
Query S3 Data Using Amazon Athena

Amazon Athena is serverless interactive query service that makes it easy to analyze large-scale datasets in Amazon S3 using standard SQL. Athena is easy to use. Simply point to your data in Amazon S3, define the schema, and start querying using standard SQL.
First of all let's create a Workgoup. It is used to separate users, teams, applications, workloads, and also to set limits on amount of data for each query or the entire workgroup process.
Go to the Workgroups page & Click on Create Workgroup.

Provide a name & description for your workgroup.
- Workgroup name: bigdata-wg
- Description: Bigdata Analysis TPCH Workgroup

Next Click on Browse S3 button, to choose your S3 Bucket to store the Athena Query Results. Optionally you may choose to Encrypt the query results.
Select Query engine version. You may choose Automatic.

Optionally on the Settings section, you may choose to select the various settings like Publish query metrics to AWS Cloudwatch etc.
Optionally on the Per query data usage control section, you may set Data limits to restrict the maximum amount of data a query is allowed to scan for the workgroup.

Optionally on the Workgroup data usage alerts section, you may set CloudWatch alarms to alert thresholds, when queries running in this workgroup scan a specified amount of data within a specific period.
Optionally set your preferred key/value pair Tags.Finally click the Create workgroup button.
Now on the Workgroups listing page, Select your Workgroup. Next click on the Actions button & select Switch workgroup.

Now our bigdata-wg is the Current Workgroup.

Next go to the Query editor page.
First of all let us create a database.

-- Database
CREATE DATABASE bigdatagen;Next we will create an external table based on pipe delimited data files stored in S3 bucket.
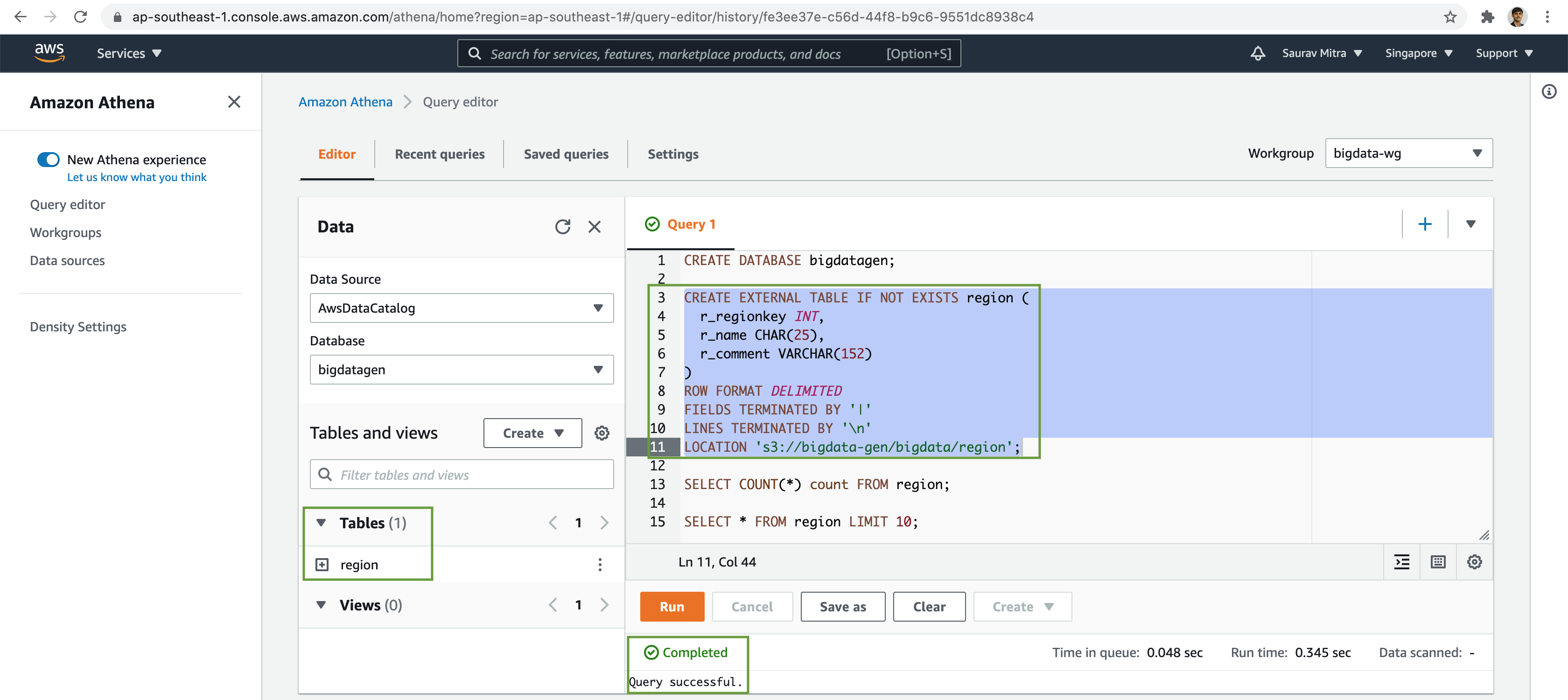
-- Region Table
CREATE EXTERNAL TABLE IF NOT EXISTS region (
r_regionkey INT,
r_name CHAR(25),
r_comment VARCHAR(152)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LINES TERMINATED BY '\n'
LOCATION 's3://bigdata-gen/bigdata/region/';Let's query the number of records in the external table.

