
SSIS- Aggregate Transform

This is a Fast Forward tutorial on Aggregate Transformation in Microsoft SQL Server Integration Services.
Aggregate Transformation
The Aggregate transformation is used to perform aggregate operations/functions on groups in a dataset. The aggregate functions available are- Count, Count Distinct, Sum, Average, Minimum and Maximum. The Aggregate transformation has one input and one or more outputs. It does not support an error output.
Implementation
Here in this example we want to get the sum of the salary for each departments based on the employee data. We want to perform database equivalent of SUM(SAL) GROUP BY DEPTNO operation.
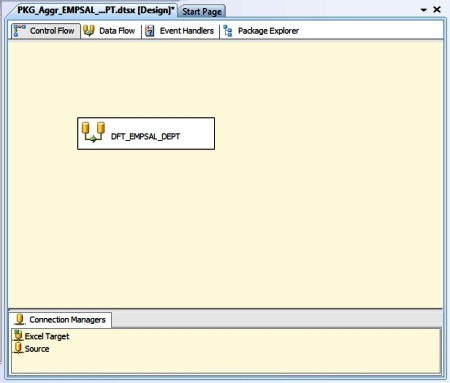
Here, we have EMP table as OLEDB Source. Next we use an Aggregate transform followed by Excel Destination.
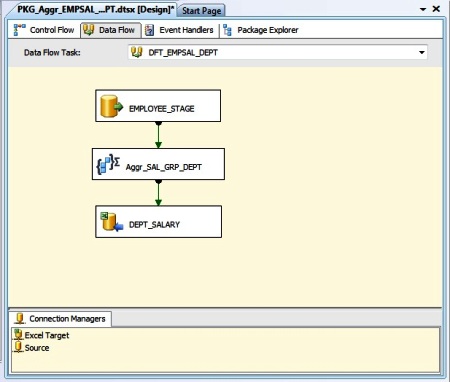
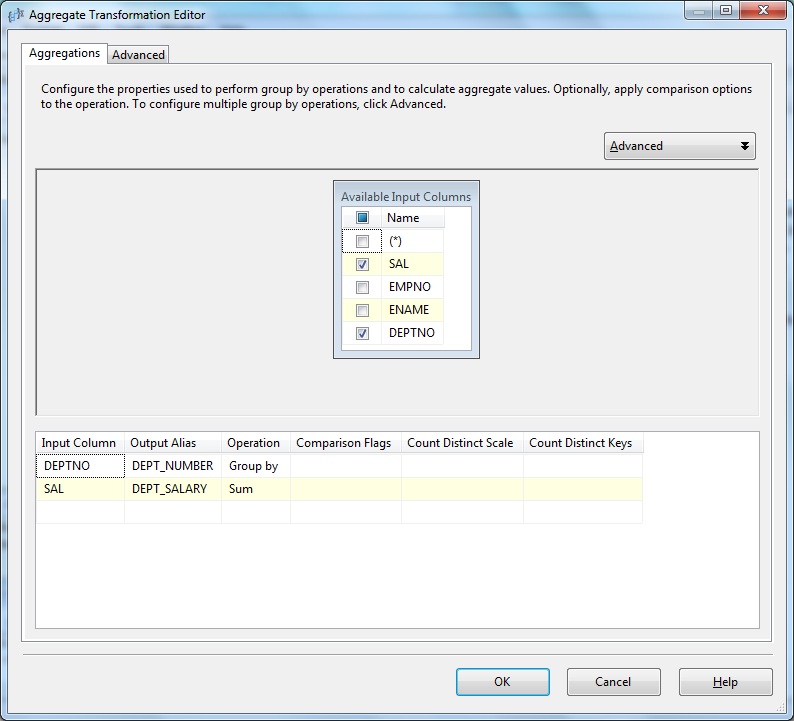
Double-click the Aggregate transform to open the editor. Next in the lower pane we select the Input Column, set Output Alias to columns, select the Operation i.e. Group By clause or any aggregate functions as below:
Below Aggregate Transformation Editor- Advanced
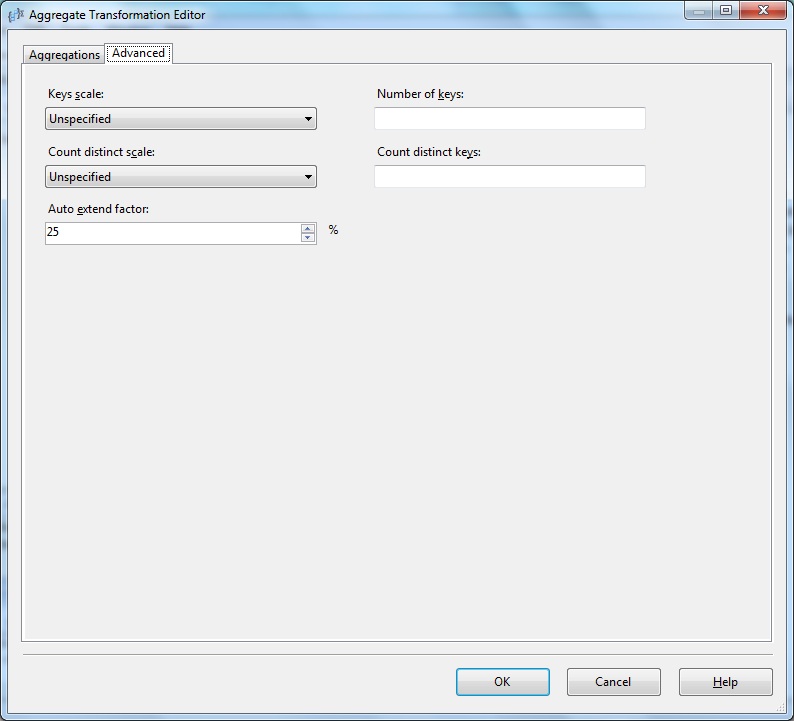
Let's explore the Advanced Editor properties.
