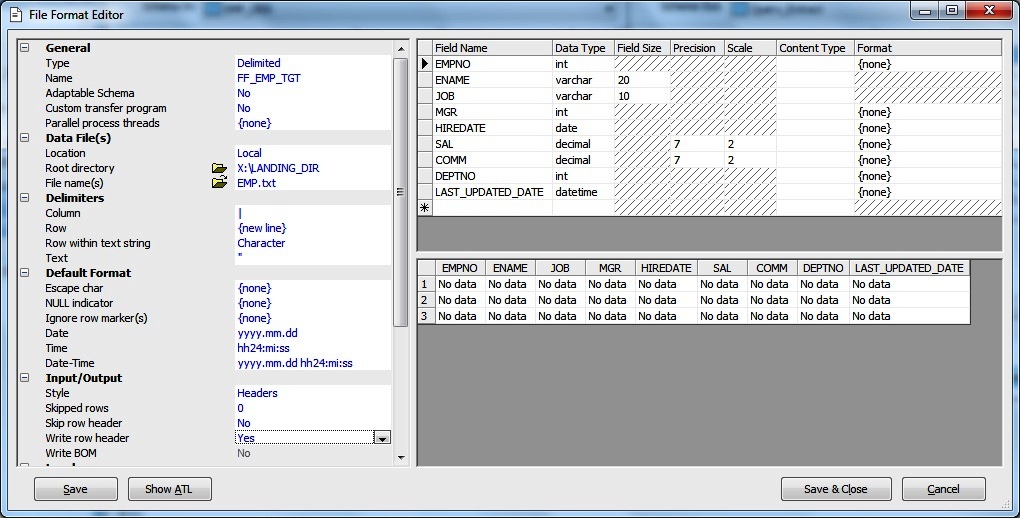
Next give a name to the File Format and Location and File Name and we are good to go.
Alternatively sometimes we want to copy the Source or Target Table Definition in an Excel Sheet for Analysis. So the simple way here is to select the Schema-Out of Source or Target definition name and right-click to select Create File Format.
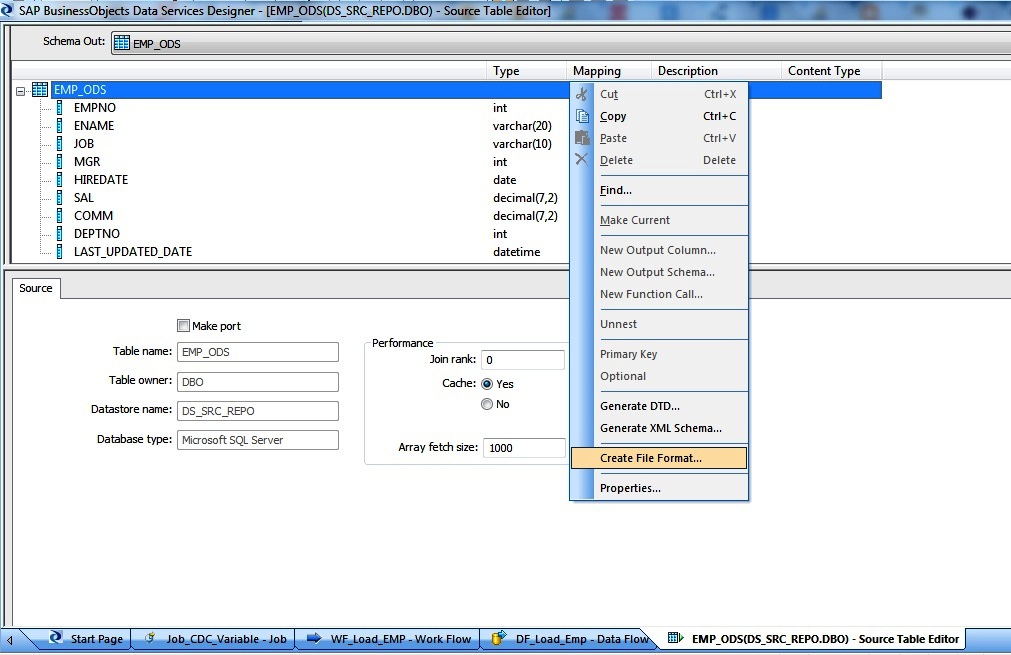
Next Double click at the square left of the Field Name or select the first row definition followed by Shift and select the last row definition to Select the Entire Content.
