
DW Implementation Using PDI

Data integration is the process by which information from multiple databases is consolidated for use in a single application. ETL (extract, transform, and load) is the most common form of DI found in data warehousing. In this article we will look into the PDI architecture & product features which makes it a perfect ETL tool to fit in a typical DM/DW landscape. This article is meant primarily for Technical Architects, Consultants & Developers who are evaluating PDI capabilities.
Pentaho Data Integration (PDI) is a powerful extract, transform, and load (ETL) solution that uses an innovative metadata-driven approach. It includes an easy to use, graphical design environment for building ETL jobs and transformations, resulting in faster development, lower maintenance costs, interactive debugging, and simplified deployment.
Use Cases
Pentaho Data Integration is an extremely flexible tool that addresses a broad number of use cases including:
- Data warehouse population with built-in support for slowly changing dimensions and surrogate key creation.
- Data migration between different databases and applications.
- Loading huge data sets into databases taking full advantage of cloud, clustered and massively parallel processing environments.
- Data Cleansing with steps ranging from very simple to very complex transformations.
- Data Integration including the ability to leverage real-time ETL as a data source for Pentaho Reporting
- Rapid prototyping of ROLAP schemas during ETL build.
- Pentaho's technology agnostic design allows you to connect to many types of data sources including Hadoop. Use Pentaho's built-in shim layer to interface with Cloudera, Intel, MapR, Hortonworks, Cassandra, Splunk, Impala, MongoDB, DataStax, Hive and many others.
- Big data processing made using Hadoop job execution and scheduling, simple visual hadoop map/reduce design & Amazon EMR integration.

Pentaho Data Integration can be used in a wide variety of projects like- Data Integration & Downstream feed file generation, Data Migration (database & application), Data Profiling & Data Health Assessment, Data Assurance & Data Cleansing, Operational Datamart, Data warehouse, OLAP Datamart, Big Data Analytics.
Key Features
Pentaho Data Integration features and benefits include:
- Installs in minutes; you can be productive in one afternoon
- 100% Java with cross platform support for Windows, Linux and Macintosh
- Easy to use, graphical designer with over 200 out-of-the-box mapping objects including inputs, transforms, and outputs
- Simple plug-in architecture for adding your own custom extensions
- Enterprise Data Integration server providing security integration, scheduling, and robust content management including full revision history for jobs and transformations
- Integrated designer (Spoon) combining ETL with metadata modelling and data visualization, providing the perfect environment for rapidly developing new Business Intelligence solutions
- Streaming engine architecture provides the ability to work with extremely large data volumes
- Enterprise-class performance and scalability with a broad range of deployment options including dedicated, clustered, and/or cloud-based ETL servers
Architecture
Pentaho Data Integration (DI) components are comprised of a server, a design tool, command line utilities, and plugins that you can use to manipulate your data. DI Components are divided into four categories:
1. DI Server- Pentaho Server hosts Pentaho-created and user-created content. It is a core component for executing data integration transformations and jobs using the Pentaho Data Integration (PDI) Engine. It allows you to manage users and roles (default security) or integrate security to your existing security provider such as LDAP or Active Directory. Pentaho Server - comprises the core BA Platform (Analysis, Reporting, Metadata and ETL) packaged in a standard J2EE WAR along with supporting systems for thin-client tools including the Pentaho User Console, Analyzer, Interactive Reporting, Dashboards.
The primary functions of the Pentaho Server are:
- Execution- Executes ETL jobs and transformations using the Pentaho Data Integration engine
- Security- Allows you to manage users and roles (default security) or integrate security to your existing security provider such as LDAP or Active Directory
- Content Management- Provides a centralized repository that allows you to manage your ETL jobs and transformations. This includes full revision history on content and features such as sharing and locking for collaborative development environments.
- Scheduling & Monitoring- Provides the services allowing you to schedule and monitor activities on the Data Integration Server from within the Spoon design environment (Quartz).
2. Enterprise Repository- In addition to storing and managing your jobs and transformations, the Enterprise Repository provides full revision history for Transformations, Jobs allowing you to track changes, compare revisions and revert to previous versions when necessary. The repository has several predefined roles, with a set of specific rights.

