
PDI Transformation Steps

As a continuation of the previous article, let us check some of the key PDI Steps. Below are few examples of in-built PDI transformation steps used widely in a DI/DW/DM landscape.
Input Steps
- CSV Input step provides the ability to read data from a delimited file. The CSV label for this step is a misnomer because you can define whatever separator you want to use, such as pipes, tabs, and semicolons; you are not constrained to using commas. Internal processing allows this step to process data quickly. Options for this step are a subset of the Text File Input step.
- Text File Input step is used to read data from a variety of different text-file types. The most commonly used formats include Comma Separated Values (CSV files) generated by spreadsheets and fixed width flat files. The Text File Input step provides you with the ability to specify a list of files to read, or a list of directories with wild cards in the form of regular expressions. In addition, you can accept filenames from a previous step making filename handling more even more generic.
- Fixed File Input step is used to read data from a fixed-width text file, exclusively. In fixed-width files, the format is specified by column widths, padding, and alignment. Column widths are measured in units of characters.
- Microsoft Excel Input step provides you with the ability to read data from one or more Excel and OpenOffice files.
- Data Grid step allows you to enter a static list of rows in a grid. This is usually done for testing, reference or demo purposes.
Meta tab: on this tab, you can specify the field metadata (output specification) of the data
Data tab: This grid contains the data. Everything is entered in String format so make sure you use the correct format masks in the metadata tab.
- Table Input step is used to read information from a database, using a connection and SQL. Basic SQL statements can be generated automatically by clicking Get SQL select statement.
- Get data from XML step provides the ability to read data from any type of XML file using XPath specifications. An XML file is parsed via an X-path to retrieve the required dataset. The XML Input Stream (StAX) step that uses a completely different approach to solve use cases with very big and complex data structures and the need for very fast data loads.
- JSON Input step extracts relevant portions out of JSON structures, files or incoming fields, and outputs rows.
- RSS Input step imports data from an RSS or Atom feed. RSS versions 0.91, 0.92, 1.0, 2.0, and Atom versions 0.3 and 1.0 are supported. RSS (Rich Site Summary; originally RDF Site Summary; often called Really Simple Syndication) uses a family of standard web feed formats to publish frequently updated information: blog entries, news headlines, audio and video.
- REST Client step enables you to consume RESTfull services. Representational State Transfer (REST) is a key design idiom that embraces a stateless client-server architecture in which the web services are viewed as resources and can be identified by their URLs.
- Generate Rows step outputs a specified number of rows. By default, the rows are empty; however they can contain a number of static fields. Sometimes you may use Generate Rows to generate one row that is an initiating point for your transformation.
Transformation Steps
- Select Values step is useful for selecting, removing, renaming, changing data types and configuring the length and precision of the fields on the stream. These operations are organized into different categories:
Select and Alter — Specify the exact order and name in which the fields should be placed in the output rows
Remove — Specify the fields that should be removed from the output rows
Meta-data - Change the name, type, length and precision (the metadata) of one or more fields
- Filter Rows step allows you to filter rows based on conditions and comparisons.
- Switch Case step implements the Switch/Case statement found in popular programming languages like Java.
- Calculator step provides you with predefined functions that can be executed on input field values. Besides the arguments (Field A, Field B and Field C) you must also specify the return type of the function. You can also choose to remove the field from the result (output) after all values are calculated; this is useful for removing temporary values.
- Sort rows step sorts rows based on the fields you specify and on whether they should be sorted in ascending or descending order.
- Group By step allows you to calculate values over a defined group of fields. Examples of common use cases are: calculate the total or average sales by product or by year.
- Analytic Query step allows you to ‘scroll’ forward and backwards across rows. Examples of common use cases are:
Calculates the "time between orders" by ordering rows by Customername, and LAGing 1 row back to get previous order time.
Calculates the "duration" of a web page view by LEADing 1 row ahead and determining how many seconds the user was on this page.
- Merge Join step performs a classic merge join between data sets with data coming from two different input steps. Join options include INNER, LEFT OUTER, RIGHT OUTER, and FULL OUTER. In this step rows are expected in to be sorted on the specified key fields. When using the Sort step, this works fine.
- Database Join step allows you to run a query against a database using data obtained from previous steps.
- Database lookup step allows you to look up values in a database table. Lookup values are added as new fields onto the stream.
- Stream Value Lookup step type allows you to look up data using information coming from other steps in the transformation. The data coming from the Source step is first read into memory and is then used to look up data from the main stream.
- Merge rows (diff) step allows you to compare two streams of rows. This is useful for comparing data from two different times. It is often used in situations where the source system of a data warehouse does not contain a date of last update.
The two sets of records, an original stream (the existing data) and the new stream (the new data), are compared and merged. Only the last version of a record is passed to the next steps each time. The row is marked as follows:
"identical" - The key was found in both streams and the values in both fields are identical;
"changed" - The key was found in both streams but one or more values are different;
"new" - The key was not found in the original stream;
"deleted" - The key was not found in the new stream.