-- Region Table Record Count
SELECT count(*) count FROM region;Finally, lets preview the data in the external table.
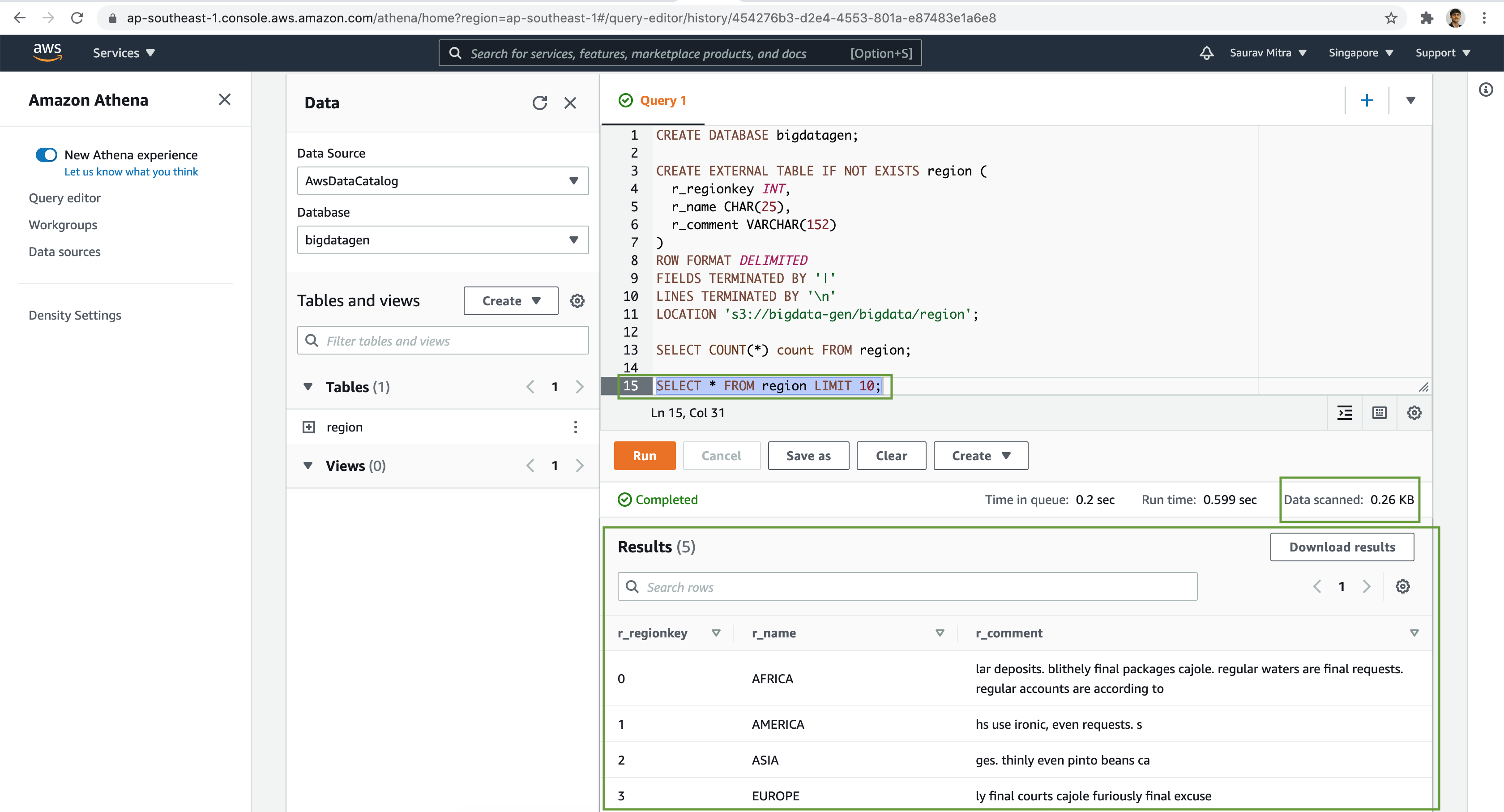
-- Region Table Preview
SELECT * FROM region LIMIT 10;Similarly, we will create few more tables and analyze the data stored in S3 buckets with our favourite SQL based queries.