3. Spoon is the design interface for building ETL jobs and transformations, and resides on your desktop. Spoon provides a drag and drop interface allowing you to graphically describe what you want to take place in your transformations which can then be executed locally within Spoon, on a dedicated Data Integration Server, or a cluster of servers. Drag job entries onto the Spoon canvas, or choose from a rich library of more than 200 pre-built steps to create a series of data integration processing instructions.
4. Command Line Utilities- You can use PDI's command line tools to execute PDI content from outside of Spoon. Typically, you would use these tools in the context of creating a script or a Cron job to run the job or transformation based on some condition outside of the realm of Pentaho software.
- Pan: A standalone command line process that can be used to execute PDI transformations which represent a data stream through a set of independent tasks you created in Spoon. The data transformation engine Pan reads data from and writes data to various data sources. Pan also allows you to manipulate data.
- Kitchen: A standalone command line process that can be used to execute jobs. The program that executes the jobs designed in the Spoon graphical interface, either in XML or in an enterprise/database repository. Jobs are usually scheduled to run in batch mode at regular intervals. Kitchen can orchestrate PDI jobs, which contain transformations and other job entries as part of a larger business process.
- Carte: is a lightweight Web container that allows you to set up a dedicated, remote PDI servers, so you can coordinate jobs across a collection of clustered computers, and execute transformations within a cluster of Carte cluster nodes. This provides similar remote execution capabilities as the Data Integration Server, but does not provide scheduling, security integration, and a content management system.
- Plugins- PDI has hundreds of plugins that can be accessed from the marketplace. But there are two plugins that are installed by default:
5. Instaview is software that allows you to use templates to manage the complexities of data access and preparation. Instaview automatically generates transform and metadata models, executes them, and allows you to visualize the results.
6. Agile BI is an accelerated development approach, which links Spoon’s data integration to Analyzer and its visualizations. You can immediately see analyzed results as you change your data mart or data models, without leaving Spoon. This technique helps data design professionals and business users work together to rapidly resolve business analysis concerns.
The diagram below depicts the core components of PDI Client & Enterprise Server.

Transformation & Job
The Data Integration perspective of Spoon allows you to create two basic document types: transformations and jobs.
Transformations are used to describe the data flows for ETL such as reading from a source, transforming data and loading it into a target location. They are comprised of Steps, which provide you with a wide range of functionality ranging from reading text-files to implementing slowly changing dimensions. Hops help you define the flow of the data in the stream. They represent a row buffer between the Step Output and the next Step Input. A hop connects one transformation step or job entry with another. The direction of the data flow is indicated by an arrow.
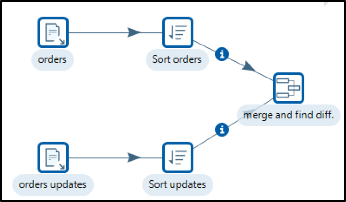
In addition to Steps and Hops, Notes enable you to document the Transformation.
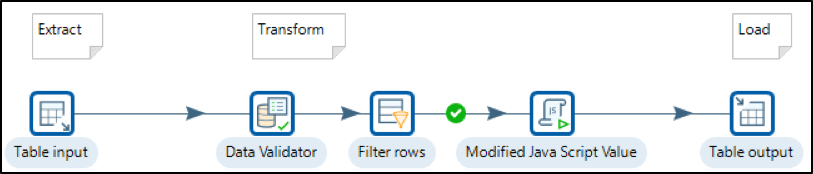
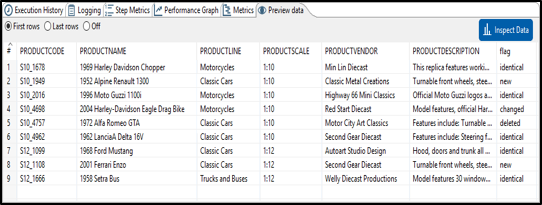
The designer also provides runtime Data Preview, Logging, Execution History & Performance metrics.
Jobs are used to coordinate ETL activities such as defining the flow and dependencies for what order transformations should be run, or prepare for execution by checking conditions such as, "Is my source file available?" or "Does a table exist in my database?"

In the next continued article we will check out the transformation steps used frequently in a typical DW Implementation project.