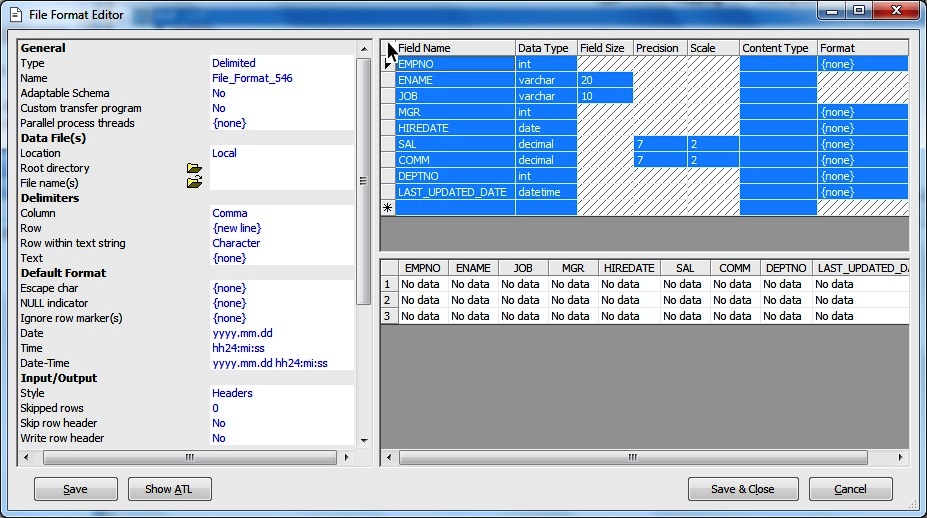
Next Simply COPY(Ctrl+C) and then in the Excel sheet PASTE(Ctrl+V) and we get the table metadata information in an Excel Sheet.
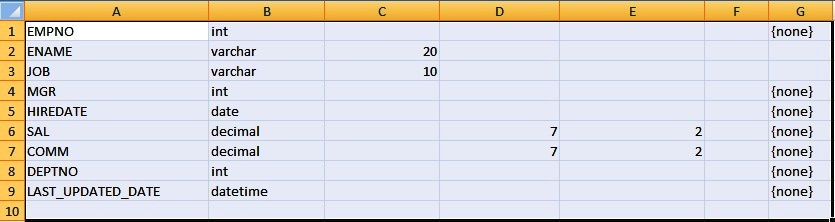
Again if we want to get the DDL script for a flat file of template table or source/target we can simply right click the Schema, click Create File Format. Next Click on Show ATL, from there we can copy the definition.
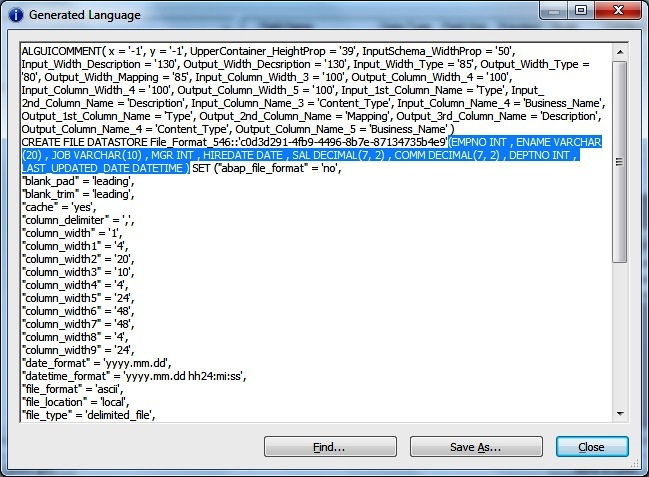
Many times we may need to replace the Data Services supported Data type to Native Database Data types.
NOTES- Adaptable Schema
Apart from the solid Error handling> capability and Custom Transfer feature of flat-file Format, the next best feature is the Adaptable Schema. An Adaptable Schema indicates whether the schema definition of a delimited file format is adaptable or fixed.
Suppose we receive two flat files having Employee information from two different locations. The only difference being that the first location provides an extra-column as the last field say EMP_TYPE with values say C2H/PERM when compared to the other employee location flat file. Also situation may arise that on a particular day it may not have the EMP_TYPE field as the last one.
So in order to handle this scenario where the file contains fewer or more columns than indicated by the file format we will define the File Format as Adaptable Schema. Define all the expected columns of the source file. If a row contains fewer columns than expected, Data Services loads null values into the columns missing data OR if a row contains more columns than expected, then it ignores the additional data.
