
A road-map on Testing in Data Warehouse

Updated on Sep 29, 2020
Testing in data warehouse projects are till date a less explored area. However, if not done properly, this can be a major reason for data warehousing project failures - especially in user acceptance phase. Given here a mind-map that will help a project manager to think all the aspects of testing in data warehousing.
Testing Mindmap
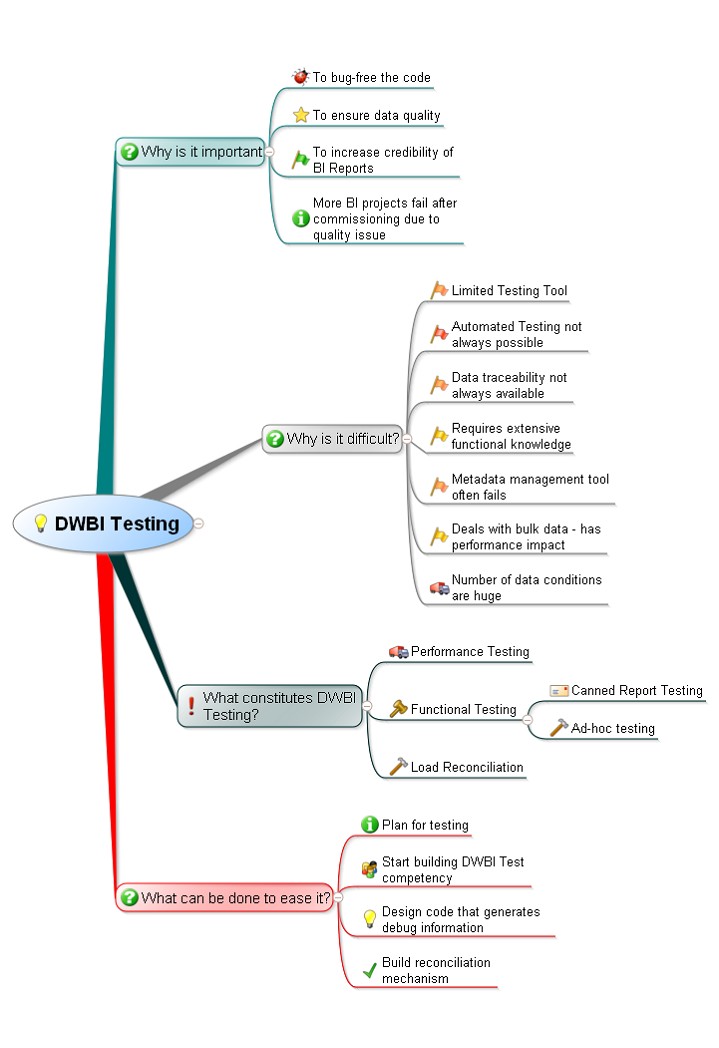
Points to consider for DWBI Testing
Why is it important?
- To bug-free the code
- To ensure data quality
- To increase credibility of BI Reports
- More BI projects fail after commissioning due to quality issue
What constitutes DWBI Testing?
- Performance Testing
- Functional Testing
- Canned Report Testing
- Ad-hoc Testing
- Load Reconciliation
What can be done to ease it?
- Plan for testing
- Start building DWBI Test competency
- Design code that generates debug information
- Build reconciliation mechanism
Why is it difficult?
- Limited Testing Tool
- Automated Testing not always possible
- Data traceability not always available
- Requires extensive functional knowledge
- Metadata management tool often fails
- Deals with bulk data - has performance impact
- Number of data conditions are huge
Use the above mind-map to plan and prepare the testing activity for your data warehousing project.