The records coming from the new stream are passed on to the next steps, except when it is "deleted".
Both streams must be sorted on the specified key(s). If the Merge rows (diff) step is used in conjunction with the Synchronize after merge, then based on the value of the flag, the database can be updated.
- Synchronize after merge step can be used in conjunction with the Merge Rows (diff) transformation step. The Merge Rows (diff) transformation step appends a Flag column to each row, with a value of "identical", "changed", "new" or "deleted". This flag column is then used by the Synchronize after merge transformation step to carry out updates/inserts/deletes on a connection table. This step uses the flag value to perform the sync operations on the database table.
- Data validation is typically used to make sure that incoming data has a certain quality. Validation can occur for various reasons, for example if you suspect the incoming data doesn't have good quality or simply because you have a certain SLA in place. The Data Validator step allows you to define simple rules to describe what the data in a field should look like. This can be a value range, a distinct list of values or data lengths. This step allows for an unlimited amount of validation rules to be applied in a single step on the incoming data.
- Flattener step allows you flatten data sequentially into records. This step enables you to define new target fields that match the number of repeating records.
- RegEx Evaluation step type allows you to match the String value of an input field against a text pattern defined by a regular expression. Optionally, you can use the regular expression step to extract substrings from the input text field matching a portion of the text pattern into new output fields. This is known as "capturing".
- Replace in string is a simple search and replace. It also supports regular expressions and group references. Group references are picked up in the replace by string as $n where n is the number of the group.
- Get System Info step retrieves information from the Kettle environment. This step generates a single row with the fields containing the requested information. It also accepts input rows. The selected values are added to the rows found in the input stream(s). E.g. Get information from the operating system such as command-line arguments and system date.
- User Defined Java Expression step allows you to enter User Defined Java Expressions as a basis for the calculation of new values.
- Append step type allows you to order the rows of two inputs hops. First, all the rows of the "Head hop" will be read and output, after that all the rows of the "Tail hop" will be written to the output. If more than 2 hops need to be used, you can use multiple append steps in sequence.
- Block until Step Finish step simply waits until all the step copies that are specified in the dialog have finished. You can use it to avoid the natural concurrency (parallelism) that exists between transformation step copies.
- Formula step can calculate Formula Expressions within a data stream. It can be used to create simple calculations like [A]+[B] or more complex business logic with a lot of nested if / then logic.
- Modified JavaScript Value step is a modified version of the 'JavaScript Values' step that provides better performance and an easier, expression based user interface for building JavaScript expressions. This step also allows you to create multiple scripts for each step.
- ETL Metadata Injection step inserts metadata into a template transformation. Instead of statically entering ETL metadata in a step dialog, you pass it at run-time. This step enables you to solve repetitive ETL workloads for example; loading of text files, data migration, and so on.
The Dummy step does not do anything. Its primary function is to be a placeholder for testing purposes.
Output Steps
- Text file output step is used to export data to text file format. This is commonly used to generate Comma Separated Values (CSV files) that can be read by spreadsheet applications. It is also possible to generate fixed width files by setting lengths on the fields in the fields tab. It is not possible to execute this step in parallel to write to the same file. In this case, you need to set the option "Include stepnr in filename" and later merge the files.
- Microsoft Excel Writer step writes incoming rows into an MS Excel file. It supports both the xls and xlsx file formats. The xlsx format is usually a good choice when working with template files, as it is more likely to preserve charts and other miscellaneous objects in the output. The proprietary (binary) xls format is not as well understood and deciphered, so moving/replicating nontrivial xls content in non-Microsoft software environments is usually problematic.
- Table Output step allows you to load data into a database table. Table Output is equivalent to the DML operator INSERT. This step provides configuration options for target table and a lot of housekeeping and/or performance-related options such as Commit Size and Use batch update for inserts.
- Insert/Update step first looks up a row in a table using one or more lookup keys. If the row can't be found, it inserts the row. If it can be found and the fields to update are the same, nothing is done. If they are not all the same, the row in the table is updated.
- Update step first looks up a row in a table using one or more lookup keys. If it can be found and the fields to update are all the same, no action is taken, otherwise the record is updated.
- Dimension Lookup/Update step allows you to implement Ralph Kimball's slowly changing dimension for both types: Type I (update) and Type II (insert) together with some additional functions. Not only can you use this step to update a dimension table, it may also be used to look up values in a dimension. There are several options available to insert / update the dimension record (row).
Insert: This option implements a Type II slowly changing dimension policy. If the difference is detected for one or more mappings that have the Insert option, then a row is added to the dimension table.
Update: This option simply updates the matched row. It can be used to implement a Type I slowly changing dimension.