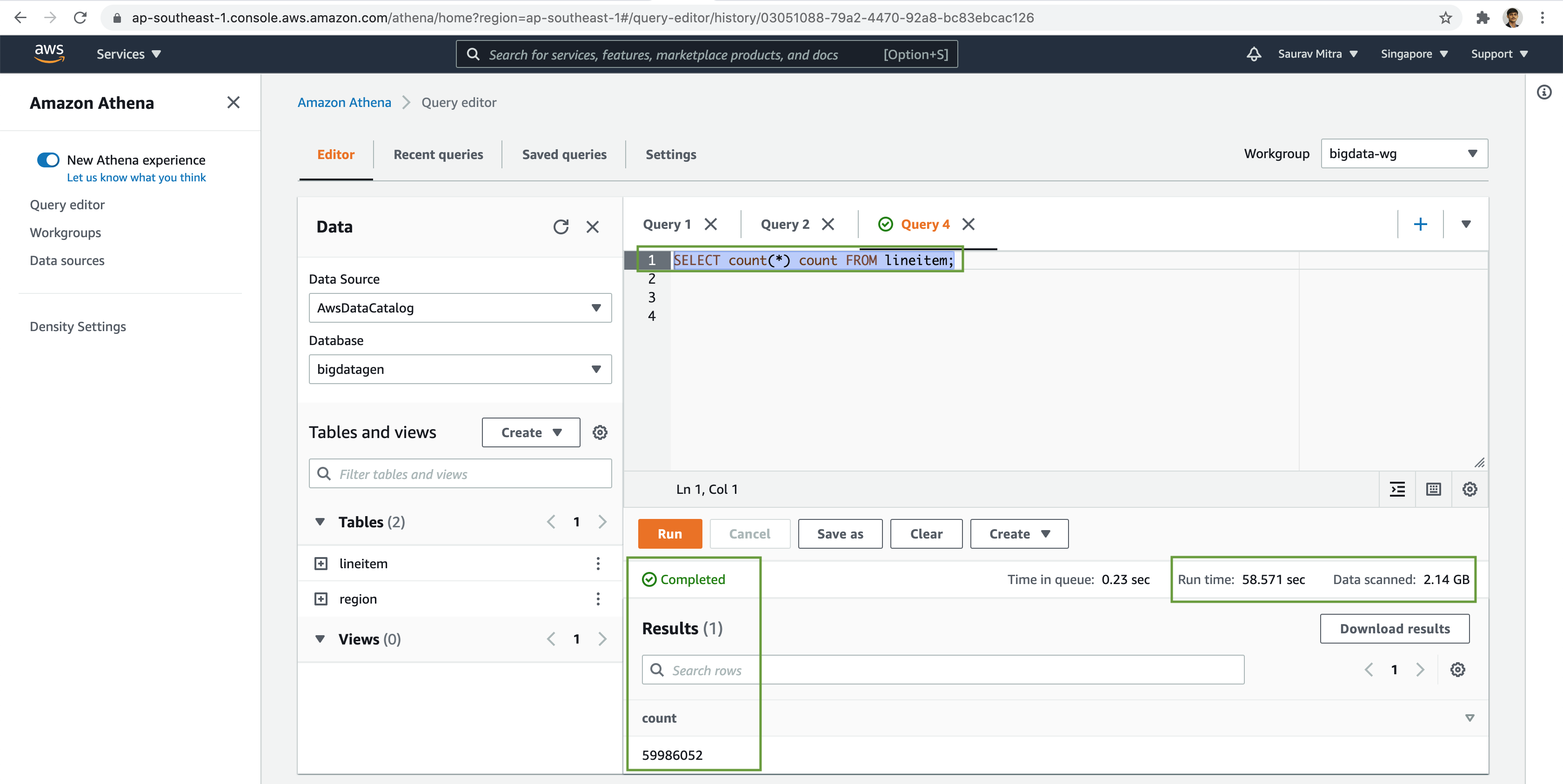

Try to further analyze the data with various complex SQL queries using Joins, Group By etc on our external tables.
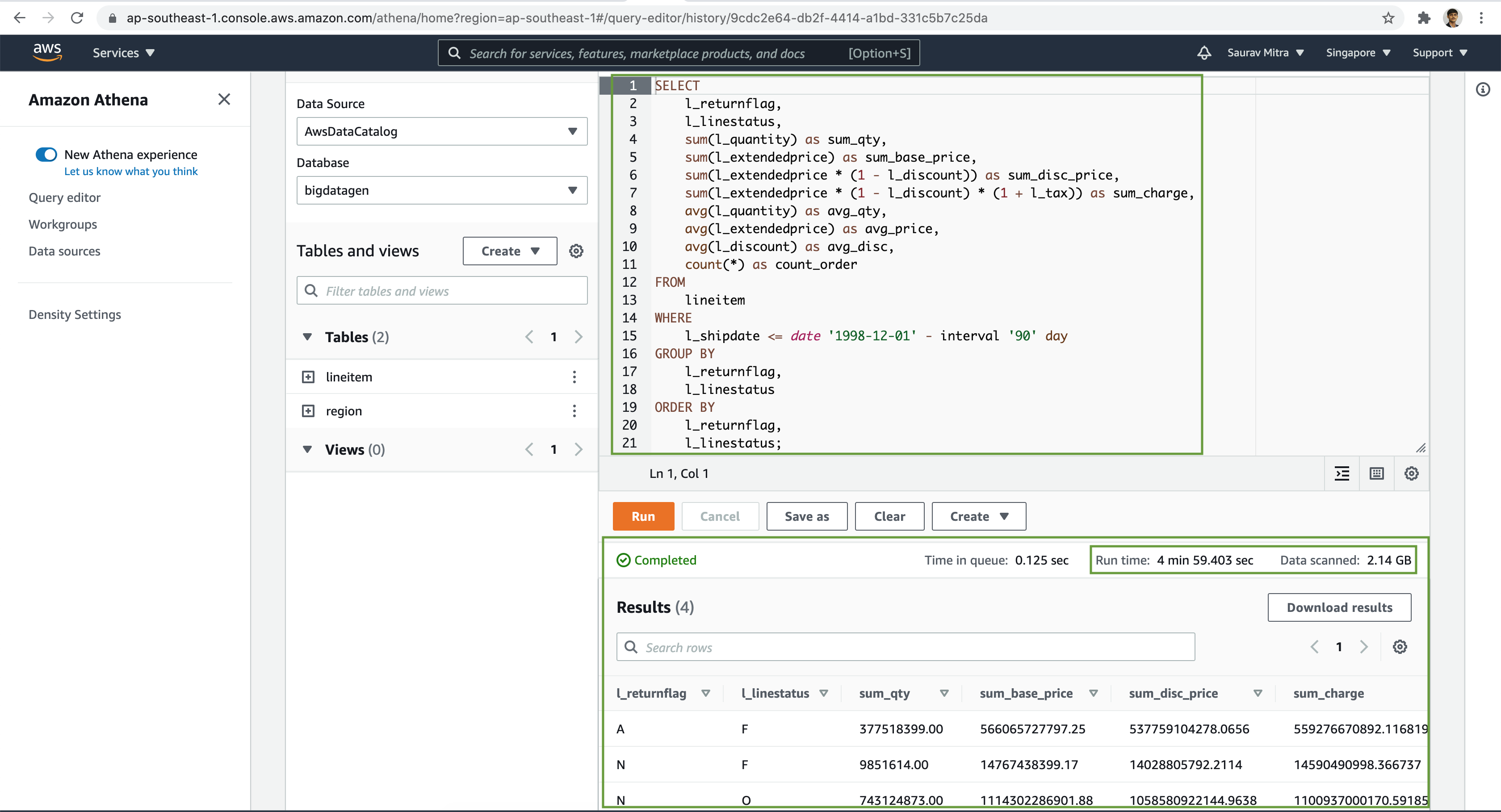
Also take note on the Run time & the Data scanned.
You may download the sample DDL & DQL from here to try at your end.
Athena has integration with AWS Glue Data Catalog, which offers a persistent metadata store for our data stored in Amazon S3. This allows us to create tables and query data in Athena based on a central metadata store.