Below Aggregate Transform Advanced Editor- Input Columns
Below Aggregate Transform Advanced Editor- Input & Output Properties
Next we take a look into the Excel Destination object. Double-click to open the editor. Select the connection object from OLEDB Connection Manager browser. Select Data access mode to table or view and set the Name of the Excel sheet.
Next we go to the Mapping tab and map the Input to Destination columns.
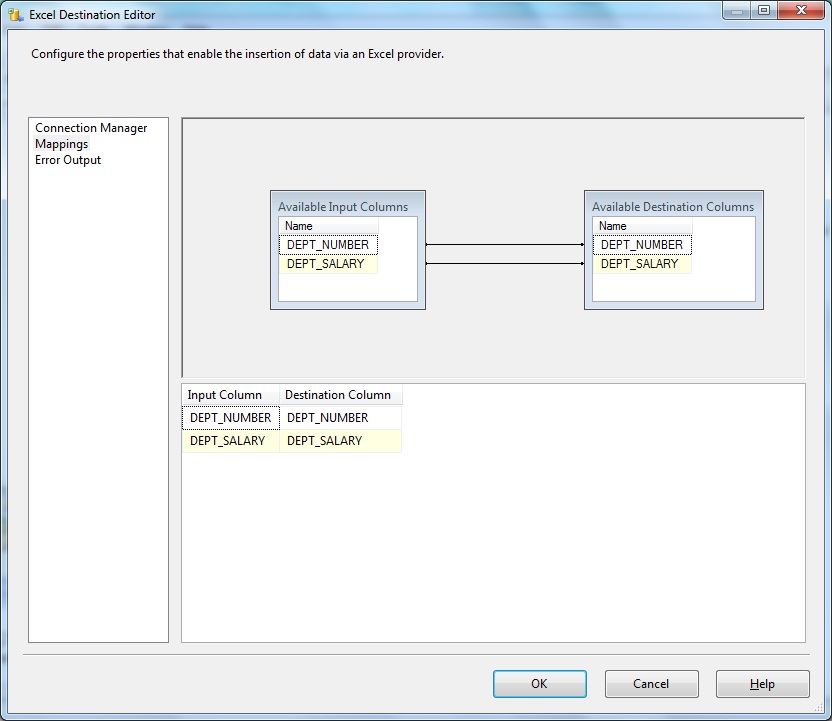
Below Excel Destination Editor- Error Output
Let's take a look into the Advanced Editor of Excel Destination.
Below Excel Destination Advanced Editor- Component Properties
Below Excel Destination Advanced Editor- Column Mappings
Below Excel Destination Advanced Editor- Input & Output Properties
Aggregate transform aggregates and groups values in a dataset. This transformation does not pass through any columns, but creates new columns in the data flow for the data it publishes. Only the input columns to which aggregate functions apply or the input columns the transformation uses for grouping are copied to the transformation output.
NULL Handling
The Aggregate transformation handles null values in the same way as any ANSI compliant database.
- In a GROUP BY clause, nulls are treated like other column values. If the grouping column contains more than one null value, the null values are put into a single group.
- In the COUNT (column name) and COUNT (DISTINCT column name) functions, nulls are ignored and the result excludes rows that contain null values in the column.
- In the COUNT (*) function, all rows are counted, including rows with null values.
We will discuss more about the Performance considerations while working with Aggregate transformation in another article. We will discuss on the properties like- Comparison Flags, Count Distinct Scale, Count Distinct Keys, Keys scale, Number of keys, Count distinct scale, Count distinct keys, Auto extend factor etc. Stay tuned...