Punch through: The punch through option also performs an update. But instead of only updating the matched dimension row, it will update all versions of the row in a Type II slowly changing dimension.
Date of last insert or update (without stream field as source): Use this option to let the step automatically maintain a date field that records the date of the insert or update using the system date field as source.
Date of last insert (without stream field as source): Use this option to let the step automatically maintain a date field that records the date of the last insert using the system date field as source.
Date of last update (without stream field as source): Use this option to let the step automatically maintain a date field that records the date of the last update using the system date field as source.
Last version (without stream field as source): Use this option to let the step automatically maintain a flag that indicates if the row is the last version.
- Delete step deletes records matching the given condition.
- Bulk Loading steps supports bulk loading to various databases and appliances like MySQL, Oracle, Ingres, MonetDB, PostgreSQL, Infobright, Greenplum, SAP HANA, Teradata, Vertica, Elastic search & MongoDB.
Supported Databases
Pentaho Data Integration supports a wide range of relational databases as source or target using JDBC. Pentaho software generates dialect-specific SQL when communicating with these data sources. Below is the comprehensive list:
<b>Amazon Redshift</b>, Apache Derby, <b>AS/400</b>, InfiniDB, Exasol 4, Firebird SQL, <b>Greenplum</b>, H2, <b>Hive</b>, Hypersonic, <b>IBM DB2</b>, <b>Impala</b>, Infobright, Informix, Ingres, Ingres VectorWise, LucidDB, MaxDB (SAP DB), MonetDB, <b>MS SQL Server</b>, <b>MySQL</b>, Neoview, <b>Netezza</b>, <b>Oracle</b>, <b>PostgreSQL</b>, <b>SAP HANA</b>, SQLite, <b>Teradata</b>, UniVerse database, <b>Vertica</b>, Other SQL-92 compliant databases.
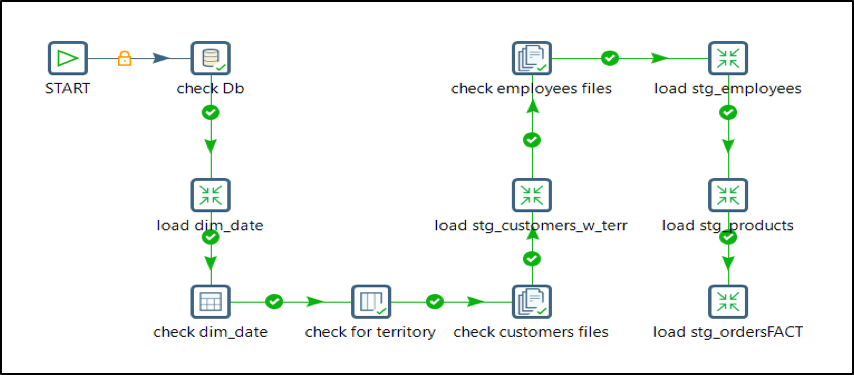
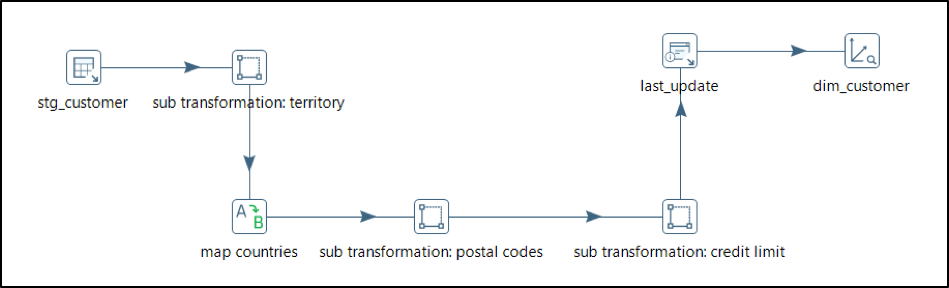
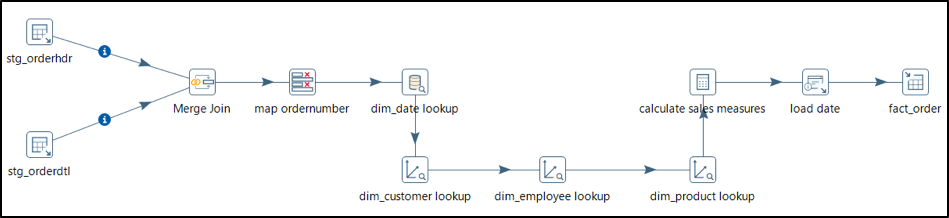
Typical Jobs & Transformations used in DW/DM
Below are some screen shots of the jobs and transformations used in a typical data warehouse implementation like fact & dimension table loading, support for slowly changing dimensions, snapshot & incident facts, late arriving and junk dimensions.
<img src="images/pdi/pdi_dw_11.png" alt="pdi_dw_11"/ class="myimage">
