
Common Mistakes in Data Modelling

A model is an abstraction of some aspect of a problem. A data model is a model that describes how data is represented and accessed, usually for a database. The construction of a data model is one of the most difficult tasks of software engineering and is often pivotal to the success or failure of a project.
There are too many factors that determine the success of a data model in terms of its usability and effectiveness. Not all of them can be discussed here. Plus people tend to make different types of mistakes for different types of modelling patterns. Some modelling patterns are prone to some specific types of issues which might not be prevalent is other types of patterns. Nevertheless, I have tried to compile a list of some widespread mistakes that are commonly found in data modelling patterns.
Avoid Large Data Models
Well, you may be questioning how much large is large. The answer: it depends. You must ask yourself if the large size of the model is really justified. The more complex your model is, the more prone it is to contain design errors. For an example, you may want to try to limit your models to not more than 200 tables. To be able to do that, in the early phase of data modelling ask yourself these questions –
- Is the large size really justified?
- Is there any extraneous content that I can remove?
- Can I shift the representation and make the model more concise?
- How much work is to develop the application for this model and is that worthwhile?
- Is there any speculative content that I can remove? (Speculative contents are those which are not immediately required but still kept in the model as “might be required” in the future.)
If you consciously try to keep things simple, most likely you will also be able to avoid the menace of over modelling. Over modelling leads to over engineering which leads to over work without any defined purpose. A person who does modelling just for the sake of modelling often ends up doing over modelling.
Watch carefully if you have following signs in your data model?
- Lots of entities with no or very few non-key attributes?
- Lots of modelling objects with names which no business user would recognize?
- You yourself have lot of troubles coming up with the names of the attributes?
All the above are sure signs of over modelling that only increases your burden (of coding, of loading, of maintaining, of securing, of using).
Lack of Clarity or Purpose
Purpose of the model determines the level of details that you want to keep in the model. If you are unsure about the purpose, you will definitely end up designing a model that is too detail or too brief for the purpose.
Clarity is also very important. For example - do you clearly know the data types that you should be using for all the business attributes? Or do you end up using some speculative data types (and lengths)?
Modern data modelling tools come with different concepts of declaring data (e.g. domain and enumeration concept in ERWin) that helps to bring clarity to the model. So, before you start building – pause for a moment and ask yourself if you really understand the purpose of the model.
Reckless violation of Normal Form
This section is only applicable for operational data models
When the tables in the model satisfy higher levels of normal forms, they are less likely to store redundant or contradictory data. But there is no hard and fast rule about maintaining those normal forms. A modeler is allowed to violate these rules for good purpose (such as to increase performance) and such a relaxation is called denormalization.
But the problem occurs – when a modeler violates the normal form deliberately without a clearly defined purpose. Such reckless violation breaks apart the whole design principle behind the data model and often renders the model unusable. So if you are unsure of something – just stick to the rules. Don’t get driven by vague purposes.
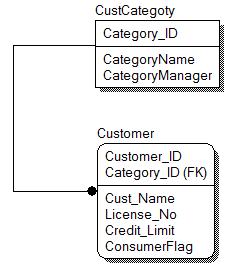
The above figure shows a general hierarchical relationship between customer and its related categories. Let’s say a customer can fall under following categories – Consumer, Business, Corporate and Wholesaler. Given this condition, “ConsumerFlag” is a redundant column on Customer table.
Traps in Dimensional Modelling
When it comes to dimensional modelling, there are some inexcusable mistakes that people tends to make. Here are a few of them –
Snow-flaking between two Type-II slowly changing dimension (SCD) tables
Below is an example of such a modelling.

Theoretically speaking there is no issue with such a model, at least until one tries to create the ETL programming (extraction-transformation-loading) code behind these tables.
Consider this – in the above example, suppose something changed in the “ProductType” table which created a new row in “ProductType” table (since ProductType is SCD2, any historical change will be maintained by adding new row). This new row will have new surrogate key. But in the Product table, any existing row is still pointing to the old product type record and hence leading to data anomaly.
Indiscriminate use of Surrogate keys
Surrogate Keys are used as a unique identifier to represent an entity in the modeled world. Surrogate keys are required when we cannot use a natural key to uniquely identify a record or when using a surrogate key is deemed more suitable as the natural key is not a good fir for primary key (natural key too long, data type not suitable for indexing etc.)
But surrogate keys also come with some disadvantages. The values of surrogate keys have no relationship with the real world meaning of the data held in a row. Therefore over usage of surrogate keys (often in the name of “standardization”) lead to the problem of disassociation and creates unnecessary ETL burden and performance degradation.
Even query optimization becomes difficult when one disassociates the surrogate key with the natural key. The reason being – since surrogate key takes the place of primary key, unique index is applied on that column. And any query based on natural key identifier leads to full table scan as that query cannot take the advantage of unique index on the surrogate key.
Before assigning a surrogate key to a table, ask yourself these questions –
- Am I using a surrogate key only for the sake of maintaining standard?
- Is there any unique not null natural key that I can use as primary key instead of a new surrogate key?
- Can I use my natural key as primary key without degrading the performance?
If the answer of the above questions are ‘YES’ – do yourself a favour. Don’t use the surrogate key.