Within the Data catalog are the Glue Metadata Tables.
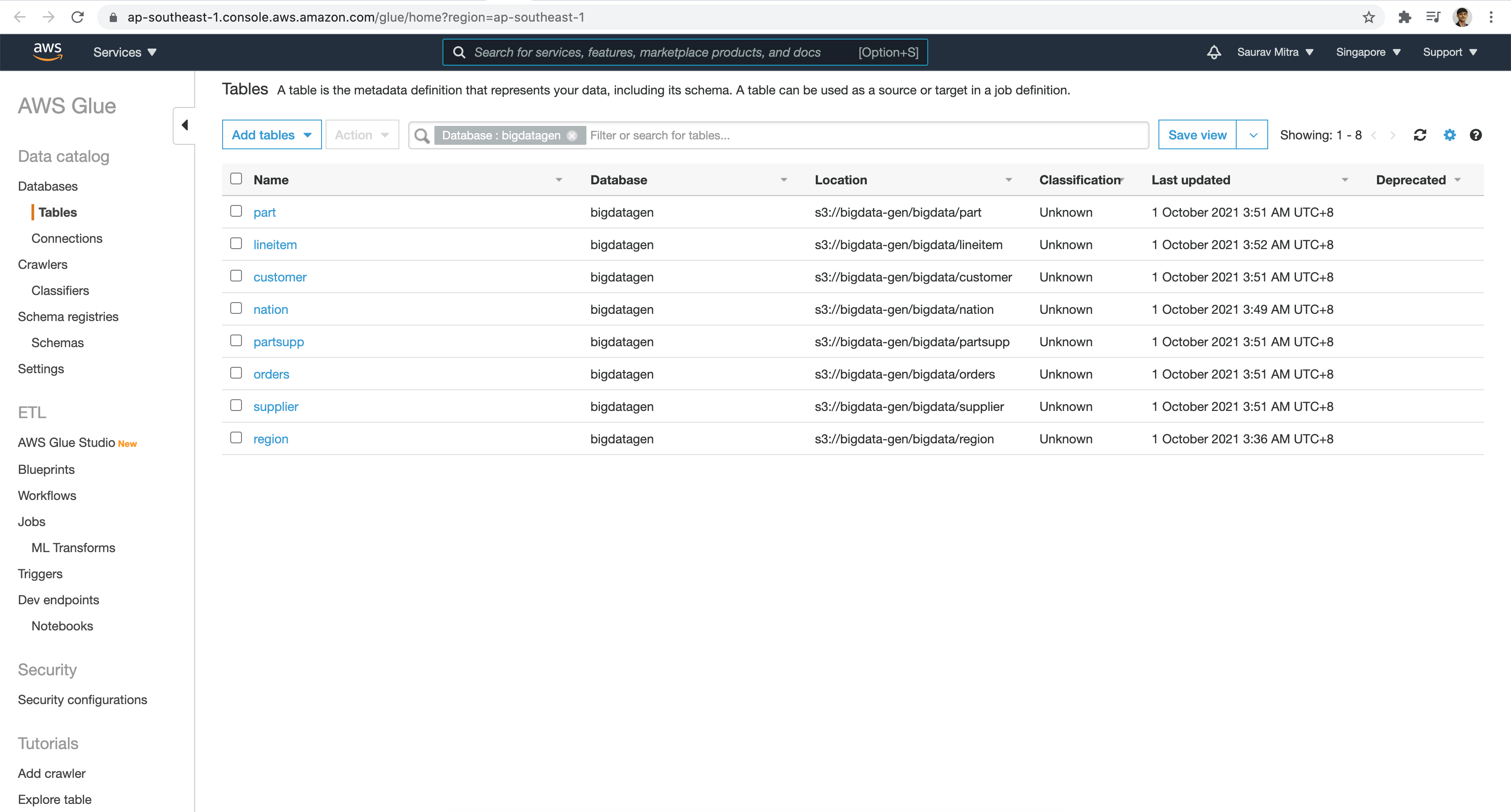
The table schema definition in Glue.

